최신 정보 검색(IR) 분야에서는 embedding model이 핵심 기술로 자리 잡고 있습니다. 사용자가 예를 들어 “에베레스트 산의 높이는?”과 같은 질의를 입력하면, IR의 목표는 방대한 데이터(수십억 개의 문서, 이미지, 동영상 등) 중에서 해당 질의와 관련 있는 정보를 찾아내는 것입니다. 임베딩 모델은 각 데이터 포인트를 하나의 벡터(임베딩)로 변환하여 의미적으로 유사한 데이터들이 수학적으로도 비슷한 벡터가 되도록 만듭니다. 이 임베딩들은 주로 inner product(내적 유사도)를 통해 비교되며, 이를 활용해 효율적인 maximum inner product search (MIPS) 알고리즘으로 빠른 검색이 가능합니다.
하지만 최근에는 ColBERT와 같은 멀티-벡터 모델이 등장하면서 IR 성능이 크게 향상되었습니다. 기존 단일 벡터 임베딩과 달리 멀티-벡터 모델은 각 데이터 포인트를 여러 개의 벡터 집합으로 표현하고, 더 정교한 유사도 함수를 적용하여 데이터 간 복잡한 관계를 잘 포착합니다. 특히 최신 멀티-벡터 모델에서 널리 쓰이는 Chamfer distance는 한 쪽 멀티-벡터 임베딩에 포함된 정보가 다른 쪽에도 얼마나 포함되어 있는지 측정할 수 있습니다.
다만 이런 멀티-벡터 방식은 정확도를 크게 높여주지만, 계산 비용이 매우 커지는 문제가 있습니다. 여러 개의 임베딩을 생성해야 하고, 복잡한 유사도 연산을 수행해야 하므로 검색 과정이 훨씬 비싸집니다.
이러한 문제를 해결하기 위해 “MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings”에서는 복잡한 멀티-벡터 검색 문제를 단일 벡터 내적 최대값 탐색(MIPS) 문제로 환원하는 새로운 알고리즘 MUVERA를 제안합니다.
MUVERA는 쿼리와 문서의 멀티-벡터 집합을 고정 차원의 단일 벡터(Fixed Dimensional Encoding; FDE)로 변환하여, 이 FDE들 간 내적이 원래의 멀티-벡터 유사도를 근사하도록 설계됩니다. 이를 통해 고속 MIPS 알고리즘을 활용해 후보군을 빠르게 뽑고, 이후 정확히 Chamfer 유사도로 재정렬함으로써 효율성과 정확성을 모두 확보할 수 있습니다.
FDE 생성 알고리즘은 오픈소스로 GitHub에 공개되어 있습니다.
멀티-벡터 검색에서 발생하는 어려움
멀티-벡터 모델은 일반적으로 토큰 단위로 여러 임베딩을 생성하며, 쿼리와 문서 간 유사도는 Chamfer 매칭 방식을 사용합니다. 즉, 각 쿼리 임베딩마다 가장 가까운 문서 임베딩과의 최대 유사도를 구하고 이를 전부 합산하는 방법입니다. 이렇게 하면 쿼리 각 부분이 문서 어떤 부분과 관련되는지까지 종합적으로 측정할 수 있습니다.
하지만 다음과 같은 문제점들이 있습니다.
- 임베딩 수 증가: 토큰마다 임베딩을 만들기 때문에 처리해야 할 벡터 수가 폭증합니다.
- 복잡하고 계산량 많은 유사도 점수 산출: Chamfer 매칭은 행렬곱 기반 비선형 연산으로 단순 내적보다 훨씬 무겁습니다.
- 효율적 서브선형 검색 부재: 단일 벡터 검색에서는 공간 분할 등 고속 MIPS 기법 덕분에 빠르고 정확하게 서브선형 시간 내 비교가 가능하지만, 멀티-벡터에서는 이러한 기법 적용이 불가능합니다.
예컨대 전통적인 MIPS 기법만으론 전체 내용을 반영하지 못해 적합하지 않습니다(문서 내 일부 토큰만 일치하더라도 전체적으로 별로 연관 없는 경우).
