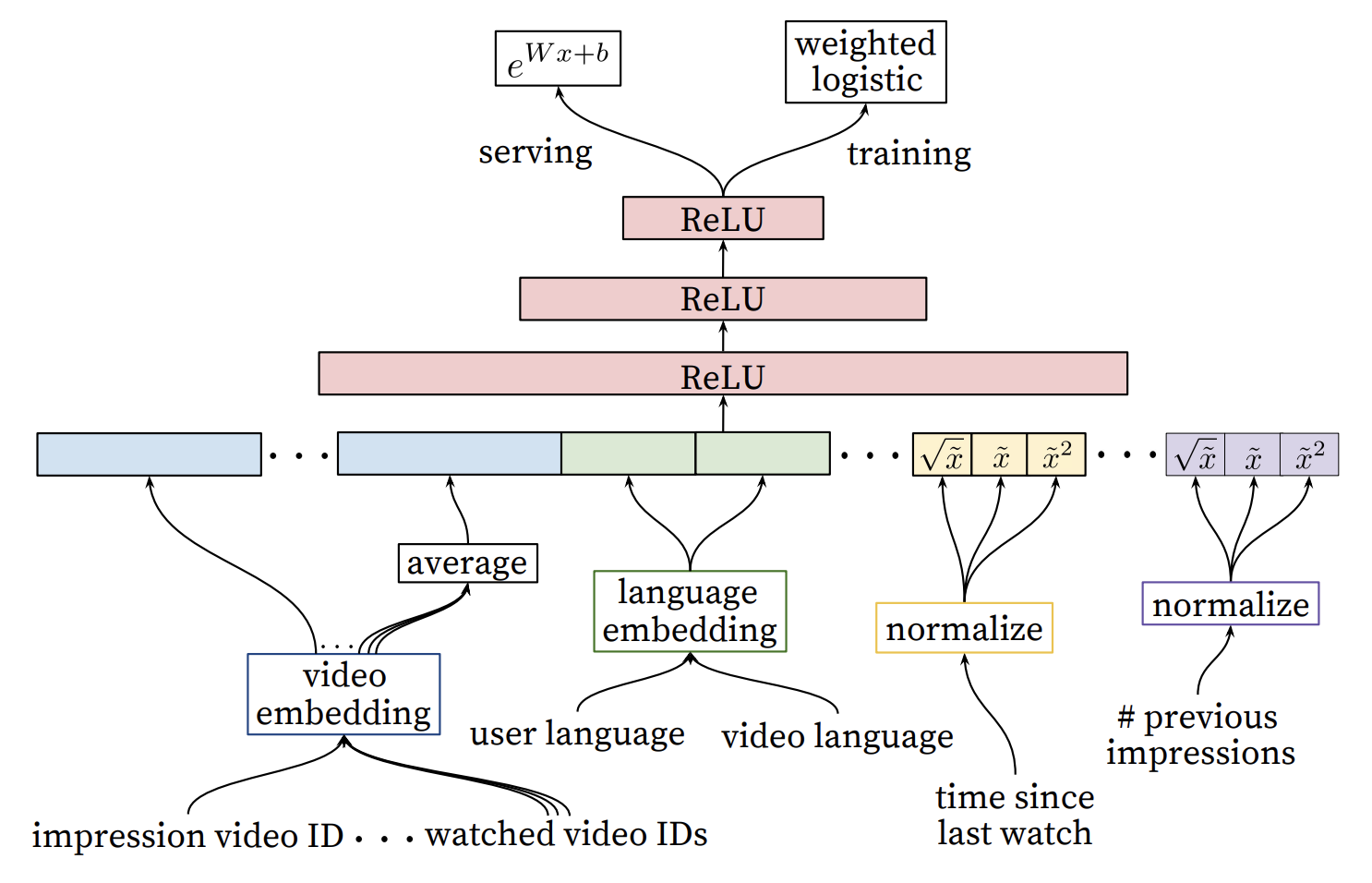
continuous bag of words language models 로 부터 영감을 받음
사용자의 시청 기록이 video ID 의 시퀀스로 표현되고, 이것이 embedding 을 통해 dense vector 로 표현됨
계산된 embedding 들은 mean-vector 를 통해서 신경망의 입력으로 활용된다.
sum, component-wise max 등 보다 average 가 제일 성능이 좋았음
Heterogeneous Signals
Example Age Feature
새로운 콘텐츠에 대한 추천이 필요하지만, 일반적으로 ML 시스템은 과거 히스토리에 암묵적인 bias 가 있을 수 밖에 없음 (과거 데이터를 활용해 미래를 예측하기 때문)
그러나 비디오에 대한 인기 정도의 분포는 non-stationary 하기 때문에, 이를 correct 할 필요가 있는데, 해당 이슈를 다루기 위해 training example 의 age를 feature 로 입력한다.
