Why Convolutional Network
왜 단순한 DNN 이 아니라 CNN 이 필요한 것일까?
이미지를 일반적인 fully neural network 로 학습하게 된다면 많은 parameters 를 가져야 하므로 overfitting 위험과 연산량 증가 이슈가 있다.
예시를 들어보면 아래와 같다.
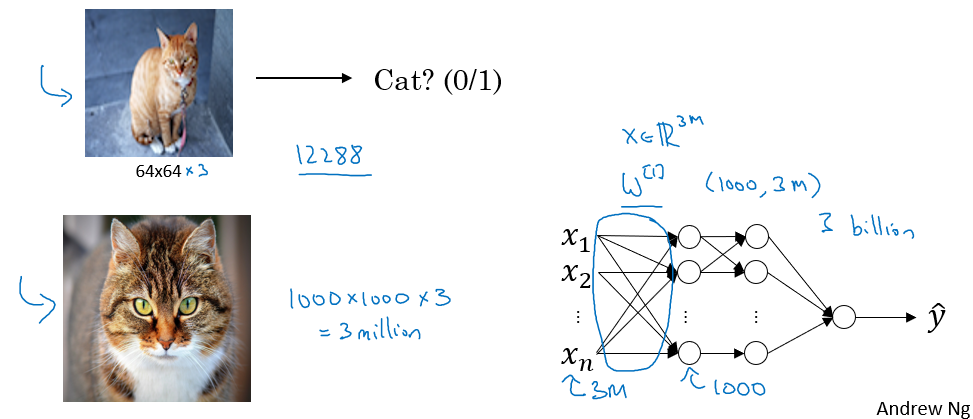
위 사진은 크기를 가지는 고양이 사진이다. 이 사진을 입력 벡터로 사용하기 위해서 필요한 weights 의 개수는 3 million 이다. 즉, 매우 많은 parameters 로 인해 연산량이 크게 증가하고, overfitting 의 위험도 커진다.
B) Convolution: Edge Detection
애초에 convolution layer 라는 것은 어떤 의미를 가지고 있는 것인가?
기존의 이미지들에 대한 lower feature 들을 추출해내기 위하여 다양한 filter 들을 사용한다. 대표적으로는 vertical edge 와 horizontal edge 가 존재한다.
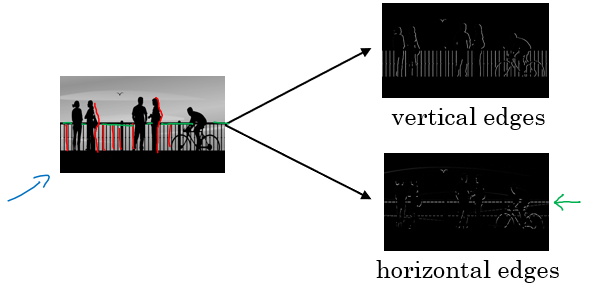
B.1) Vertical Edge Detection
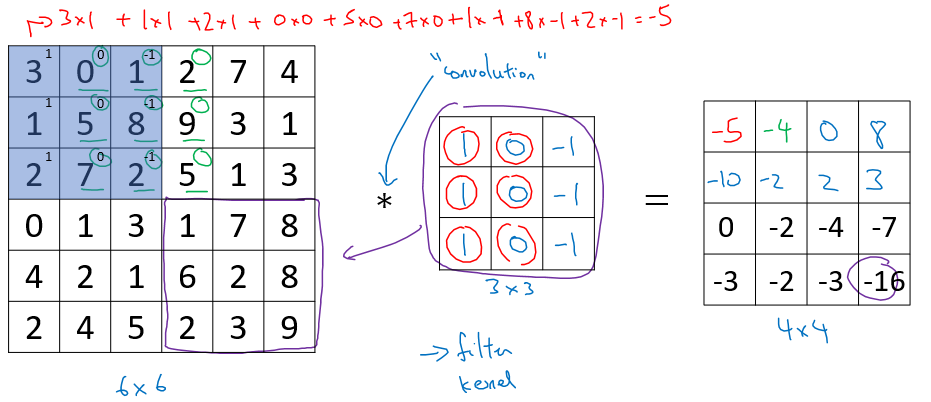 위 그림은 vertical edge detection 을 위해 이미지에 filter 를 적용하는 과정을 나타낸 것이다.
