seq2seq
B) Application of seq2seq Model
Translation
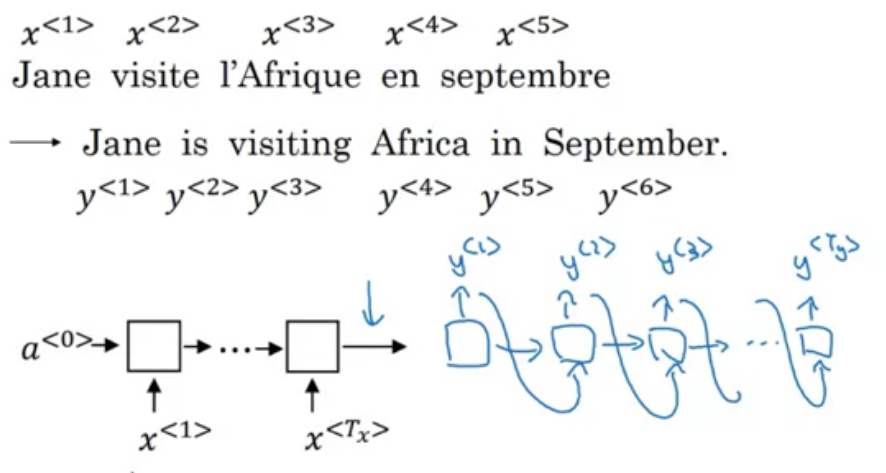
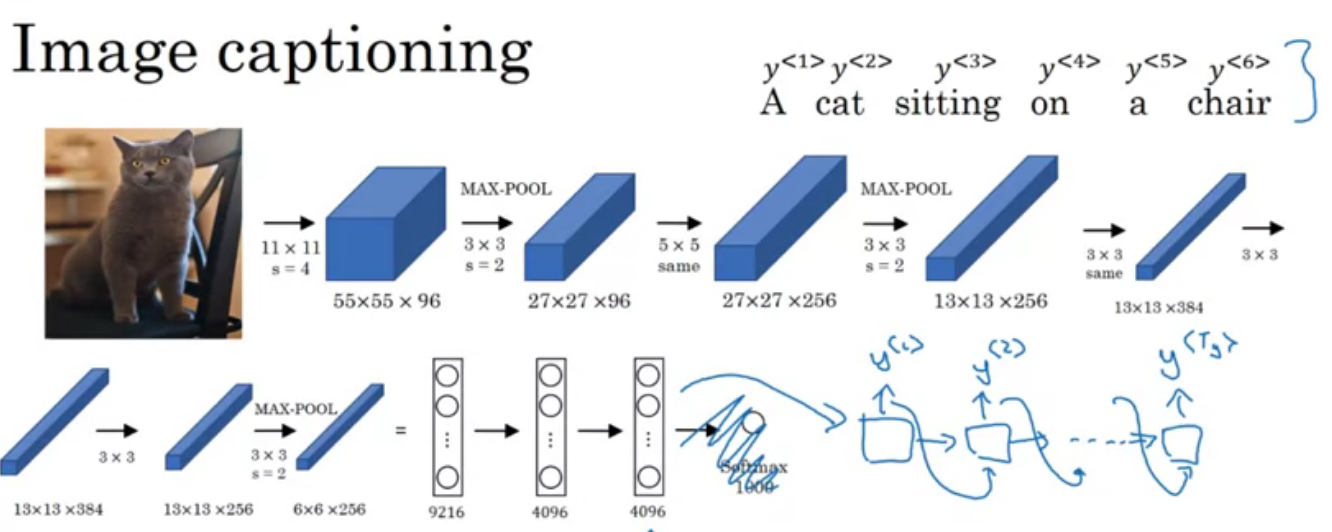
Image captioning: Example of the Alexnet
C) 일반적인 Language 모델과의 비교
- 일반적인 language 모델과 달리, 주어진 입력이 zero vector 가 아니라, encoder 의 output vector 이므로, 이는 conditional language model 이라고 생각해볼 수 있다.
- 즉, 으로 표현할 수 있는데, 여기서 는 encoder 의 output 그리고 는 decoder 의 output 이다.
- 최종 목적은 likelihood 를 maximize 하는 것이다.