serving 시, 해당 값은 0 (또는 약간 음수 값) 으로 설정하여 모델이 training window 의 막바지에서 추천을 진행한다는 신호를 보냄
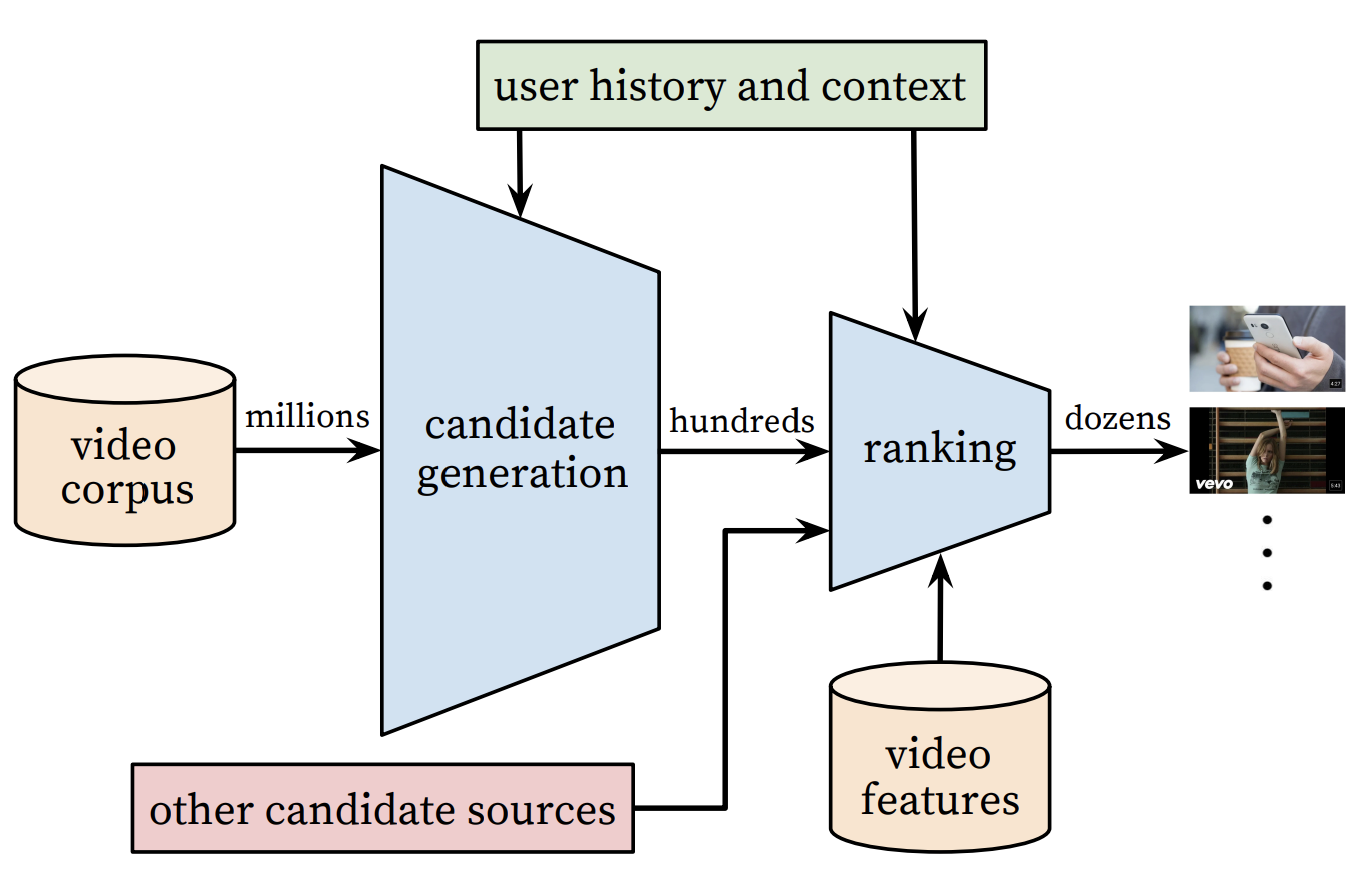
Ranking
a deep neural network with similar architecture as candidate generation to assign an independent score to each video impression using logistic regression
expected watch time per impression 을 기준으로 A/B test 진행
CTR 의 경우는 낚시성 비디오들을 promote 해주는 경향이 있기 때문에 시청 시간 (watch time) 이 사용자의 흥미를 잡아내는데 더 나음