필터는 단순히 convolution 이라는 연산에 의해 적용되는데, 각 filter matrix 의 원소에 mapping 되는 이미지의 값을 곱하고, 이를 모두 합치면 하나의 필터링된 값을 가지게 된다.
위 그림은 vertical edge detection 을 위해 이미지에 filter 를 적용하는 과정을 나타낸 것이다.
필터는 단순히 convolution 이라는 연산에 의해 적용되는데, 각 filter matrix 의 원소에 mapping 되는 이미지의 값을 곱하고, 이를 모두 합치면 하나의 필터링된 값을 가지게 된다.
좀 더 다양한 detection 을 위한 filter 들이 있다.
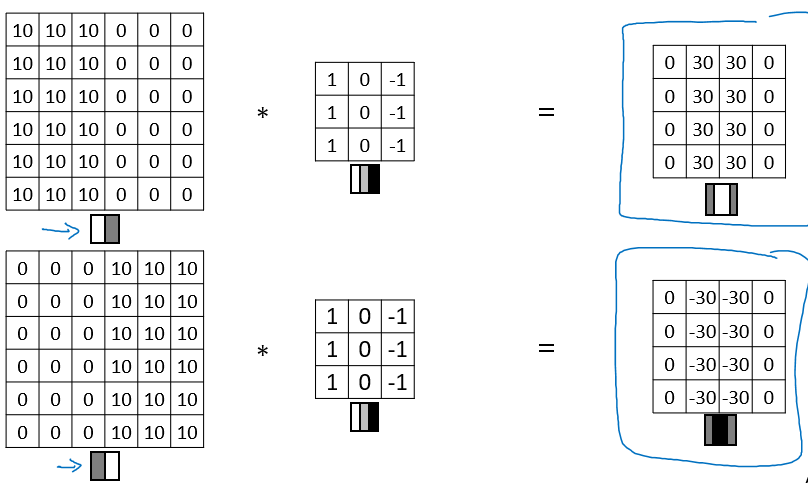 - 필터링된 값은 높은 값을 가질수록 밝고, 낮은 값을 가질 수록 어둡다.
- 필터링된 값은 높은 값을 가질수록 밝고, 낮은 값을 가질 수록 어둡다.
- 기존에는 원하는 필터링 된 값을 얻기 위해, 필터 matrix 내 값을 모두 수작업해야 했다.
- 하지만 이미지에 따라 필터가 올바르게 적용되기도 하고 그렇지 않기도 했다.
- Padding
- Strided convolution
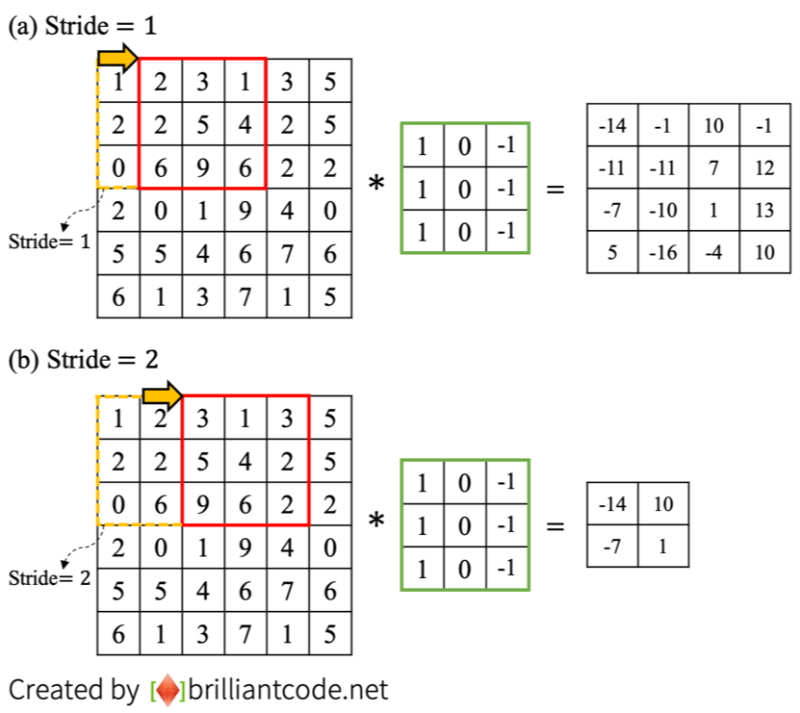
B.2) Output Size 계산 방법
- input image, filter, Padding , stride 가 주어질 때, output size 는 다음과 같다.