B) MUVERA: Fixed Dimensional Encoding 기반 해법
MUVERA는 복잡한 멀티-벡터 집합 전체를 하나의 고정 차원 벡터(FDE)로 압축하는 방식으로 문제를 풀어냅니다. 즉, 대용량 “멀티-벡터 집합”들을 각각 하나씩 다루기 어려우니 이들을 쉽고 빠르게 비교 가능한 하나의 FDE로 바꿉니다. 중요한 점은 이렇게 변환된 FDE들끼리 비교하면 원래 복잡했던 Chamfer 유사도 결과와 거의 비슷하게 나온다는 것입니다.
구체적인 절차는 다음과 같습니다:
- FDE 생성: 쿼리·문서 각각의 멀티-벡터 집합을 FDE라는 고정 길이 벡터로 변환합니다.
- MIPS 기반 1차 후보 추출: 모든 문서 FDE들을 표준 MIPS 인덱싱 구조에 저장해 두고, 쿼리 FDE와 내적값 기준으로 상위 후보군을 신속히 찾습니다.
- 재정렬(Re-ranking): 뽑힌 후보군에 대해 원래 Chamfer 유사도로 다시 점수를 매겨 최종 결과 순위를 정합니다.
FDE 변환 과정은 특정 데이터셋 특성에 의존하지 않아(데이터 독립적), 스트리밍 환경이나 데이터 분포 변화에도 강인하게 동작합니다. 게다가 기존 단일 벡터 방식과 달리 FDE는 지정된 오차 범위 내에서 실제 Chamfer 유사도를 확실히 근사하도록 설계되어 있으므로 최종 단계에서 항상 최적 결과를 보장합니다.
쿼리 FDE 생성 과정 예시: 각각의 토큰(단어)이 고차원 공간 상 한 점(예시는 2D)을 가지며, 공간은 무작위 초평면 분할(hyperplane cut)을 통해 여러 영역으로 나뉩니다. 각 영역에는 출력 FDE 상 특정 블록 좌표가 할당되고, 해당 영역에 속한 쿼리 벡터들의 좌표 합(sum)이 그 블록 값으로 설정됩니다.
문서 FDE 생성 과정 예시: 기본 구조는 쿼리와 같으나 해당 영역에 포함된 문서 벡터들은 합(sum)이 아닌 평균(avg)을 취한다는 차이가 존재하며 이는 Chamfer 유사의 비대칭성을 반영합니다.
B.1) 이론적 배경
본 연구는 probabilistic tree embeddings 등 기존 기하학 알고리즘 이론에서 착안했으며 내부적으로 이를 inner product 및 Chamfer similarity 상황에 맞게 확장·응용하였습니다.
FDE 생성 핵심 아이디어는 다차원 임베딩 공간을 여러 영역(partitioned section)으로 나누고 동일 영역 안에 들어가는 쿼리·문서 벡터쌍끼리는 효율적으로 근접성을 평가하는 것입니다. 실제 어느 조합이 가장 잘 맞을지는 미리 알 수 없으므로 무작위 파팅 방식을 활용해 전체 근사를 달성하게 됩니다.
논문(paper)에서는 이러한 방식으로 얻어진 FDE 기반 근사가 실제 Chamfer similarity 값을 강하게 보장함을 증명하고 있습니다(Latex-style 식 필요시 ). 즉 실제 multi-vector 검색 작업도 신뢰성 있게 single-vector 프록시만 써서 처리 가능함을 의미합니다.
C) FDE (Fixed Dimensional Encodings) 생성 방법
FDE는 다중 벡터 묶음(Q, P) 간의 ‘Chamfer Similarity’를 근사하는 단일 벡터(q, p)의 내적(inner product)을 만들기 위해 설계되었습니다. 생성 과정은 다음과 같이 요약할 수 있습니다.
-
공간 분할 (Space Partitioning): 전체 벡터가 존재하는 공간을 여러 개의 작은 구역(클러스터)으로 나눕니다. 이때 Locality Sensitive Hashing (LSH)의 일종인 SimHash와 같은 기법을 사용하여, 비슷한 벡터들이 같은 구역에 묶일 확률을 높입니다.
