한줄 요약
Alibaba 규모의 추천 플랫폼에서 cold item의 생태계 부스팅 을 위한 end-to-end 프레임워크. Tiered Boosting (단계적 노출 예산 할당) + Stacking Fine-Tuning Cold Predictor (cold CTR 예측) + Item-Oriented Bidding (입찰 기반 노출 최적화) 세 가지 핵심 모듈로 구성된다. 180일 기준 cold item의 클릭 +76%, GMV +72% 개선, 플랫폼 전체로도 클릭 +4.51%, GMV +4.69% 향상을 달성했다.
- 저자: Qijie Shen, Yuanchen Bei, Zihong Huang, Jialin Zhu, Keqin Xu, Boya Du, Jiawei Tang, Yuning Jiang, Feiran Huang, Xiao Huang, Hao Chen
- 학회: KDD 2025 (Toronto)
- 플랫폼: Taobao (알리바바), 일 3억 유저, 100만 신규 아이템, 100억 인터랙션
B) 전체 구조
┌─────────────────────────────────────────────────────────────────┐
│ [입력] │
│ 신규 Cold Item ──┐ │
│ Foundation CTR ──┤ │
│ ▼ │
│ [Potential Prediction] │
│ ┌──────────────────────────────────┐ │
│ │ Stacking Fine-Tuning Cold Pred. │ │
│ │ ▼ │ │
│ │ P40 Percentile Ranking │ │
│ │ ▼ │ │
│ │ 초기 Stage 배정 (1/2/3) │ │
│ └──────────┬───────────────────────┘ │
│ ▼ │
│ [Tiered Boosting Structure] │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Stage 1 (Budget 소) │ │
│ │ ├── CTR ≥ γ¹ × Category CTR ──→ Stage 2 (중) │ │
│ │ └── CTR 미달 ──→ EXIT │ │
│ │ Stage 2 (Budget 중) │ │
│ │ ├── CTR ≥ γ² × Category CTR ──→ Stage 3 (대) │ │
│ │ └── CTR 미달 ──→ EXIT │ │
│ │ Stage 3 (Budget 대) ──→ 완료 │ │
│ └──────────┬───────────────────────────────────────┘ │
│ ▼ │
│ [Item-Oriented Bidding] │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Bid = CTR Prediction │ │
│ │ Price = P40 × Speed Factor × User Pref Factor │ │
│ │ │ │
│ │ Bid > Price? ──YES──→ Boosting 노출 │ │
│ │ NO──→ 노출 안 함 │ │
│ └──────────┬───────────────────────────────────────┘ │
│ ▼ │
│ [출력] │
│ Boosting 노출 ──→ Natural 추천 증폭 (α × CTR_boost) │
└─────────────────────────────────────────────────────────────────┘
핵심 흐름:
- 신규 아이템이 들어오면, Stacking Fine-Tuning Cold Predictor 가 Foundation CTR 모델 위에 cold-specific feature를 결합하여 CTR을 예측
- P40 percentile 기반으로 아이템의 잠재력(potential) 을 평가해 초기 Stage 배정
- Tiered Boosting 에서 각 Stage마다 점진적으로 증가하는 예산을 할당하고, CTR 성과에 따라 승격/퇴출
- 실제 노출은 Item-Oriented Bidding 으로 결정: bid(CTR 예측값)이 price(기준가 × 속도 × 유저 선호)보다 높으면 노출
- Boosting 노출의 CTR이 좋으면 자연 추천(Natural Rec.)에서도 증폭 효과 발생
C) 배경 지식
C.1) Cold-Start Problem in Recommendation
추천 시스템에서 신규 아이템은 행동 데이터(클릭, 구매 등)가 부족하여 CTR 예측이 부정확하고, 노출 기회를 얻기 어렵다. 기존 접근법들:
| 접근법 | 방식 | 한계 |
|---|---|---|
| Contrastive Learning | warm/cold item 간 representation 정렬 | 초기 추천만 개선, lifecycle 미고려 |
| Meta-Learning | few-shot 학습으로 빠른 적응 | 생태계 전체 관점 부재 |
| Knowledge Distillation | warm model → cold model 지식 전이 | popularity bias 해결 못함 |
| LLM-based (ColdLLM 등) | 텍스트 기반 cold item representation | 대규모 시스템 배포 어려움 |
C.2) Matthew Effect (마태 효과)
“부익부 빈익빈” — 인기 아이템은 더 많은 노출 → 더 많은 클릭 → 더 많은 추천의 positive feedback loop. 신규 아이템은 이 루프에 진입하지 못해 영구적으로 묻힌다.