-
- floor sign 은 에 의해 정확히 나누어 떨어지지 않을 때, 적용하는 것이다.
- 직관적으로 생각하면, stride 를 옮기면서 filter 에 전부 들어오지 않는 이미지 segment 는 무시하겠다는 의미가 된다.
C) Convolutions over Volumes
지금까지는 2 차원 이미지에 대해서만 다뤘지만, 실제로는 3 차원 이미지에 필터를 적용해야 한다. 이미지는 흑백이 아닌 이상 RGB 값인 3 개의 channel(LLM) 로 구성된다.
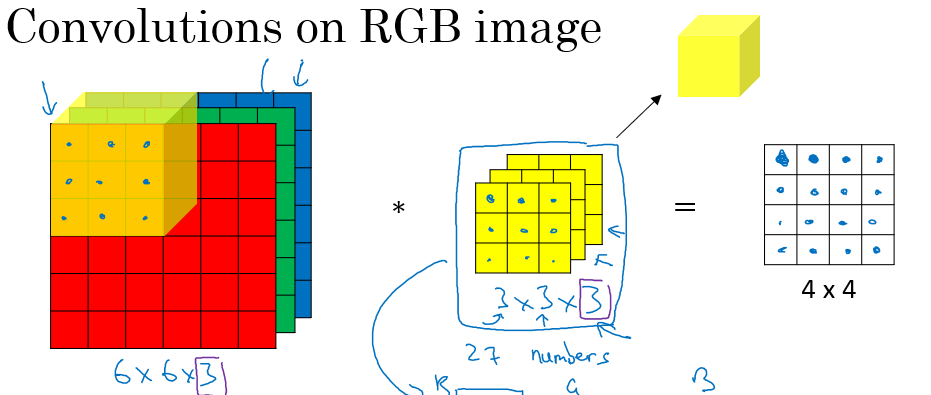
각 채널은 따로따로 계산되는 것이 아니라, image 채널이 개라면, 적용하는 convolution 필터도 개의 채널을 가져야 한다. 그리고 계산 과정도 2 차원이랑 비슷하다. 모두 element-wise 곱을 한 뒤에 합쳐주면 된다.
Multiple filters
- 필터가 하나가 아닌 여러개가 있을 수 있다.
- 주의할 점은 필터의 channel(LLM) 과 개수를 명확히 해야한다는 것이다.
- channel(LLM) 은 단순히 필터의 3 차원 성분이다.
- 이 값은 이미지를 따라간다.
