Recurrent Neural Networks (RNN)
A.1) 왜 RNN 을 사용하는가?
일반 neural network(DNN) 보다 RNN 을 사용하는 이유는 무엇일까?
그 이유는 DNN 은 RNN 과 달리 parameter sharing 이 가능하지 않기 때문이다.
즉, RNN 은 여러 time steps 에 걸쳐서 동일한 가중치를 공유한다. 예를 들어, 와 가 비슷한 의미의 token 이여도, 이를 generalize 할 수 없다.
입력과 출력의 크기가 examples 마다 길이가 다를 수 있는데, DNN 은 이를 처리하지 못한다. 반면, RNN 은 이를 time step 형식으로 쪼개서 처리할 수 있다.

아래는 RNN diagram 을 단순화 한 것이다.
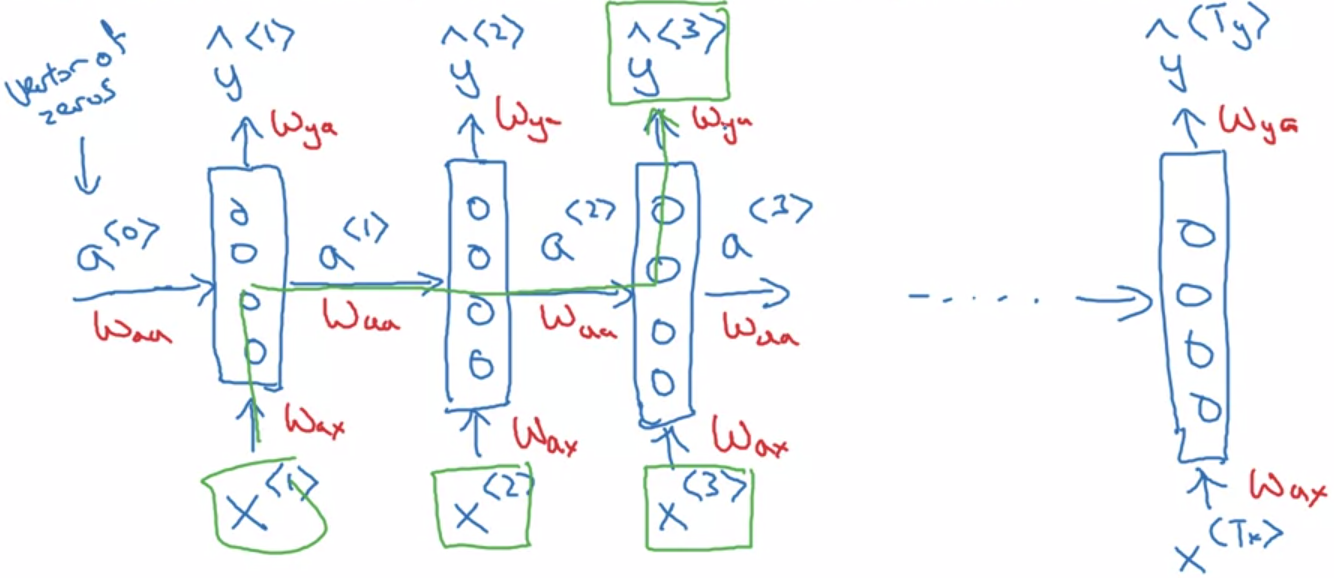
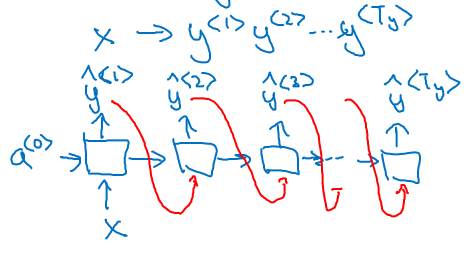
A.2) RNN forward Propagation
문장의 번째를 나타내는 는 One Hot Encoding 또는 Word Embedding 의 결과 vector 인데 ,예를 들면 아래와 같다.

에서 사용하는 activation function 은 tanh function 또는 ReLU function
그리고 에서 사용하는 activation function 은 sigmoid function 또는 softmax function
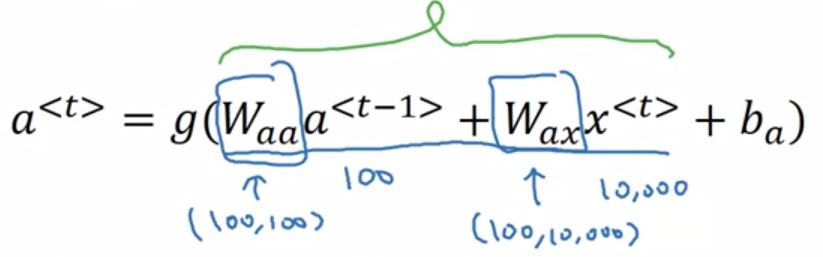
A.2.1) RNN forward 식의 Simplification
는 다음과 같이 좀 더 축소시켜서 표현할 수 있다.