-
클러스터별 벡터 집계 (Vector Aggregation per Cluster): 각 구역(클러스터)에 속한 벡터들을 하나의 대표 벡터로 합칩니다.
- 쿼리 벡터(Q): 특정 구역에 속한 모든 쿼리 벡터들을 단순히 더합니다 (Summation).
- 문서 벡터(P): 특정 구역에 속한 모든 문서 벡터들의 중심점(Centroid, 평균 벡터)을 계산합니다.
-
벡터 결합 (Concatenation): 모든 구역에 대해 만들어진 대표 벡터들을 순서대로 길게 이어 붙여 하나의 고정된 차원을 가진 긴 단일 벡터, 즉 FDE를 생성합니다.
-
정확도 향상을 위한 기법:
- 반복 (Repetitions): 서로 다른 방식의 공간 분할을 여러 번 반복하여 FDE를 여러 개 만들고 이를 결합함으로써 결과의 안정성과 정확도를 높입니다.
- 내부 프로젝션 (Inner Projections): 각 클러스터의 벡터 차원을 랜덤 프로젝션을 통해 줄여서 최종 FDE의 차원 증가를 제어합니다.
이 과정을 통해, 원래는 복잡하게 계산해야 했던 두 벡터 묶음의 유사도를 FDE 벡터 쌍의 단순한 내적으로 빠르고 정확하게 근사할 수 있습니다.
C.1) 구체적인 예시
여러 벡터가 흩어져 있는 지도를 여러 구역으로 나눈 뒤, 각 구역별로 쿼리와 문서의 ‘대표 선수’를 뽑아 하나의 팀으로 만드는 것과 같습니다.
아주 간단한 2차원(d=2) 벡터 공간을 가정해 보겠습니다.
- 입력 데이터
- 쿼리 Q: 2개의 벡터로 구성 {q1, q2}
- q1 = (2, 8)
- q2 = (-3, 4)
- 문서 P: 3개의 벡터로 구성 {p1, p2, p3}
- p1 = (3, 7) (q1과 매우 유사)
- p2 = (6, 2)
- p3 = (-2, 5) (q2와 매우 유사)
- 쿼리 Q: 2개의 벡터로 구성 {q1, q2}
1단계: 공간 분할 (Space Partitioning)
가장 간단한 방법으로 벡터 공간을 4개의 사분면으로 나누겠습니다. (논문에서는 SimHash를 사용하지만, 개념 이해를 위해 사분면을 예로 듭니다.)
- Zone 1: x > 0, y > 0 (1사분면)
- Zone 2: x < 0, y > 0 (2사분면)
- Zone 3: x < 0, y < 0 (3사분면)
- Zone 4: x > 0, y < 0 (4사분면)
이제 각 벡터가 어느 Zone에 속하는지 확인합니다.
- q1(2, 8) → Zone 1
- q2(-3, 4) → Zone 2
- p1(3, 7) → Zone 1
- p2(6, 2) → Zone 1
- p3(-2, 5) → Zone 2
(Zone 3, 4에는 아무 벡터도 없습니다.)
2단계: 구역별 벡터 집계 (Aggregation per Zone)
이제 각 Zone별로 쿼리와 문서의 “대표 벡터”를 계산합니다. 이때 쿼리와 문서의 계산 방식이 다른 것이 MUVERA의 핵심입니다.
- 쿼리(Q) 대표 벡터: 해당 Zone에 속한 쿼리 벡터들을 단순히 더합니다 (Summation).
- 문서(P) 대표 벡터: 해당 Zone에 속한 문서 벡터들의 평균을 냅니다 (Centroid).
Zone 1 계산:
- 속한 쿼리 벡터: {q1}
- 속한 문서 벡터: {p1, p2}
- Q_zone1 = q1 = (2, 8) (더할 게 하나뿐임)
- P_zone1 = (p1 + p2) / 2 = ((3, 7) + (6, 2)) / 2 = (9, 9) / 2 = (4.5, 4.5)
Zone 2 계산:
- 속한 쿼리 벡터: {q2}
- 속한 문서 벡터: {p3}
- Q_zone2 = q2 = (-3, 4)
- P_zone2 = p3 / 1 = (-2, 5)
Zone 3, 4 계산:
- 속한 벡터가 아무것도 없으므로 대표 벡터는 모두 0벡터입니다.
