Abstract
transformer 구조를 제안: attention 메커니즘에 기반한 구조로, convolution 또는 recurrence 에 적용 가능
B) Introduction
기존 Gated Recurrent Unit, Long Short-Term Memory 같은 recurrent model 은 sequential 학습 방식으로 병렬적인 학습이 불가능했음
본 논문에서 제안한 Transformer 모델은 recurrence 방식에서 탈피하면서 병렬 학습이 가능하고, input 과 output 의 global dependency 들을 이끌어낼 수 있는 attention 메커니즘 구조임
C) Model Architecture
Model Figure

C.1) Encoder and Decoder Stacks
C.1.1) Encoder
6 개의 동일한 레이어들로 이루어져 있고, 각 레이어는 두개의 sub-layers 로 구성되어 있음 하나는 multi-head self-attention 메커니즘이고, 다른하나는 position-wise fully connected FFN(feed-forward network) 이다. 두 sub-layers 에 각각 layer normalization 이후 residual connection 를 적용했다. 즉, 각 sub-layer 의 출력은 와 같다. 여기서 는 sub-layer 자체 function 이다.
C.1.2) Decoder
encoder 와 동일하게 6 개의 동일한 레이어로 이루어져있고, 각 레어이는 세개의 sub-layer 로 이루어져 있다.
-
encoder 의 두 sub-layer 에다가 encoder stack 의 출력에 multi-head attention 을 적용하기 위한 layer 를 추가했다. attention function
-
Scaled Dot-Product Attention
D) Multi-Head Attention
하나의 attention function 을 이용하는 것보다, 개의 서로 다른 linear projection 들을 동시에 (병렬적으로) attention 결과를 계산하는 방법
개의 values, keys, queries vector 를 계산하고, 번 Scaled dot-product attention 을 수행한다. 이후 얻어진 의 output vector 들을 concat 하고 한번 더 projection 하여 최종 output 을 얻어낸다.
각 projections 들은 parameter matrices 로, 그리고 와 같다.
- attention layers
- paper 의 값은 8 로, computational cost 를 full dimensionality 를 가진 single-head attention 과 비슷하게 맞추려고 했다고함
Comparison of two attentions
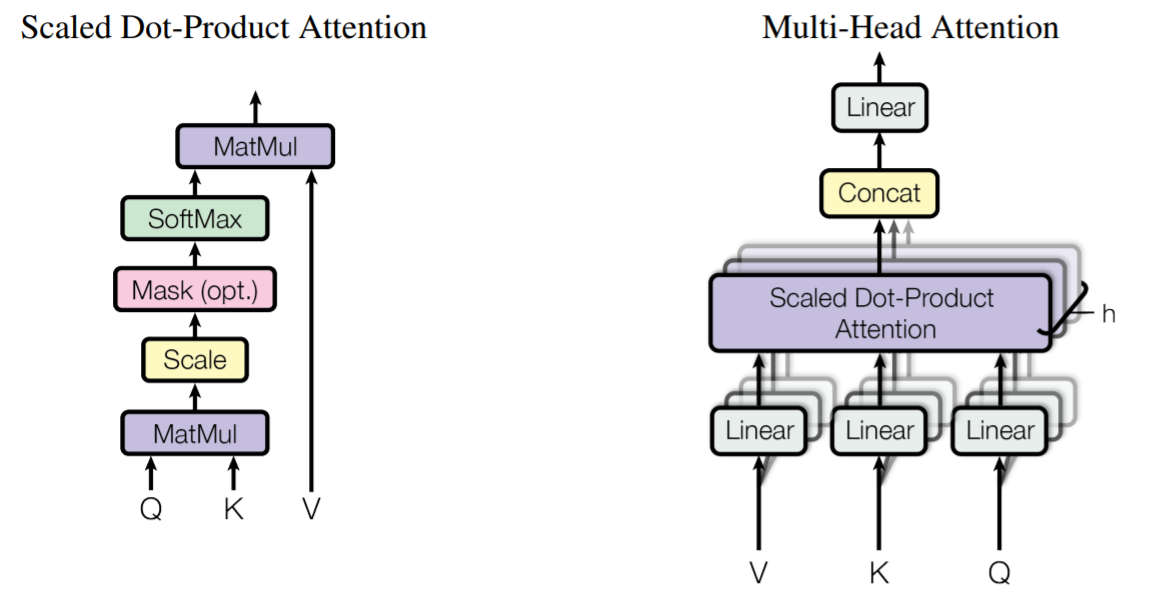
- Applications of Attention: Transformer 는 multi-head attention 을 세가지 방법으로 사용한다.
E) Related
- paper: https://arxiv.org/pdf/1706.03762.pdf
- implementation & some explanation: http://nlp.seas.harvard.edu/2018/04/03/attention.html