Transformer
트랜스포머 (Transformer) 는 2017 년 구글이 발표한 논문인 “Attention Is All You Need” 에서 나온 모델
기존의 seq2seq 의 구조인 인코더 - 디코더를 따르면서도, 논문의 이름처럼 어텐션 (attention) 만으로 인코더와 디코더를 구현한 모델이다. 즉, RNN 보정을 위한 용도가 아니라 어텐션을 독자적으로 활용하는 것을 목적으로 한다.
B) Motivation
RNN 에서 LSTM 으로 넘어가면서 시퀀스 모델의 성능은 향상되었지만, 모델의 복잡도는 올라간다. 그리고 데이터 flow 가 sequential 하다 보니, 정보의 흐름에서 bottleneck 이 발생할 수 밖에 없다.
transformer 는 병렬로 시퀀스 데이터를 처리하기 때문에 훨씬 속도가 빠르며 성능도 좋다.
C) Core Idea of Transformer
attention 에 CNN 스타일을 합친 네트워크 구조를 지닌 transformer 는 다음과 같은 두 가지 핵심 아이디어를 기반으로 한다.
- self-attention
- multi-head attention
C.1) Self-attention
주어진 문장의 토큰 (e.g. 단어) 들에 대한 attention value 를 구하는 방법을 의미한다. 이때 각 토큰의 attention value 는 해당 토큰과 다른 토큰 간 관계를 생각했을 때 얼마나 많은 정보를 담고 있는지를 나타낸다.
각각의 토큰들은 attention 함수에 들어가는 query, key, value 벡터들로 구성되며, 각 벡터들은 weight matrix 를 통해 구해진다. 예를 들어, 세번째 토큰 에 대한 query 는 와 같이 계산될 수 있다.
각 토큰의 attention value 를 구할때, 그 토큰의 query 와 다른 토큰의 key 에 대한 vector 간 내적값을 구한다. 이렇게 해서 주어진 토큰을 잘 설명할 수 있는 시퀀스 내 또 다른 토큰을 찾는다. 물론 자기 자신에 대한 내적값도 계산한다 (e.g. ). 이후 내적값 (정확히는 softmax 값) 에 토큰 별 value vector 를 곱한 뒤 모두 더하면, 해당 벡터가 attention value 를 표현하는 vector 가 된다.
각 토큰의 attention vector 를 수식으로 표현하면 다음과 같다:
C.1.1) Self-attention 직관적 이해
어떤 토큰을 잘 설명할 수 있는 토큰이란것이 어떤 의미인지 예시로 알아보자. 예를 들어, “ 제인은 9 월에 아프리카를 방문했다.” 라는 문장이 있는 경우, “ 아프리카 ” 라는 단어 (토큰) 를 가장 잘 설명해줄 수 있는 또 다른 단어는 “ 방문했다 ” 라는 동사일 것이다.
C.2) Multi-head Attention
여러 head 마다 토큰의 query, key, value vector 를 따로 생성하여 self-attention 을 수행하는 방식을 의미한다. 즉, 개의 head 가 존재한다면, 각 토큰마다 총 개의 query, key, value vector 가 존재하고, 이는 각 head 의 weight matrix 를 곱해서 구해진다 (e.g. ). 기존의 self-attention 에서 사용하는 vector 들을 구할 때도, 각 query, value, key 에 대한 weight matrix 를 곱했다면, 여기서 한번 더 head 의 weight matrix 를 곱해주는 것이다.
각 head 에 대한 vector 들을 구했다면, 동일하게 각 head 에 대한 attention vector 를 구할 수 있다.
그리고 그 벡터들을 concatenate 하여 긴 벡터를 만들고, 이를 output weight matrix 에 곱해서 최종적인 결과값을 얻을 수 있다:
그리고 그 벡터들을 concatenate 하여 긴 벡터를 만들고, 이를 output weight matrix 에 곱해서 최종적인 결과값을 얻을 수 있다:
그리고 그 벡터들을 concatenate 하여 긴 벡터를 만들고, 이를 output weight matrix 에 곱해서 최종적인 결과값을 얻을 수 있다:
D) Transformer 구조
Transformer 는 여러 개의 인코더와 디코더가 개의 단위로 구성된 구조를 가지고 있습니다.
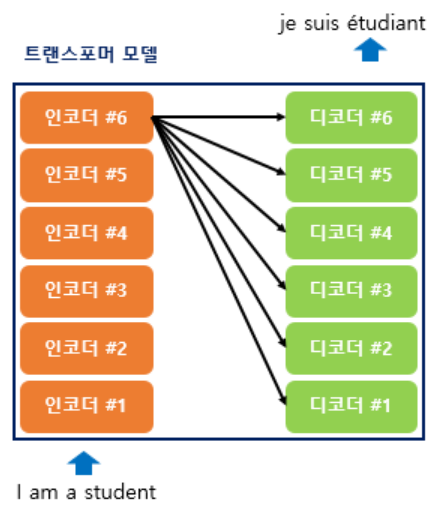
D.1) 주요 Parameter
- : 트랜스포머 인코더와 디코더에서 입력과 출력의 크기를 나타냅니다.
- num of layers: 인코더와 디코더에 포함된 레이어의 수를 의미합니다.
- num of heads: 멀티헤드 어텐션에서 사용되는 헤드의 수입니다.
- : 트랜스포머 내부 feed forward 네트워크에서 hidden layer 의 크기를 나타냅니다.
D.2) Transformer 특징
D.2.1) 포지셔널 인코딩 (Positional Encoding)
Transformer 는 RNN 과 달리 단어를 순차적으로 입력받지 않기 때문에, 각 단어의 위치 정보를 모델이 이해할 수 있도록 임베딩 벡터에 위치 정보를 더해줍니다. 이를 통해 모델은 입력 데이터 내에서 각 단어가 어떤 순서에 있는지를 파악할 수 있습니다.
아래 그림은 positional encoding 이 더해지는 과정을 시각화한 것입니다:
![]()
![]()
E) “Pre-norm” Architecture
A “Pre-norm” architecture is a re-ordering of the transformer model’s operations which makes it mathematically cleaner to reliably train. This correction was proposed by a number of groups, including a collaboration between Chinese academics and Microsoft Research Asia.