C.3) PID Control
공학에서 사용하는 피드백 제어 기법. Proportional(비례), Integral(적분), Derivative(미분) 세 요소로 목표값에 수렴하도록 제어한다. AliBoost에서는 budget 소비 속도를 안정적으로 조절하는 데 PID의 아이디어를 차용했다.
D) 기존 방법의 한계
AliBoost 배포 전, cold item의 41.1%가 30일이 지나도 일 노출 10회를 달성하지 못했다.
세 가지 근본 원인:
- Warm Preference Bias: 유저는 본능적으로 인기 있는(warm) 아이템을 클릭 → 추천 시스템이 이를 학습 → cold item 추천 더 줄어듬
- Insufficient Cold-Start Support: 기존 cold-start 모델들은 “초기 진입”만 다루고, 아이템이 성장하는 전체 lifecycle 을 관리하지 않음
- Lack of Incentivized Exposure: 잠재력이 높은 cold item도 초기에 노출이 부족하면 자연 추천으로 올라올 수 없음
비유하면: 기존 방식은 “신입 사원에게 이력서 쓰는 법만 알려주고 면접 기회는 안 줌”. AliBoost는 “면접 기회를 단계적으로 제공하되, 성과 기반으로 승진/퇴출을 관리”하는 것.
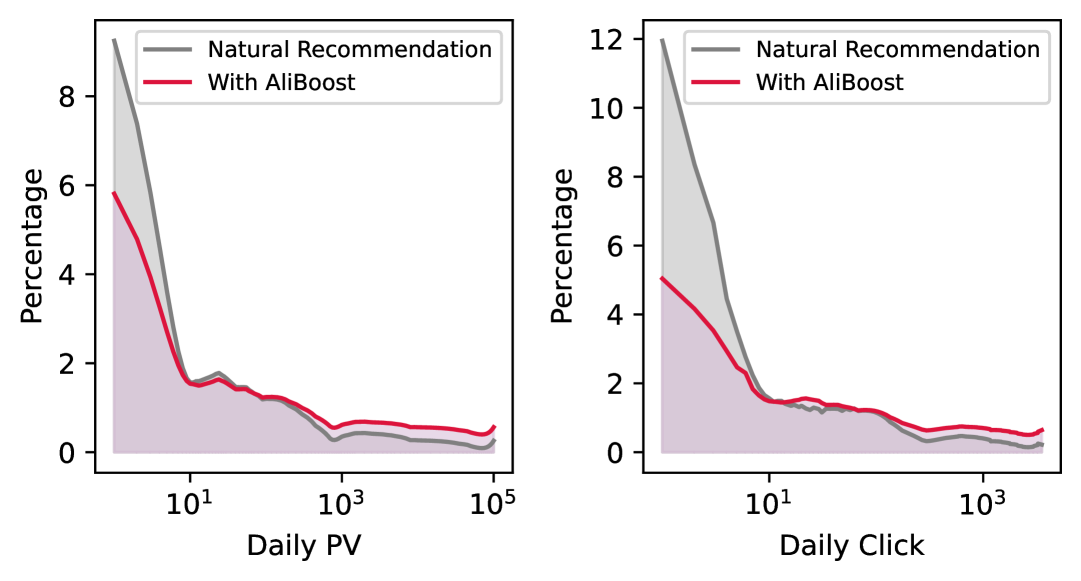 Figure 1: 자연 추천 vs AliBoost 적용 후 cold item의 일일 PV/Click 분포 변화
Figure 1: 자연 추천 vs AliBoost 적용 후 cold item의 일일 PV/Click 분포 변화
E) 제안 방법
E.1) Overall Framework 및 핵심 원칙
전체 incremental exposure 모델링:
- 부스팅으로 얻은 노출() + 그 성과로 인한 자연 추천 증폭 효과
- 는 CTR이 높을수록 지수적으로 증가 → 좋은 아이템은 자연 추천에서도 더 많이 노출
두 가지 핵심 원칙:
| 원칙 | 수식 | 의미 |
|---|---|---|
| Performance-Driven Boosting | CTR 높은 아이템에 더 많은 노출 할당 | |
| Non-Disturbance Principle | 부스팅 CTR이 카테고리 자연 CTR의 배 이상 유지 |
Non-Disturbance Principle이 중요한 이유: 부스팅이 기존 유저 경험을 해치면 안 된다. 부스팅된 아이템의 CTR이 자연 추천 CTR보다 최소 20% 높아야 한다는 안전 장치.