- Q_zone3 = (0, 0)
- P_zone3 = (0, 0)
- Q_zone4 = (0, 0)
- P_zone4 = (0, 0)
3단계: 벡터 결합 (Concatenation)으로 최종 FDE 생성
이제 각 Zone에서 계산된 대표 벡터들을 순서대로 쭉 이어 붙여 하나의 긴 단일 벡터, 즉 FDE를 만듭니다.
-
최종 FDE_Query (fq) = [Q_zone1, Q_zone2, Q_zone3, Q_zone4] = [(2, 8), (-3, 4), (0, 0), (0, 0)] = (2, 8, -3, 4, 0, 0, 0, 0) (총 8차원 벡터)
-
최종 FDE_Document (fp) = [P_zone1, P_zone2, P_zone3, P_zone4] = [(4.5, 4.5), (-2, 5), (0, 0), (0, 0)] = (4.5, 4.5, -2, 5, 0, 0, 0, 0) (총 8차원 벡터)
왜 이렇게 하는가? (The “Magic”)
이제 이 두 개의 긴 FDE 벡터(fq, fp)의 내적(dot product)을 계산하면 어떤 일이 일어나는지 보겠습니다.
fq · fp = (Q_zone1 · P_zone1) + (Q_zone2 · P_zone2) + (Q_zone3 · P_zone3) + (Q_zone4 · P_zone4)
- Zone 1 내적: (2, 8) · (4.5, 4.5) = (2 * 4.5) + (8 * 4.5) = 9 + 36 = 45
- Zone 2 내적: (-3, 4) · (-2, 5) = (-3 * -2) + (4 * 5) = 6 + 20 = 26
- Zone 3, 4 내적: 0
최종 내적값 = 45 + 26 + 0 + 0 = 71
이 계산의 의미는 다음과 같습니다.
- 같은 구역에 있어야만 점수를 얻는다: q1과 p3는 서로 다른 Zone에 있으므로 내적 계산에서 서로에게 아무런 영향을 주지 못합니다. 이는 쿼리 토큰과 멀리 떨어진 문서 토큰의 상호작용을 무시하는 Chamfer Similarity의 특성을 흉내 낸 것입니다.
- 유사한 벡터가 같은 구역에 모이면 점수가 높아진다: q1과 그와 유사한 p1이 모두 Zone 1에 모였고, q2와 유사한 p3가 Zone 2에 모였기 때문에 각 Zone의 내적값이 높게 나왔습니다. 이것이 바로 FDE 내적이 Chamfer Similarity를 근사하는 원리입니다.
- 문서 벡터를 평균 내는 이유: 만약 Zone 1에 p1 외에도 관련 없는 벡터 p2가 포함되었을 때, 이들의 평균을 취함으로써 p1의 영향력을 어느 정도 희석시키는 효과가 있습니다. 이는 한두 개의 토큰만 일치하고 나머지는 관련 없는 문서의 점수가 과도하게 높아지는 것을 방지합니다.
실제 논문에서는 이 과정을 더 높은 차원(d=128), 더 많은 구역(예: 64개), 그리고 서로 다른 공간 분할을 여러 번 반복(Reps=20)하여 훨씬 더 길고 정교한 FDE를 만들어 검색 정확도를 극대화합니다.
C.2) SimHash를 적용한 FDE 생성 예시
SimHash가 정확히 무엇이고, 어떻게 이전 예시의 ‘사분면’을 대체하는지 단계별로 설명해 드리겠습니다.
C.2.1) SimHash란 무엇인가? (직관적인 이해)
**SimHash(유사도 해시)**는 고차원 벡터의 **‘지문(Fingerprint)‘**을 만드는 기술이라고 생각할 수 있습니다. 핵심 특징은 다음과 같습니다.
원래 공간에서 서로 가까운(유사한) 벡터들은, 그들의 지문(해시값)도 서로 비슷할 확률이 높다.
‘지문이 비슷하다’는 것은, 지문을 구성하는 0과 1 문자열에서 몇 글자만 차이 나는 것을 의미합니다 (예: 10110과 10010은 한 글자만 다릅니다).