왜 이렇게 축소될까? 각 weights 와 를 행렬 내부에서 이어붙였기 때문이다 ( 로 통일).
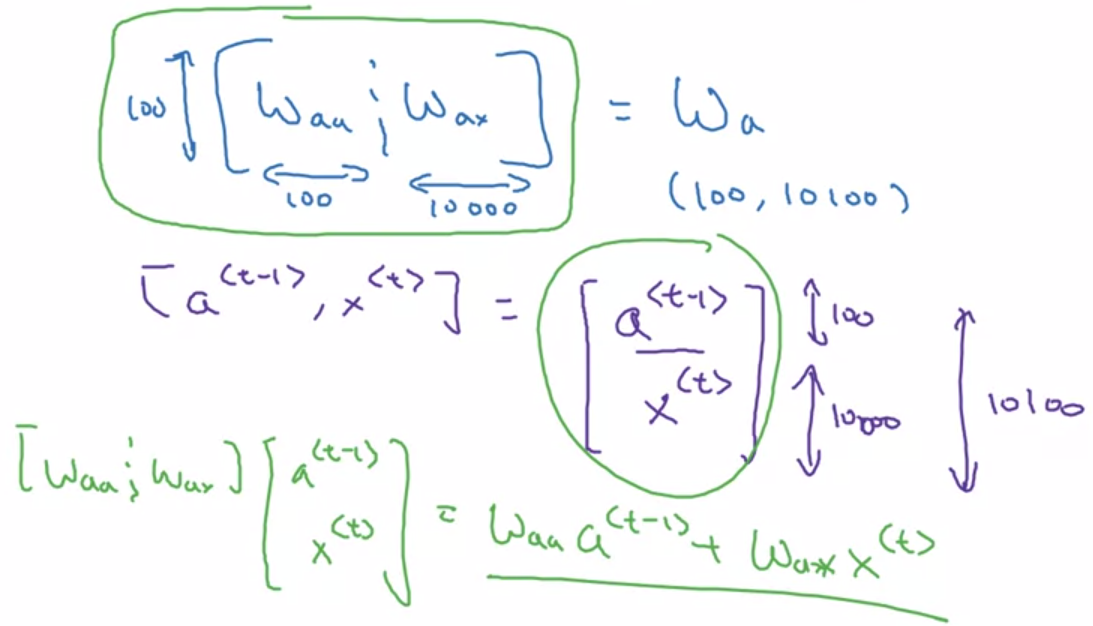
B) RNN 의 단점
문장의 단어를 학습할 때, 해당 단어의 뒤에 있는 단어들은 prediction 에 활용할 수 없다: only use earlier words of sequence
이를 보완하기 위해 나온 모델이 BRNN 다.
C) Examples of RNN
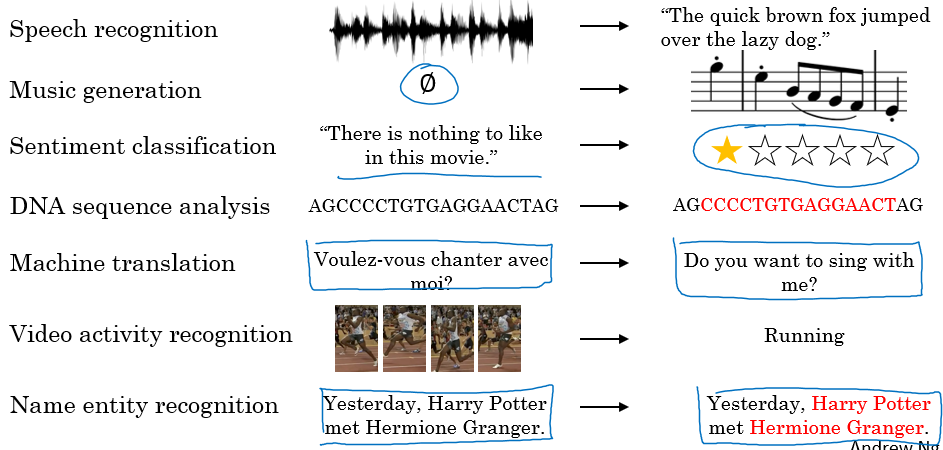
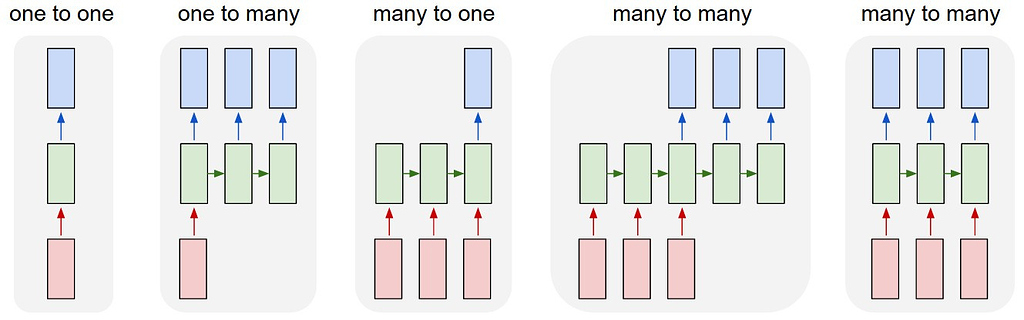
C.1) One-to-many Example (Music Generation)
- (무에서 유를 창조하는 느낌)
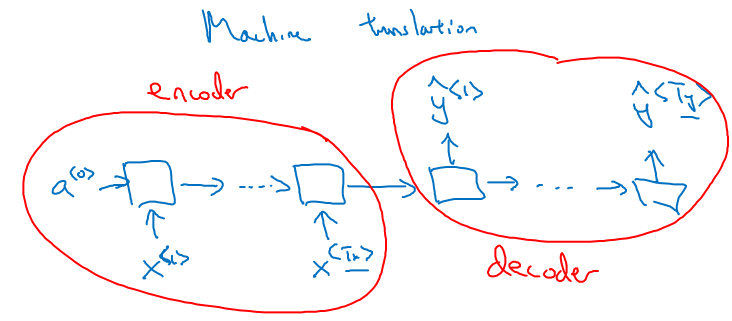
C.2) Many-to-many Example (Machine Translation)
D) Language Modeling with an RNN
training 및 sampling of language model
- Training set 으로 주어진 문장들을 tokenize 한다.
- Example: large corpus of English text
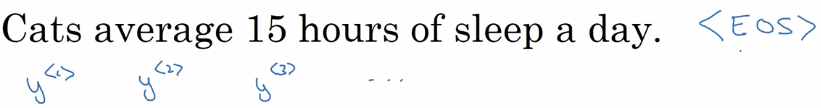
- 각각의 단어들을 one-hot vector 로 변환시키고, 마지막에
<EOS>구문을 넣음위 문장은<EOS>를 포함하여 총 9 개의 token 으로 구성됨 (마침표 제외)