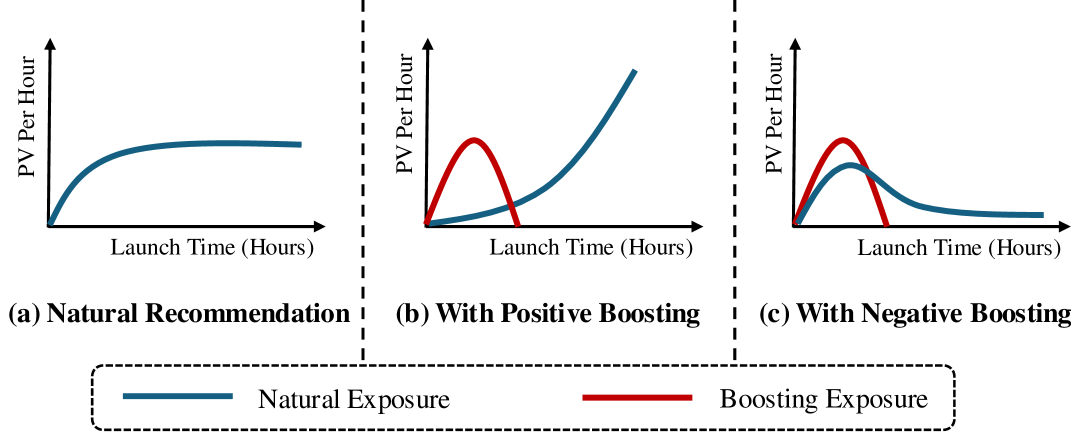 Figure 2: 세 가지 추천 상황 — (a) 자연 추천만, (b) 무분별한 부스팅, (c) AliBoost 방식
Figure 2: 세 가지 추천 상황 — (a) 자연 추천만, (b) 무분별한 부스팅, (c) AliBoost 방식
E.2) Tiered Boosting Structure
E.2.1) 핵심 아이디어
Tiered Boosting의 핵심은 “한 번에 큰 예산을 주지 않고, 소규모 테스트 → 성과 검증 → 예산 확대를 반복” 하는 것이다.
왜 이런 구조가 필요한가? cold item은 잠재력을 모른다. 모든 cold item에 동일한 대규모 예산을 주면:
- 저품질 아이템에 예산 낭비 (exit 없을 시 ROI -8.96%)
- 고품질 아이템이 충분한 예산을 못 받음 (promotion 없을 시 ROI -13.12%)
비유하면 스타트업 투자 라운드 와 같다:
- Stage 1 = Seed Round: 소규모 투자(적은 노출)로 아이템의 기본 성과 확인
- Stage 2 = Series A: 검증된 아이템에 중규모 투자, 더 엄격한 기준 적용
- Stage 3 = Series B: 고성과 아이템에 대규모 투자, 본격 스케일업
E.2.2) 구체적 동작 흐름
신규 아이템 진입
│
▼
┌─ Potential Prediction으로 초기 Stage 결정 ──────────┐
│ P40 percentile rank 기준: │
│ - 하위 70% → Stage 1 (대부분의 아이템) │
│ - 상위 70~90% → Stage 2 (잠재력 높은 아이템) │
│ - 상위 10% → Stage 3 (최고 잠재력, 바로 대규모) │
└────────────────────┬────────────────────────────────┘
▼
┌─ Stage 1: 소규모 노출 예산 (B₁) ────────────────────┐
│ - 적은 수의 유저에게 노출 │
│ - 이 Stage의 CTR 측정 │
│ - 평가 기준: CTR ≥ γ¹ × 카테고리 평균 CTR │
│ (γ¹이 가장 낮음 = 가장 관대한 기준) │
├──────────────────────────────────────────────────────┤
│ 통과 → Stage 2로 승격 │ 미달 → EXIT (부스팅 종료) │
└───────────┬───────────────┴──────────────────────────┘
▼
┌─ Stage 2: 중규모 노출 예산 (B₂ > B₁) ──────────────┐
│ - 더 많은 유저에게 노출 │
│ - 평가 기준: CTR ≥ γ² × 카테고리 평균 CTR │
│ (γ² > γ¹, 더 엄격한 기준) │
├──────────────────────────────────────────────────────┤