Q) 어떻게 ‘지문’을 만드는가?
SimHash는 벡터 공간을 무작위로 가로지르는 여러 개의 **‘기준선(Hyperplane)‘**을 사용하여 지문을 만듭니다.
-
‘질문’ 준비하기 (기준선 생성): 공간에 무작위로 여러 개의 기준선(2차원에서는 그냥 ‘선’)을 긋습니다. 각 선은 공간을 두 영역으로 나눕니다.
-
‘답변’ 얻기 (어느 쪽에 속하는가?): 각 벡터에 대해, 이 선들의 ‘어느 쪽’에 있는지 확인합니다.
- ‘A쪽’에 있으면 1
- ‘B쪽’에 있으면 0
-
‘지문’ 완성 (답변 조합): 각 선에 대한 답변(0 또는 1)을 모두 모으면 그 벡터만의 고유한 지문, 즉 SimHash 값이 완성됩니다.
위 그림에서 파란색 기준선 하나만 있다면, q1과 p1은 같은 편(1)이고 q2는 다른 편(0)입니다. 여기에 주황색 기준선을 추가하면, 각 벡터는 (파란선 답변, 주황선 답변) 형태의 2비트짜리 지문을 갖게 됩니다.
이제 이전 예시로 돌아가서, ‘4개의 사분면’ 대신 2개의 기준선(Hyperplane)을 사용하는 SimHash를 적용해 보겠습니다. (논문에서는 ksim=36 정도로, 864개의 구역을 만듭니다.)
C.2.2) 1단계: 공간 분할 (SimHash 적용)
먼저, ‘질문’ 역할을 할 2개의 무작위 기준선을 정의해야 합니다. 각 기준선은 원점을 지나는 벡터(normal vector) r로 정의할 수 있습니다. 벡터 v와 r을 내적한 값 (v · r) 이 양수면 한쪽, 음수면 다른 쪽입니다.
- 기준선 1 (Normal Vector r1): r1 = (1, 1)
- 기준선 2 (Normal Vector r2): r2 = (-1, 2)
이제 모든 벡터의 ‘지문’을 계산합니다. 지문은 (r1에 대한 답변, r2에 대한 답변)이 됩니다.
- q1 = (2, 8)
- q1 · r1 = (2_1 + 8_1) = 10 (> 0 이므로 1)
- q1 · r2 = (2*-1 + 8*2) = 14 (> 0 이므로 1)
- q1의 Zone ID (지문) = 11
- q2 = (-3, 4)
- q2 · r1 = (-3_1 + 4_1) = 1 (> 0 이므로 1)
- q2 · r2 = (-3*-1 + 4*2) = 11 (> 0 이므로 1)
- q2의 Zone ID (지문) = 11
- p1 = (3, 7)
- p1 · r1 = (3_1 + 7_1) = 10 (> 0 이므로 1)
- p1 · r2 = (3*-1 + 7*2) = 11 (> 0 이므로 1)
- p1의 Zone ID (지문) = 11
- p2 = (6, 2)
- p2 · r1 = (6_1 + 2_1) = 8 (> 0 이므로 1)
- p2 · r2 = (6*-1 + 2*2) = -2 (< 0 이므로 0)
- p2의 Zone ID (지문) = 10
- p3 = (-2, 5)
- p3 · r1 = (-2_1 + 5_1) = 3 (> 0 이므로 1)
- p3 · r2 = (-2*-1 + 5*2) = 12 (> 0 이므로 1)
- p3의 Zone ID (지문) = 11
Zone 할당 결과:
- Zone 11: {q1, q2, p1, p3}
- Zone 10: {p2}
- Zone 01: {}
- Zone 00: {}
사분면으로 나눴을 때와 결과가 달라졌습니다. 이것이 SimHash의 특징입니다. 축에 구애받지 않고 공간을 나누기 때문에, 더 유연하게 유사한 벡터들을 그룹핑할 수 있습니다.
C.2.2.1) 2단계: 구역별 벡터 집계
이제 새로운 Zone 할당 결과에 따라 대표 벡터를 계산합니다.
