t-SNE
t-Stochastic Nearest Embedding 는 vector visualization 을 위하여 자주 이용되는 차원 축소 알고리즘이다.

차원 축소에 관련된 알고리즘은 autoencoder, Principal Component Analysis 등 다양하게 존재한다.
하지만, t-SNE 는 Transductive 학습 모델이고, 나머지 autoencoder 와 Principal Component Analysis 는 Inductive 학습 모델이라는 특징을 지니고있다. t-SNE 는 Locally Linear Embedding) 라는 차원 축소 방법과 비슷하다.
B) t-SNE 내 정의된 두 유사도
t-SNE 는 원 공간에서의 데이터 간 유사도 에 가장 가깝도록 Embedding 공간에서의 데이터 간 유사도 를 학습한다. 정확히는 를 정의하는 를 학습하는데, 이는 정답지 를 보면서 의 위치를 이동하는 것과 같다.
- 원 공간에서의 데이터 간 유사도
- 어느 점 에서 로 이동할 확률을 의미. 즉,
- 와 가 가까울 수록 높은 확률을 가짐
- 유사도 식이 negative exponential 을 포함하고 있음을 확인하자
- 는 와 다를 수 있음 (대칭이 아님)
- 이를 위해 다음을 정의한다:
- 모든 점 마다 가 다른 이유는 outlier 에 robust 한 확률 값 를 찾기 위해서다.
- 어떤 점 사이가 매우 거리가 멀면 는 매우 커지는데, 이때 값도 같이 커진다.
- 그래서 값은 작아진다.
- Embedding 공간에서의 데이터 간 유사도
임베딩 공간에서의 두 점 간의 유사도 를 나타내며, 가까울 수록 값이 커짐 (역수) (0 의 역수는 무한대에 가까우므로 이를 방지하기 위해 1 을 넣어줌)
C) Application
Word Embedding 을 쉽게 시각화 하기 위하여 사용한다.
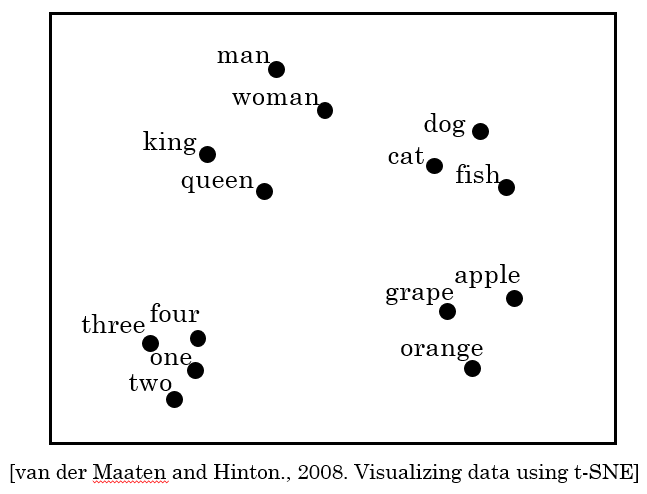
D) t-SNE 장점
t-SNE 는 데이터의 특징을 추출하거나 시각화할 때 매우 강력한 알고리즘입니다. 특히 기존의 선형 변환 방식인 PCA(주성분 분석) 와 비교했을 때, 몇 가지 중요한 이점이 있습니다.
- 데이터 뭉개짐 문제 해결: PCA 와 같은 선형 변환 방법은 데이터를 저차원으로 임베딩할 때 정보가 겹쳐져서 뭉개지는 현상이 발생할 수 있습니다. 그러나 t-SNE 는 비선형적인 방식으로 데이터를 처리하여 이러한 문제를 해결합니다.
- crowding 문제 해결: 기존 SNE 방법에서는 저차원 임베딩에서 정규분포 (가우스 분포) 를 사용했기 때문에 특정 거리 이상부터 학습에 반영되지 않는 문제가 있었습니다. 하지만 t-SNE 는 저차원 임베딩을 t 분포 기반으로 하기 때문에 이러한 crowding 문제를 효과적으로 해소합니다.
- Hyperparameter 에 덜 민감함: 다른 차원 축소 알고리즘과 비교했을 때, t-SNE 는 hyperparameter 설정에 크게 영향을 받지 않으며, 이상치 (outlier) 에 둔감하다는 장점이 있습니다.
E) t-SNE 단점
물론, t-SNE 에도 몇 가지 단점이 존재합니다.
-
연산 시간이 오래 걸림
- 데이터 개수가 많아질수록 연산량이 기하급수적으로 증가합니다. 데이터 개수가 n 일 경우 연산량은 로 늘어나며, 이로 인해 시간이 너무 오래 걸리는 문제가 발생합니다.
- 이를 해결하기 위해 최근에는 UMAP 과 같은 대안 알고리즘이 사용되기도 합니다.
-
높은 차원의 데이터를 바로 축소하기 어려움
- 매우 높은 차원을 가진 데이터를 바로 2 차원이나 3 차원으로 축소하는 것은 어렵습니다.
- 일반적으로 128 차원의 raw 데이터를 autoencoder 등을 통해 먼저 32 차원 정도로 줄인 후, 그 다음에 t-SNE 를 적용하여 2~3 차원으로 축소하는 방식이 많이 사용됩니다.
- 보통 raw data 를 약 50 차원 이하로 압축한 후에 t-SNE 를 사용하는 것이 일반적입니다.
-
결과의 일관성 부족
- 매번 실행할 때마다 다른 시각화 결과가 나오는 경향이 있습니다 (t-SNE 는 training 과 prediction 을 동시에 수행하기 때문).
- 이로 인해 학습 과정에서 활용하기 어려울 수 있으며, 이를 방지하려면 seed 값을 고정하여 결과값의 일관성을 유지해야 합니다.
-
정보 손실 가능성
- 저차원 임베딩 과정에서 일부 정보 손실이 발생할 수 있으며, 이는 데이터 왜곡 가능성을 높일 수 있습니다.