│ 통과 → Stage 3로 승격 │ 미달 → EXIT (부스팅 종료) │
└───────────┬───────────────┴──────────────────────────┘
▼
┌─ Stage 3: 대규모 노출 예산 (B₃ > B₂) ──────────────┐
│ - 대규모 유저에게 노출, 본격 스케일업 │
│ - 평가 기준: CTR ≥ γ³ × 카테고리 평균 CTR │
│ (γ³ > γ², 가장 엄격한 기준) │
├──────────────────────────────────────────────────────┤
│ 완료 → 자연 추천으로 전환 │ 미달 → EXIT │
└──────────────────────────┴───────────────────────────┘
E.2.3) 승격/퇴출 판단 기준
각 Stage 에서의 판단:
여기서 각 요소의 의미:
- : 아이템 가 Stage 에서 부스팅 노출을 통해 달성한 실제 CTR
- : 아이템 가 속한 카테고리의 평균 CTR (예: “여성 의류” 카테고리 전체 평균)
- : Stage 의 안전 계수.
카테고리 평균 CTR을 기준으로 쓰는 이유: 카테고리마다 CTR 수준이 다르다 (예: 식품 CTR 5% vs 가전 CTR 1%). 절대적인 CTR 임계값을 쓰면 불공정하므로, 같은 카테고리 내에서 상대 평가한다.
γ가 점점 커지는 이유: Stage가 올라갈수록 더 많은 예산을 투입하므로, 그만큼 더 높은 성과를 요구해야 예산 효율을 유지할 수 있다. Stage 1에서는 “카테고리 평균만 넘으면 OK”이고, Stage 3에서는 “카테고리 평균의 X배는 돼야 이 큰 예산을 쓸 가치가 있다”는 뜻.
E.2.4) 총 부스팅 예산
Stage를 통과할 때마다 해당 Stage의 예산 이 누적된다. 3개 Stage를 모두 통과한 아이템은 전체 예산을 받고, Stage 1에서 탈락하면 만 소비된 셈.
E.2.5) 왜 3단계가 최적인가?
| 설정 | CTR | ROI | Hot Item Count |
|---|---|---|---|
| Stage 없음 (고정 예산) | 기준 | 기준 | 기준 |
| 2 Stages | +6.23% | +6.64% | +3.63% |
| 3 Stages | +9.22% | +13.21% | +8.96% |
| 4 Stages | +9.28% | +13.46% | +8.78% |
2 → 3 Stage: ROI +6.57%p 개선. 3 → 4 Stage: ROI +0.25%p만 개선. Stage가 많아지면 검증 단계가 촘촘해지지만, 각 Stage에서 충분한 데이터를 모으기 어려워져 판단의 신뢰도가 떨어진다. 또한 운영 복잡도가 증가한다.
참고: 논문에서 stage별 구체적인 예산 크기(의 절대값), 각 γ값, stage 지속 기간은 공개하지 않았다. 알리바바 내부 운영 수치로 추정된다.