- 각각의 단어들을 one-hot vector 로 변환시키고, 마지막에
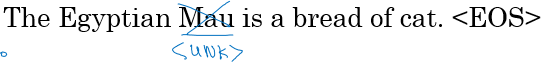
- token 화 하기 어려운 단어 (위 그림의
Mau) 들은<UNK>라는 unknown word 표시로 tokenize
- token 화 하기 어려운 단어 (위 그림의
- Tokenize 된 token 들을 RNN 에 넣고 학습
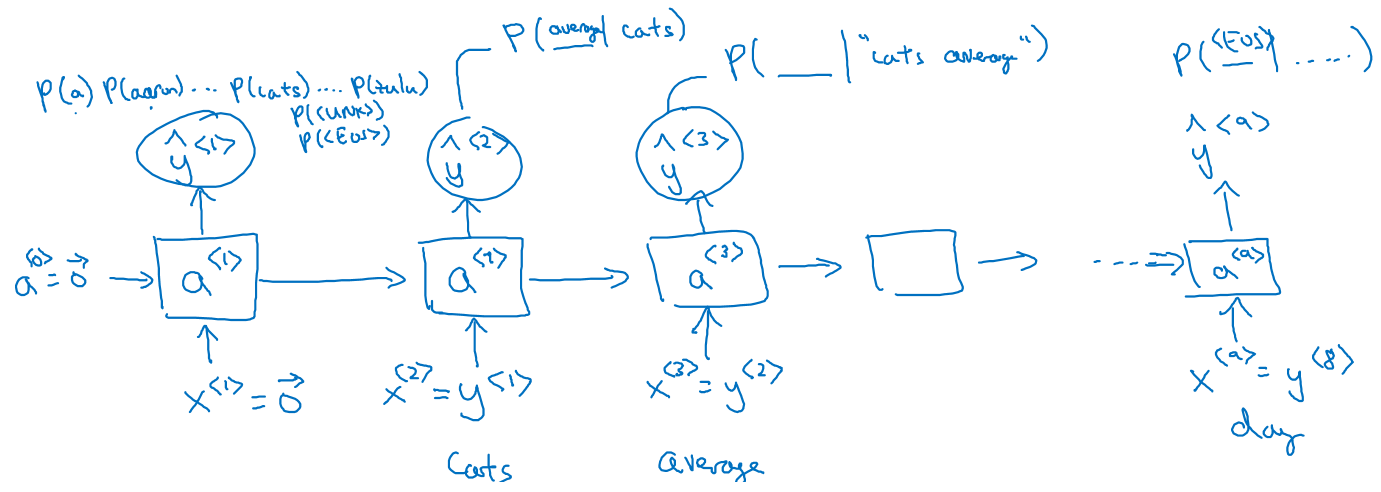
- 학습 문장:
Cats average 15 hours of sleep a day. <EOS> - token 를 입력으로 넣을 때, 바로 다음 단어가 Cats 일 확률은
- token 를 입력으로 넣을 때, 바로 다음 단어가 일 확률은
- RNN 의 출력이 순서대로 가 나올 확률:
- 위와 같은 확률들은 softmax function 으로 표현되며, loss function 은 아래와 같이 cross-entropy 형태로 계산된다.
- 학습한 RNN 을 이용한 sampling a sequence
- training 과 sampling 은 prediction 값 를 의 input 으로 쓰느냐 마느냐의 차이가 있다.
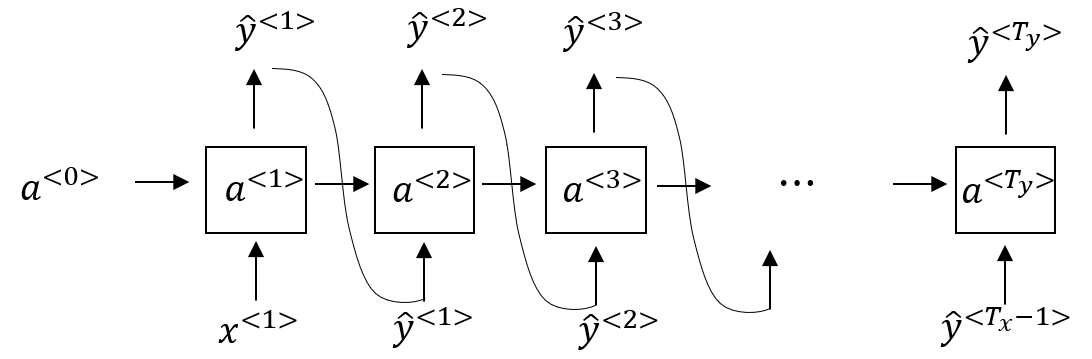
- 그림과 같이 초기 token 은 zero vector 로 입력 후, 출력 vector 를 이용하여 출력 값을 정한다.
