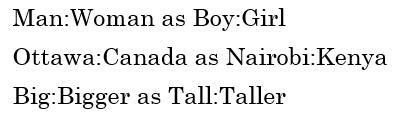Word Embedding
각 단어에 대한 차원 feature 를 만들고 적절한 값을 부여하는 방식을 의미한다.
A.1) 예시

One Hot Encoding 을 통해서도 Word Embedding 이 가능하긴 하다.
Word Embedding 은 convolution Layer (CNN 참고) 의 동작 방식과 유사하다. 즉, Convolutional layer 를 이용하여 그림에 대한 feature vector 를 Encoding 하는 방법이 Embedding 과 유사하다.
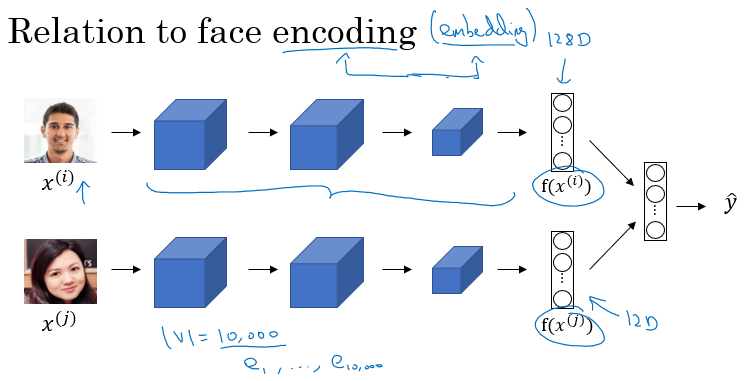
Encoding 과 Embedding 의 차이점은 차원 축소를 적용하는 목적이 다르다는 것이다. Embedding 은 도메인이 고정 (fixed) 된 단어에 대한 representation 을 찾는 반면, Encoding 은 도메인이 제한이 없는 그림 파일들에 대해 representation 을 찾는다는 것이다.
Tips of the word embedding: 문장 내의 단어들의 임베딩 벡터들의 평균이 그 문장의 벡터가 될 수 있음
B) 전이 학습과 Word Embedding
모델이 학습하다가 모르는 단어가 나와도, 만약 해당 단어가 특정 타입의 단어와 비슷하다고 계산되면, 모르는 단어도 어떤 타입의 vector 로 치환해야할지 쉽게 알 수 있을 것이다.
예시
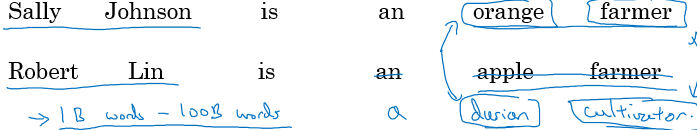
durian 과 cultivator 라는 단어를 몰라도 durian 이 orange 와 비슷하다면, cultivator 역시 farmer 와 비슷하다고 생각할 것이다.
이러한 점을 활용해서 word embedding 은 transfer learning 에 다음과 같은 단계를 통해서 활용될 수 있다.
- 대용량 text corpus(약 1-100 백만 단어들) 에서 학습된 word embedding 을 찾는다 (pre-trained or just train yourself).
- 이제 학습된 embedding 을 transfer 하여 좀 더 작은 training set 에 맞춘다. 원한다면 그 작은 데이터에 대해서 추가적으로 학습하여 fine tuning 을 진행할 수 있다.
C) Properties of Word Embeddings
Word Embedding 은 어떠한 특성을 통해 학습되는지 예시를 통해 직관적으로 알아보자.
각 word 는 embedding vector 로 표현되는데, 이 vector 들 간의 차이를 활용한다.
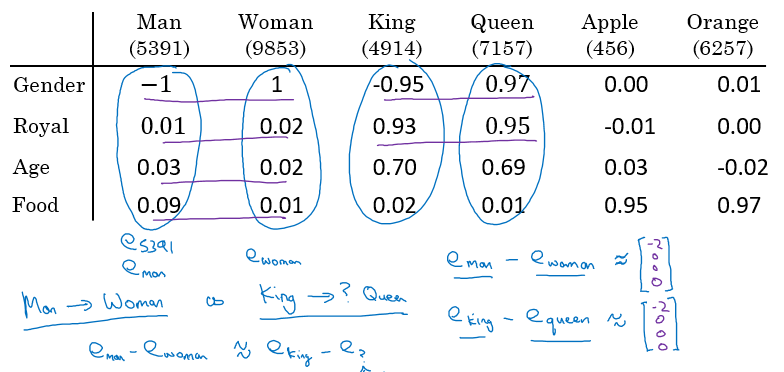
단어 Man 과 Woman 은 gender feature 에서 비슷하므로, 두 vector 를 서로 뺀 후의 값을 살펴보면, Gender 차원만 차이가 발생함을 확인할 수 있다.
King 과 Queen 도 Gender 차원만 차이가 발생한다. 만약 Queen 에 대한 embedding vector 를 모른다면, 다음과 같은 수식을 활용하여 해당 vector 를 찾을 수 있다.
즉, word embedding 은 embedding vector 간 차이를 활용하여 다른 단어에 대한 vector embedding 을 학습한다.
는 찾으려하는 word 의 embedding vector 다.
- 유사도를 최대로 하는 vector 를 찾는 것이다.
- Embedding vector 간 유사도를 계산할 때, 일반적으로 cosine similarity 를 사용한다.
이러한 방법으로 아래 그림과 같은 다양한 관계를 찾을 수 있다.