E.3) Stacking Fine-Tuning Cold Predictor
E.3.1) Stacking 구조
Foundation CTR 모델의 출력을 입력 feature로 재활용 하는 stacking 방식:
┌─ Foundation CTR Model (frozen) ──────────────┐
│ User Embedding (eᵤ) + User Features (fᵤ) │
│ Item Embedding (eᵢ) + Item Features (fᵢ) │
│ ▼ │
│ ŷ_foun (Foundation CTR) │
└──────────────┬────────────────────────────────┘
│
│ ┌─ Cold-Specific Features ────────────┐
│ │ Cold Item Embedding (eᵢ_cold) │
│ │ Boost Features (메타데이터, 컨텍스트) │
│ │ Natural Features (실시간 스트림) │
│ └───────────┬─────────────────────────┘
│ │
▼ ▼
┌─ Stacking Cold Predictor ────────────────────┐
│ Concat: [ŷ_foun, eᵤ, fᵤ, eᵢ_cold, │
│ fᵢ_boost, fᵢ_natural] │
│ ▼ │
│ MLP (L layers) │
│ ▼ │
│ ŷ_cold (Cold CTR) │
└───────────────────────────────────────────────┘
Stacked feature vector:
- 왜 Stacking인가? Foundation 모델은 전체 플랫폼 최적화된 거대 모델(0.4B 유저, 142B 인터랙션으로 학습). 이걸 fine-tune하면 warm item 성능이 떨어진다. Stacking으로 Foundation은 freeze하고 그 위에 cold-specific layer만 학습하면 두 마리 토끼를 잡을 수 있다.
E.3.2) 학습
다양한 데이터 소스 활용: e-commerce, 라이브 스트리밍, 숏비디오 등 여러 시나리오의 cold item 데이터를 함께 학습:
- : 데이터 소스별 가중치 (시나리오마다 중요도 다름)
- Binary Cross-Entropy loss 사용
E.3.3) Potential Prediction (잠재력 예측)
아이템의 초기 Stage 배정을 위해 잠재력을 정량화:
- 샘플 유저 집합 에 대해 CTR 분포 계산:
- P40 (40th percentile) 을 잠재력 지표로 사용 — 중앙값보다 보수적이어서 과대평가 방지
- P40 기반 percentile rank로 Stage 배정:
왜 P40인가? 평균이나 중앙값(P50) 대신 P40을 쓰는 이유는, cold item은 소수의 유저에게만 매우 높은 CTR을 보일 수 있어서 상위 값이 과대평가를 유발할 수 있기 때문이다. P40은 “적어도 60%의 유저에게 이 정도 성과는 낸다”는 보수적 추정.
E.4) Item-Oriented Bidding Boosting
E.4.1) 입찰 구조
각 (user, item) 쌍에 대해 입찰(bid)과 가격(price)을 비교:
- Bid = (Cold CTR 예측값) → 아이템이 이 유저에게 얼마나 관련 있는가
- Price = → 노출의 “비용”
직관적으로: CTR 예측이 높은 (user, item) 쌍에만 노출하되, 예산 소비 속도와 유저 상태를 고려해 가격을 동적 조절.
E.4.2) Boosting Speed Factor ()
예산 소비 속도를 목표에 맞추기 위한 PID 스타일 제어:
여기서 (실제 속도 / 목표 속도).
- 예산을 너무 빨리 쓰면 () → Price 올려서 노출 줄임
- 예산이 남으면 () → Price 내려서 노출 늘림
- 로 현재/과거 에러를 가중 평균 → 급격한 변동 방지
E.4.3) User Preference Factor ()
유저의 “피로도”와 “활성도”를 결합:
| 요소 | 설명 | 효과 |
|---|---|---|
| 연속 노출 대비 클릭 없는 횟수 | 피로한 유저 → Price 높아짐 → 노출 줄어듬 | |
| 10단계 활성도 등급 () | 비활성 유저 → Price 높아짐 → 노출 줄어듬 |
핵심: 활성 유저 & 피로하지 않은 유저에게 집중 노출하여 CTR 극대화. “클릭 안 하는 사람에게 계속 보여주는 건 예산 낭비.”