- Zone 11 계산:
- 속한 쿼리: {q1, q2} → Q_zone11 = q1 + q2 = (2, 8) + (-3, 4) = (-1, 12)
- 속한 문서: {p1, p3} → P_zone11 = (p1 + p3) / 2 = ((3, 7) + (-2, 5)) / 2 = (0.5, 6)
- Zone 10 계산:
- 속한 쿼리: {} → Q_zone10 = (0, 0)
- 속한 문서: {p2} → P_zone10 = p2 = (6, 2)
- Zone 01, 00 에는 벡터가 없으므로 모두 (0, 0) 입니다.
C.2.2.2) 3단계: 최종 FDE 생성
새로운 대표 벡터들을 이어 붙입니다.
- FDE_Query (fq) =
[(-1, 12), (0, 0), (0, 0), (0, 0)]=(-1, 12, 0, 0, 0, 0, 0, 0) - FDE_Document (fp) =
[(0.5, 6), (6, 2), (0, 0), (0, 0)]=(0.5, 6, 6, 2, 0, 0, 0, 0)
이제 이 두 FDE 벡터의 내적을 계산하면, q1, q2와 p1, p3가 Zone 11에서 상호작용하고, p2는 Zone 10에서 홀로 남아 점수에 기여하지 못하게 됩니다. 이는 다중 벡터 간의 복잡한 유사도 관계를 단일 벡터 내적으로 효과적으로 근사하는 과정입니다.
D) 실험 결과

MUVERA 성능 평가는 BEIR 정보검색 표준 benchmark세트에서 이루어졌으며 이전 최고 성능 시스템인 PLAID 대비 뛰어난 결과를 보였습니다.
