Negative Sampling
Negative Sampling 은 skip-gram 모델의 softmax 함수 계산 비용을 절약하기 위해 고안된 Word Embedding 방식이다.
기존에는 context word 를 입력받고, target word 에 대한 multi-classficiation 으로 학습을 진행했다면, negative sampling 은 binary classificationion 방식으로 학습을 진행한다.
즉, 데이터를 생각해보면 (target, sampled context) 은 input 이 되고, label 은 1 또는 0 이 되는 것이다. “context 가 있을 때 target 이 함께 있어도 말이 되는가?” 라는 질문에 대해서 예 (1), 아니오 (0) 라는 해석으로 생각할 수 있다.
총 개의 target 단어에 대해서 학습할 때, skip-gram 은 만큼의 softmax 값을 계산해야 하지만, negative sampling 방식은 번의 binary classfication (cross-entropy) 학습을 진행하면 되므로, 계산량이 현저히 줄어든다.
B) 예시
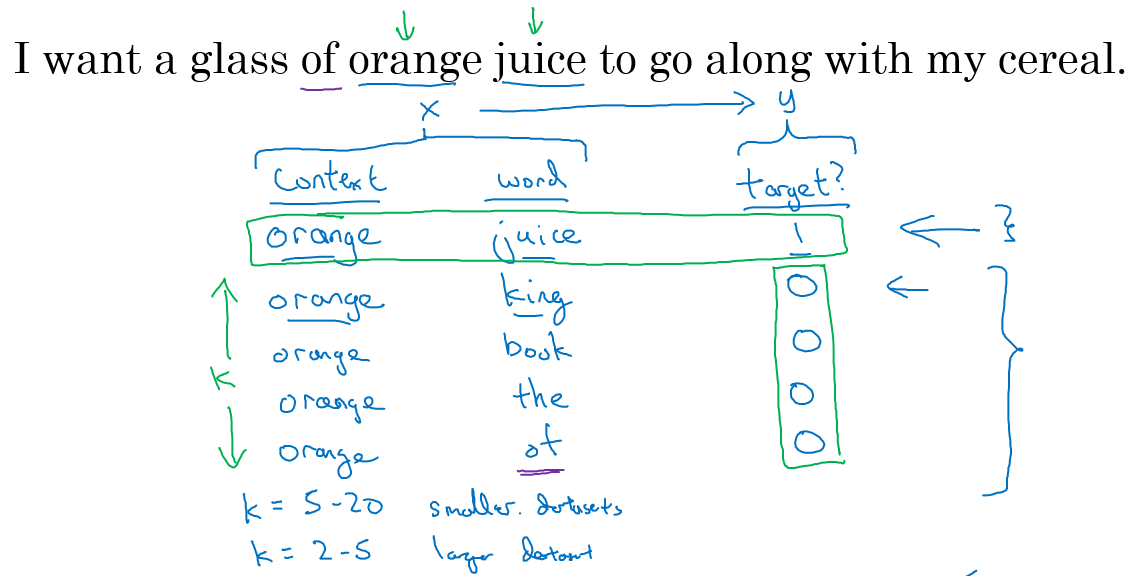
그림과 같이 skip-gram 의 (orange, juice) pair 에 대한 학습 과정에서, 만큼 orange 의 window 내에 등장하지 않는 단어들을 뽑아서 binary classification 학습 데이터를 구성한다.
일반적으로 dataset 이 크면 는 25, 작으면 는 520 정도로 구한다고 한다.
정확히는 매 target 단어마다, positive example 하나, 개의 negative example 에 대해서 이진 분류 학습을 진행한다.
C) Selecting Negative Examples
개의 단어는 어떻게 결정하는가?
일반적으로 단어 빈도수를 이용한 휴리스틱 방식을 활용하는데, 특정 단어가 negative example 로 뽑힐 확률은 다음을 이용해서 계산한다:
- 는 해당 단어에 대한 사전 또는 corpus 에서의 빈도수를 의미한다.