Attention
attention 은 일종의 aggregation, pooling 또는 weighted sum function 이다.
A.1) 핵심 아이디어
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 time step 마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점입니다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중 (attention) 해서 보게 됩니다.
A.2) Vs. Seq2seq
seq2seq 모델은 attention 에 비해 다음과 같은 단점들이 존재한다.
- 하나의 고정된 크기의 벡터 (마지막 encoder hidden state) 에 모든 정보를 압축하려고 하니까 정보 손실이 발생
- RNN 의 고질적인 문제인 기울기 소실 (vanishing gradient) 문제가 존재
A.3) Attention 동작 과정 (vs. Seq2seq)
마지막 encoding 스테이지의 hidden state 만 건네주는 Seq2seq 모델과 달리 encoder 는 전체 hidden states 를 decoder 에게 건네준다.
그리고 attention decoder 는 output 을 생성할때 encoder 에서 건네준 hidden state 를 이용하는데, 계산하려는 output 이 각 hidden state 와 얼마나 관련이 있는지 score 를 계산한다 (softmax). 그리고 계산된 score 를 hidden state 에 적용하고 (vector dot), 이렇게 가중치가 적용된 state 들을 하나로 더하여 context vector 로 완성시킨다. 최종적으로 decoder 의 hidden state 와 context vector 를 concatenate 하고, feedforward 신경망에 입력하여 output 을 계산한다.

B) 함수로 표현한 Attention
Attention(Q, K, V) = outputattention function 은 query Q 와 key-value (K-V) 쌍을 output 에 mapping 시키는 역할을 한다. 여기서 query, keys, values 그리고 output 은 모두 vector 로 볼 수 있다.
- Query: time step 의 decoder 셀에서의 hidden state
- Keys: 모든 time steps 에서 encoder 의 hidden states
- Values: 모든 time steps 에서 encoder 의 hidden states (Key 와 동일)
그리고 이 vector 들은 - 차원의 input vector 와 embedding matrix 의 곱으로 계산된다.
output 은 가중치가 곱해진 values 들의 합이고, 가중치 (weight) 는 query 그리고 연관된 key 를 통해 계산된다.
B.1) Attention Function 의 종류
일반적으로 가장 많이 사용하는 attention function 은 additive attention 과 multiplicative(dot-product) attention 이 있다.
두 함수의 차이점은 compatibility function 으로 한개의 hidden layer 가 있는 MLP 를 사용하는가 (additive) 아니면, softmax function 을 사용하는가 (multiplicative) 의 차이점이 있다. dot-product 가 더 계산은 빠르지만, key 의 차원 가 커질수록 additive 방식이 좋은 성능을 보인다고 한다.
B.1.1) Scaled Dot-Product Attention
차원의 key 와 query 그리고 차원의 values 로 input 이 구성되어 있는 attention function 을 의미한다.
특정 query 와 모든 keys 의 내적 (dot product) 을 계산하고, 로 나눈 뒤 (scaled) softmax 를 적용하여 value 에 대한 weight 를 계산한다. 이를 해석하자면, decoder 의 hidden state (query) 와 encoder 의 모든 hidden state 들 (keys) 간 유사도를 계산하여, encoder 의 모든 hidden states 들 (values) 에 대한 weight 를 계산한다는 것이다.
실전에서 attention function 은 query 들의 집합 (matrix ) 에 대해 동시에 계산한다. 물론, keys 와 values 도 matrices 로 묶인다.
B.1.1.1) Why Scaled?
가 커질수록 dot products 의 값이 커지기 때문에 softmax 에서 gradient 값이 매우 작아지게 된다. 이러한 현상을 막기 위해서 scale 값을 적용했다고 한다.
B.1.1.2) Example Figure
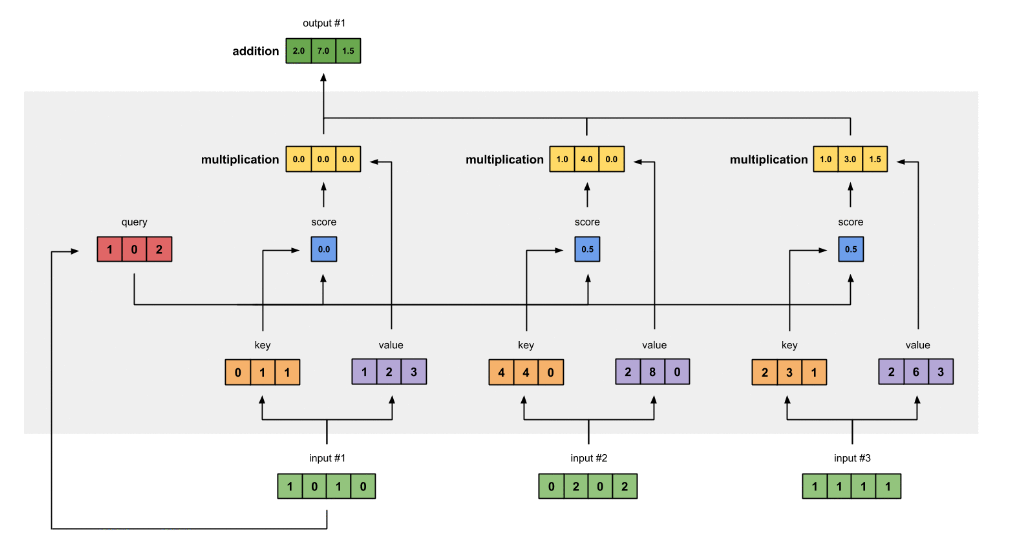
input vector 에서 embedding matrix 의 곱을 통해 key, value, query vector 를 얻은 모습