향상된 recall: 기존 대표 multi-vector retrieval 접근법(SV heuristic; PLAID에서도 사용됨)에 비해 MUVERA(FDE)는 더 적은 후보군만 추출하면서 동일 recall 수준에서 훨씬 높은 성능을 기록했습니다(Figure 참고).
예컨대 동일 recall 달성 시 필요한 candidate 수가 5~20배 적었습니다.
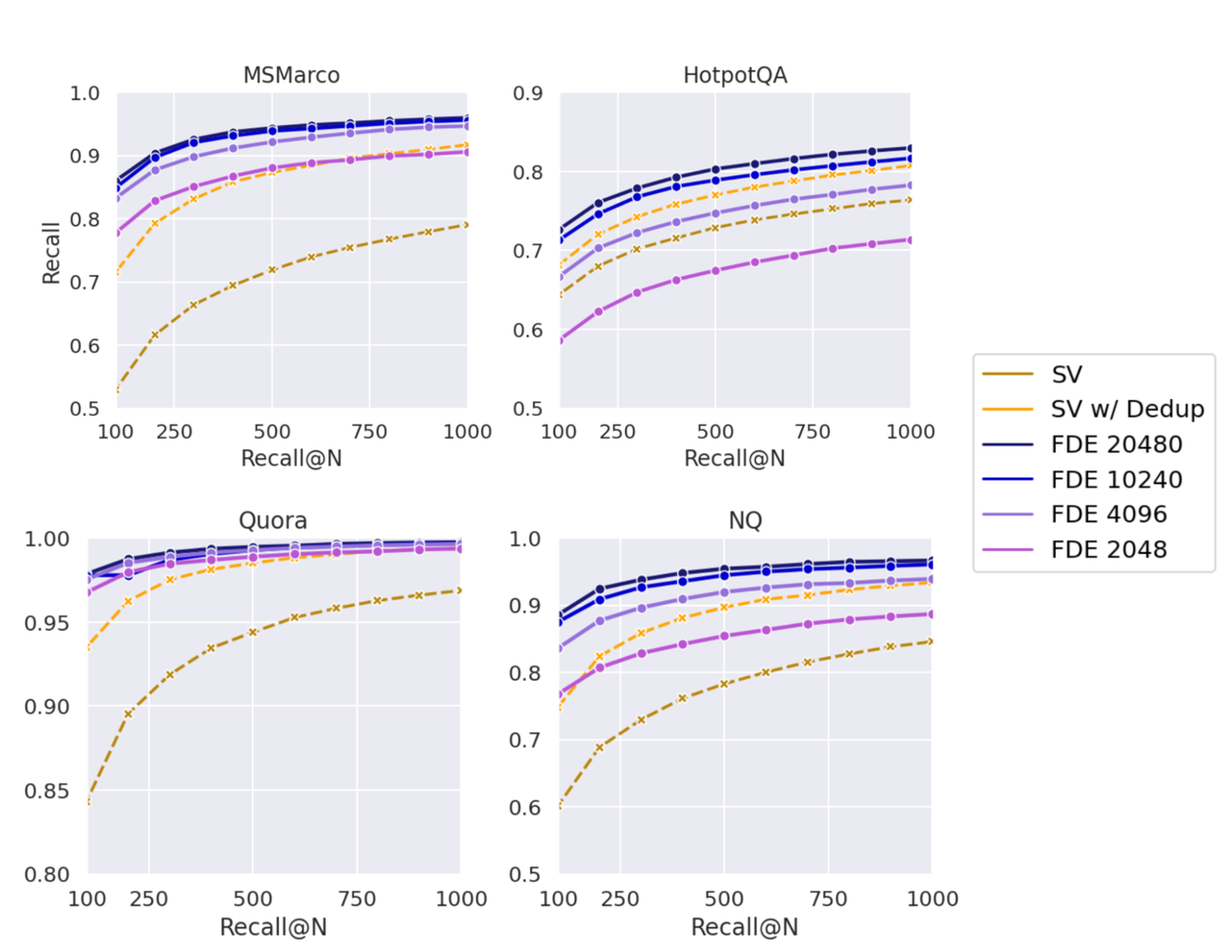
Fixed dimensional encoding(FDE)의 차원별 recall vs 기존 single-vector heuristic(SV). 10240 차원 FDE조차 원본 MV 표현(SV heuristic 사용)의 크기와 거의 같으면서 훨씬 적은 비교만 필요.
낮아진 지연시간(latency): 최신 multi-vector retrieval 시스템인 PLAID 대비 MUVERA는 평균 10% 더 높은 recall 및 약 90% 더 짧아진 latency로 BEIR 데이터셋 전반에서 월등했습니다(Figure 참고).
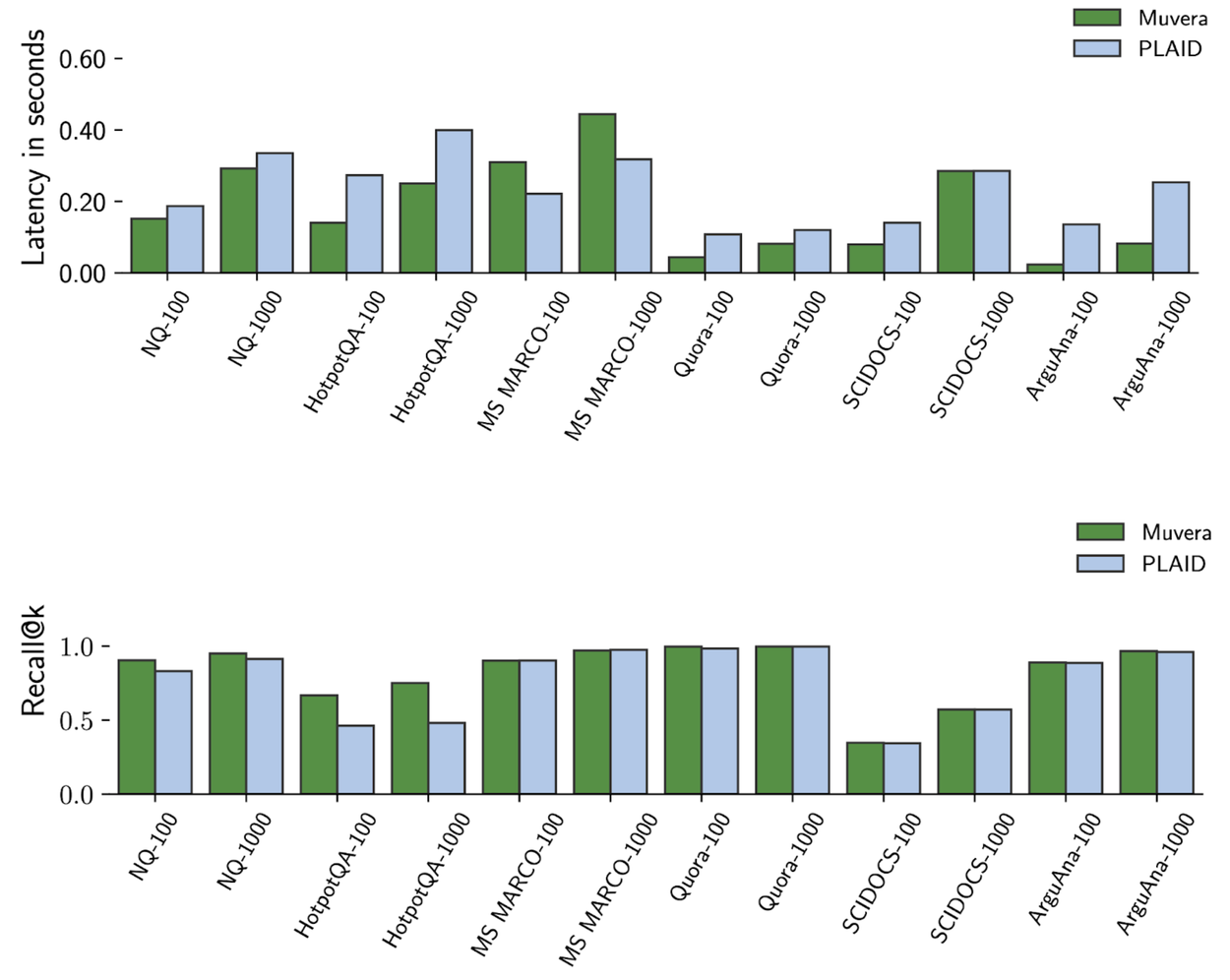
MUVERA vs PLAID on BEIR benchmarks.
또한 MUVERA 방식의 FDE들은 product quantization 등 압축 기법 적용 시 메모리를 최대 32배 줄여도 품질 저하 없이 사용할 수 있다는 것이 검증되었습니다.
종합하면 MUVERA 덕분에 대규모 multi-vector retrieval 환경에서도 실질적으로 신속하고 효율적인 처리가 가능함이 입증되었습니다.
