1 min read
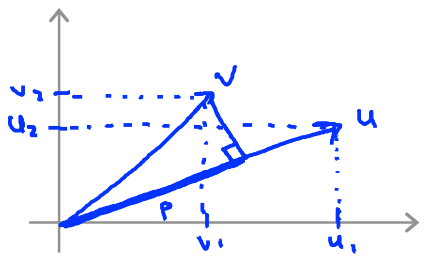
벡터 u 와 v 가 존재한다고 가정할때, 내적 u⋅v 은 v 에서 u 로 내린 projection p 의 길이와 u 의 크기 ∣∣u∣∣ 값을 곱한것과 같다.
B.1.1.1) Why Scaled? dₖ 가 커질수록 dot products 의 값이 커지기 때문에 softmax 에서 gradient 값이 매우 작아지게 된다. 이러한 현상을 막기 위해서 scale 값을 적용했다고 한다. B.1.1.2) Example Fig...
Cauchy–Schwarz Inequality 만약, 두 벡터가 서로 선형 독립 하지 않다면, 위 식의 양쪽은 서로 같다. Related References
Chain Rule (calculus) Scalar case y=g(x) 그리고 z=f(g(x))=f(y) 인 경우 chain rule 은 다음과 같다. Vector case 위 식은 Jacobian matrix 로 표현이 가능하다. 해당 행렬은 fᵢ 를 gᵢ 에 대하여 가능한 모든 조합과 gᵢ 를 xᵢ 에 대하여 가능한 모든 조합을 포함하고 있다. 예시 Related References
...junctions 이라고도 불림) 은 분류 성능을 향상시키기 위한 핵심 재료다. Factorization Machines 은 pairwise feature interaction 을 잡아내기 위해 내적 을 활용했다. D) Related
여기서 gradient 가 왜 가장 가파르게 올라가는 방향임을 알 수 있는데, 방향도함수가 최대가 되기 위해서는 gradient 와 vector 간 방향이 동일해야 하기 때문이다 (내적이므로).
Abstract 이 논문에서는 추천 시스템에서 sparse data 를 linear model 로 학습하는 방안을 제시했다. 학습에 사용한 training objective 는 closed-form solution 으로 표현될 수 있다. 실험 결과 SOTA CF 방식보다 더 나은 ranking accuracy 를 보였다. 여기서 CF 방식은 deep non-linear model 도 포함한다...
Gram Matrix B) Related C) References wiki: en.wikipedia.org/wiki/Grammatrᵢx
여기서 유사도는 dot product 나 cosine similarity 같은 간단한 식을 사용한다. B) References
Law of Cosines B) Proofs dot product 를 활용한 증명
이제 이 두 FDE 벡터의 내적을 계산하면, q1, q2와 p1, p3가 Zone 11에서 상호작용하고, p2는 Zone 10에서 홀로 남아 점수에 기여하지 못하게 됩니다. 이는 다중 벡터 간의 복잡한 유사도 관계를 단일 벡터...
Outer Product 사이즈가 각각 m \times 1 그리고 n \times 1 인 두 벡터가 있다고 가정하자.
Pythagorean Theorem 피타고라스 정리는 임의의 내적 공간에 대해서 다음과 같이 정의된다.
Gram Matrix 어떤 벡터들 v {1}, \ldots, v {n} 로 구성된 집합의 그람 행렬은 각 벡터들의 내적 (정확히는 inner product) G {i j}=\left\langle v {i}, v {j}\right\rangle 이 원소로 표현된 행렬을 의미한다.
Projection 정의 V 가 벡터 공간이고 U \subseteq V 는 V 의 subspace 라고 하자.
norm V 이란, 벡터 공간에 존재하는 벡터의 크기를 측정하기 위한 함수를 의미한다.
Law of Cosines B) Proofs dot product 를 활용한 증명 c=\mathbf{a}-\mathbf{b} \begin{aligned} c \cdot c &=(\mathbf{a}-\mathbf{b}) \cdot(\mathbf{a}-\mathbf{b}) \\ &=\mathbf{a}...
Matrix matrix 는 linear mapping 또는 vector 의 collection 이라고 생각할 수 있다. 벡터 공간 은 꽤 추상적이므로, 이를 컴퓨터에 표현하고 다루기 위해서는 숫자들로 구성된 직사각형 array 들, 즉, 행렬을 사용할 필요가 있다.
Frobenius Norm A.1) 정의 matrix의 norm 계산 방식으로, 모든 원소의 제곱합의 제곱근이다.
Orthogonal A.1) Orthogonal (직교) Vector 두 vector 간 내적 (dot product) 값이 0 (\boldsymbol{x}^{\top}\boldsymbol{y}=0) 일 때, 두 벡터가 직교한다 고 말한다.
Kronecker Product Kronecker product, sometimes denoted by \otimes, is an operation on two matrices of arbitrary size resulting in a block matrix.