Embedding Matrix 란
Word Embedding 에서 One Hot Encoding 벡터를 dense vector 로 변환하기 위해 사용하는 matrix 입니다.
B) Embedding Matrix 적용 방법
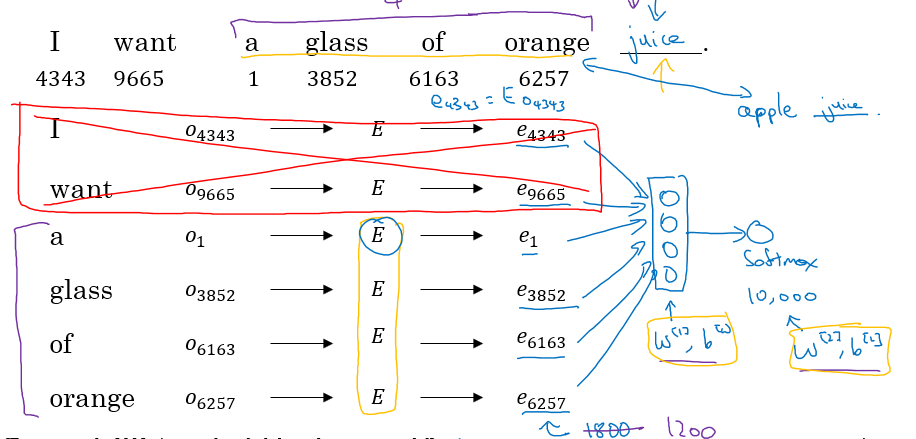
- 크기의 embedding matrix 가 있다고 가정할 때, 특정 단어 의 one hot vector 는 크기가 입니다.
- 이때, embedding matrix 를 적용하면 는 크기가 이 되며, 이는 사실상 embedding matrix 의 특정 column vector 를 가져오는 것과 동일합니다. 여기서 해당 column 은 one hot vector 에서 값이 1 인 위치에 해당합니다.
C) Word Embedding Matrix 학습 과정
- 학습 과정은 다음과 같습니다:
- Word Embedding 모델의 weights 인 는 처음에 랜덤하게 초기화됩니다.
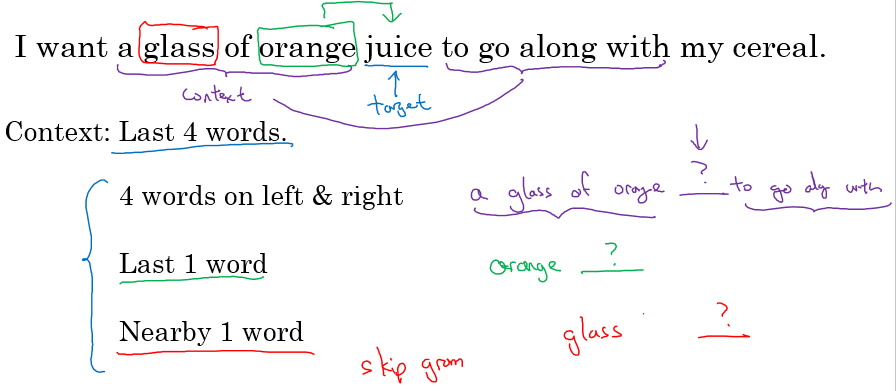
- 그런 다음 corpus 에서 한 문장을 선택합니다 (예: “I want a glass of orange”).
- 선택한 문장에서 context 와 target 을 정합니다.
- 여기서 context 는 입력 데이터이고, target 은 예측하고자 하는 출력 데이터입니다.
- 예를 들어, “a glass of orange”가 context 이고 “juice”가 target 이 될 수 있습니다.
- context 에 있는 단어들을 one-hot vector 로 표현한 후, 이를 embedding vector 로 변환하여 하나로 쌓습니다 (stack). 그런 다음 softmax function layer 를 통해 확률 벡터를 출력합니다.
- 이 확률 벡터는 corpus 내 고유 단어 개수인 차원의 벡터이며, 각 단어가 context 에 기반해 선택될 확률을 나타냅니다.
- 마지막으로, softmax function output 중 target word 의 확률을 높이는 방향으로 모델을 학습시킵니다.
위 과정을 시각적으로 나타낸 그림