- 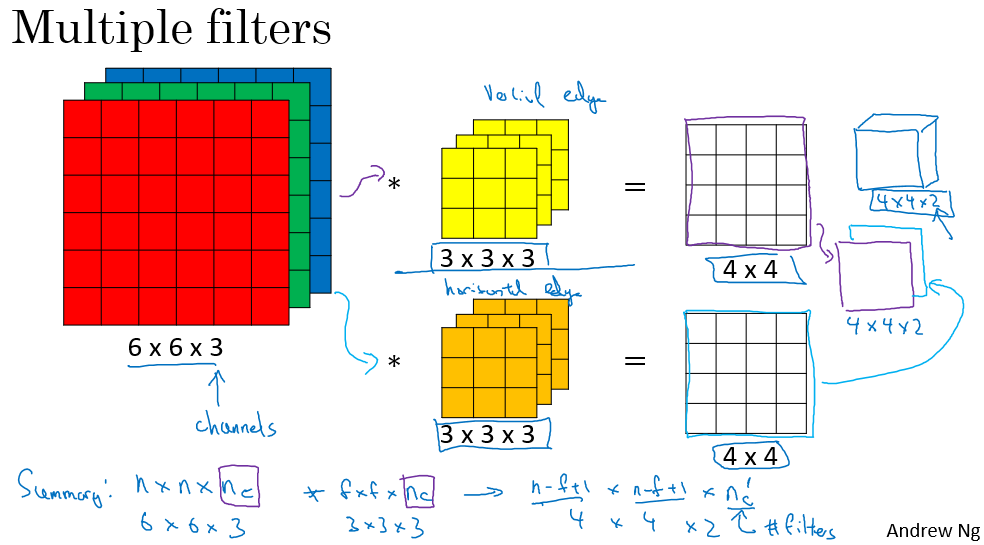 - 필터가 개라면, output 이미지의 3 차원 개수도 개이다.
- 필터가 개라면, output 이미지의 3 차원 개수도 개이다.
- One Layer of a Convolutional Network
- Convolution Neural Network 의 단일 레이어는 다음과 같이 동작한다.
- Input image -> filter -> activation(output + bias)
- activation 까지 적용된 결과가 filter 의 개수만큼 쌓이게 된다.
- Input image -> filter -> activation(output + bias)
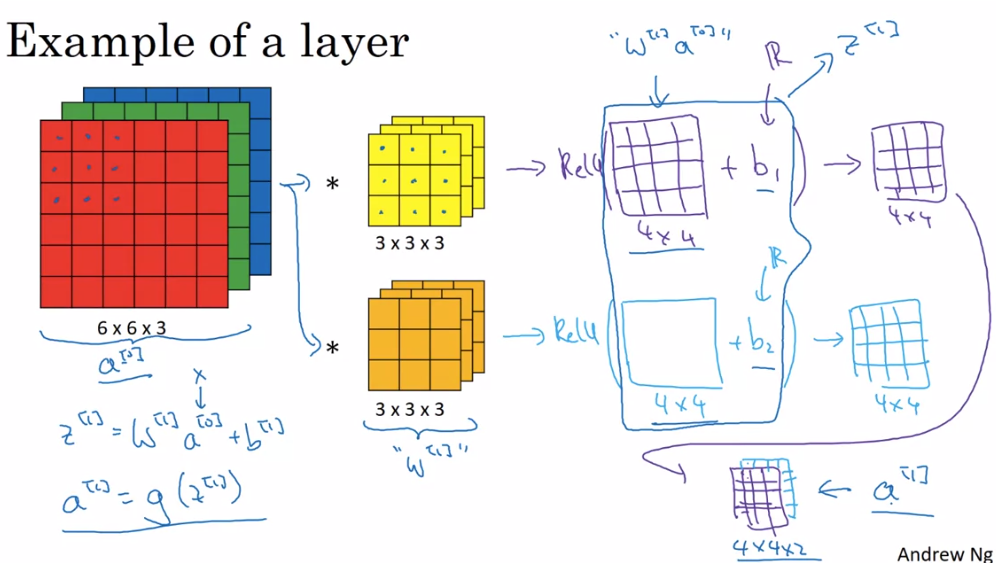
- Convolution Neural Network 의 단일 레이어는 다음과 같이 동작한다.
D) Summary of Notation
번째 convolution layer 가 다음과 같은 특성을 가진다고 하자.
- = Padding
- = stride
- Input Size
- 가 주어지면 Output Size 는 다음과 같다. Output Size
- 도 에 대하여 동일하게 적용할 수 있다.
- 각 filter Size
- 일 경우, 이미지의 채널 수 와 같다.
- Activation
- Weights (parameter 개수)
- bias - - 일반적으로, ) 로 구현하는게 편하다.