- 는 [SoftMax](softmax function) 를 이용하여 확률 벡터로 치환된 후, 그 확률 중에서 임의로 word 또는 character 를 선택한다.
- 그리고 출력 vector 는 그 다음 출력 vector 를 위한 입력 vector 로 들어가게 된다.
- 이와 같은 작업을 반복하여 출력 vector 가
<EOS>로 선택되거나, 미리 정의된 sampling 횟수 이상을 출력한다면 중지한다.
E) Character-level Language Model
문자 - 수준 언어 모델은 단어 수준 언어 모델과 달리, 말 그대로 매 출력마다 어느 문자가 나올지에 대한 확률을 이용하는 모델이다.
즉, token 을 담은 Vocabulary 가 [a, aaron, …, zulu, <UNK>] 와 같지 않고, [a,b,c,d, .., z, ; , 0, 1 …] 와 같은 단일 문자로 여겨진다.
장점
- 단어를 tokenize 하지 않기 때문에, 알려지지 않은 단어 (e.g. Mau) 에 강하다.
단점
- 문장이 길어지면 vanishing gradients 문제에 취약하다.
- 즉, 문장 내부의 종속성을 찾아내는데 취약하다
- computationally expensive: 단어 수준 언어 모델과 비교해서 학습과 sampling 에 매우 많은 비용이 요구된다.
F) RNN Variants
F.1) Gated RNNs
- Gated Recurrent Unit (Gated Recurrent Unit)
- Long Short Term Memory (Long Short-Term Memory)