E) Related Work
논문은 MUVERA를 기존의 여러 다중 벡터 검색 방법론과 비교하며 장점을 부각합니다.
- ColBERT / ColBERTv2: 다중 벡터 표현과 ‘late-interaction’ 개념을 도입한 선구적인 모델입니다. 각 쿼리 토큰 벡터와 가장 유사한 문서 토큰 벡터들의 유사도를 합산하는 방식으로 동작합니다. MUVERA는 ColBERTv2 모델이 생성한 임베딩을 기반으로 실험을 진행했습니다.
- SV Heuristic (단일 벡터 휴리스틱): 가장 기본적인 다중 벡터 검색 접근법으로, ColBERT의 초기 버전이나 PLAID의 기반이 됩니다. 각 쿼리 벡터에 대해 개별적으로 가장 유사한 문서 토큰들을 MIPS로 찾은 후, 후보 문서들을 모아 다시 순위를 매기는 방식입니다. 논문에서는 이 방식의 한계를 지적합니다.
- PLAID: ColBERTv2의 검색 과정을 최적화한 고성능 검색 엔진입니다. 복잡한 4단계 파이프라인(초기 후보 생성, 가지치기, 재계산 등)을 통해 점진적으로 후보 수를 줄여나갑니다. MUVERA는 이 PLAID의 복잡한 구조를 단순화하면서도 더 낮은 지연 시간과 높은 재현율을 달성하는 것을 주요 비교 목표로 삼았습니다.
- DESSERT: LSH를 기반으로 ɛ-근사 최근접 이웃을 찾는 다른 접근법입니다. PLAID보다 2~5배 빠르지만 재현율(recall)이 더 낮다고 언급됩니다. MUVERA는 DESSERT와 달리 검색 품질 저하 없이 속도를 개선하는 데 중점을 둡니다.