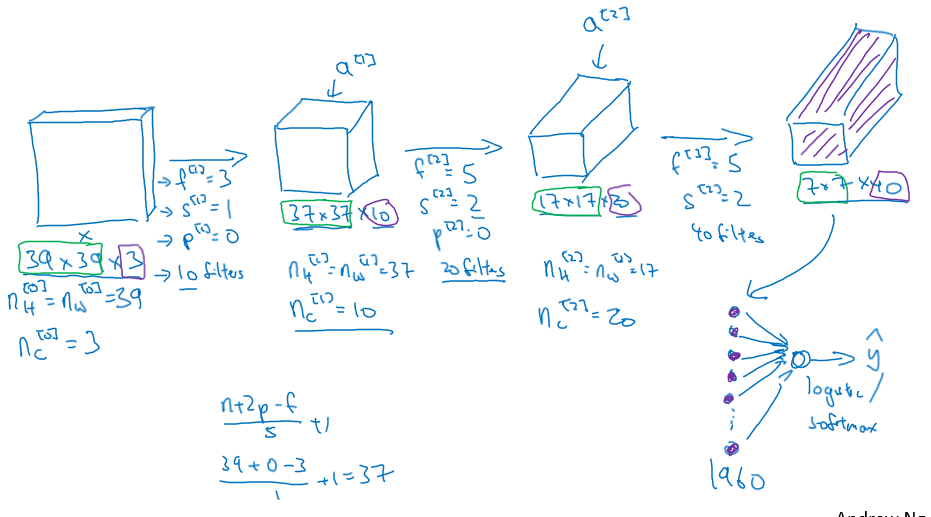
E) Simple CNN Example
CNN 은 총 3 개의 layer 로 구성된다.
-
- convolution (CONV)
-
- pooling (POOL)
-
- Fully Connected (FC)
다음은 Convolution Neural Network 의 단순한 예제다. 위의 Notation 을 이용하여 수식이 맞는지 적용해보자.
pooling layer
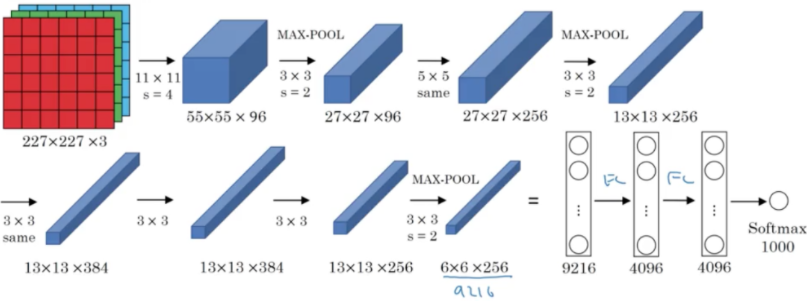
AlexNet 예시
F) Convolution 의 특징 2 가지
- Parameter sharing
- 이미지의 특정 부분 (part) 에서 사용되는 필터가 그 이미지의 다른 부분에서도 사용됨
- Sparsity of Connections
- 각 layer 의 각 출력은 오직 전체 입력 중 일부에만 독립적으로 의존함.
- 위 두 가지 특징 예시
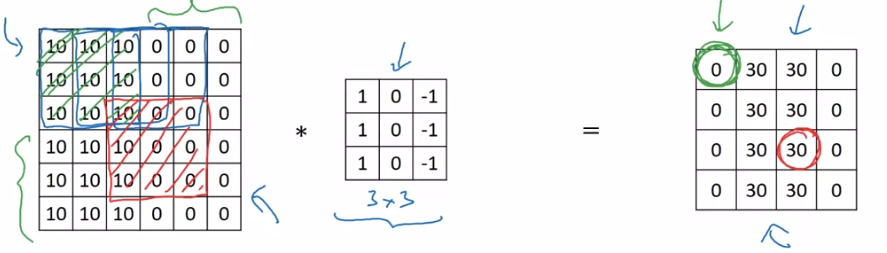
- Parameter sharing
- output 값 중 과 을 구할 때, 같은 filter 를 사용함
- Sparsity of Connections
- 을 구할 때는 image 왼쪽 상단의 부분만 이용하여 독립적으로 계산됨. 나머지는 관여하지 않음