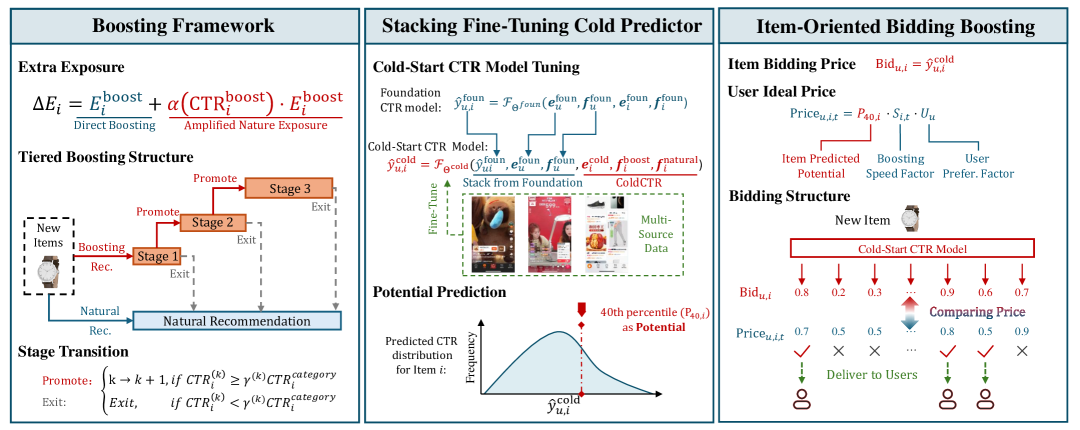 Figure 3: AliBoost 전체 아키텍처
Figure 3: AliBoost 전체 아키텍처
F) 벤치마크/데이터셋
| 데이터셋 | 유저 | 아이템 | 카테고리 | 인터랙션 | 기간 |
|---|---|---|---|---|---|
| Foundation CTR 학습 | 0.4B | 0.3B | 24,568 | 142B | 6개월 |
| Cold Fine-Tuning | 0.25B | 1.5B | 9,567 | 7.1B | - |
| Online A/B Test | 0.3B/일 | 1M/일 | - | 10B/일 | - |
배포 환경:
- 120K QPS, <20ms latency
- 15분 간격 모델 업데이트
- 6개월간 10억+ 아이템 cold-start 처리
G) 실험 결과
G.1) 전체 성과 (RQ1)
G.1.1) 플랫폼 전체
| Metric | PV | Click | Pay | GMV |
|---|---|---|---|---|
| 전체 | +2.01% | +4.51% | +3.96% | +4.69% |
G.1.2) Cold Item 기간별 개선
| 기간 | PV | Click | Pay | GMV |
|---|---|---|---|---|
| 3일 | +16.50% | +8.30% | +6.50% | +17.90% |
| 7일 | +29.20% | +19.60% | +18.20% | +25.30% |
| 30일 | +44.93% | +44.59% | +40.16% | +40.59% |
| 60일 | +46.36% | +55.15% | +56.24% | +52.06% |
| 90일 | +51.80% | +57.65% | +55.13% | +58.53% |
| 120일 | +58.94% | +61.68% | +65.71% | +67.75% |
| 150일 | +63.01% | +73.47% | +63.76% | +69.48% |
| 180일 | +65.87% | +76.09% | +74.26% | +72.03% |
시사점: 시간이 지날수록 개선폭이 커진다. 이는 부스팅이 단순히 단기 노출 증가가 아니라, 자연 추천 증폭 효과( 함수)를 통해 복리처럼 누적 되기 때문이다.
G.1.3) 41.1% → 24.5%
부스팅 전후, 30일 내 일 노출 10회 미달 cold item 비율이 41.1% → 24.5% 로 약 40% 감소.
G.2) Tiered Boosting 전략 효과 (RQ2)
| 설정 | CTR | Pay | GMV | Traffic Share | ROI | Hot Item Count |
|---|---|---|---|---|---|---|
| w/o Exit | -6.32% | -4.33% | -6.39% | -10.23% | -8.96% | -11.89% |
| w/o Promotion | -4.21% | -5.12% | -4.46% | -11.22% | -13.12% | -8.53% |
| 2 Stages | +6.23% | +5.56% | +3.56% | +4.56% | +6.64% | +3.63% |
| 3 Stages | +9.22% | +10.26% | +6.53% | +7.25% | +13.21% | +8.96% |
| 4 Stages | +9.28% | +10.36% | +6.98% | +7.84% | +13.46% | +8.78% |
실무적 시사점:
- Exit 규칙 제거 시 ROI -8.96%: 저품질 아이템에 예산 낭비
- Promotion 규칙 제거 시 ROI -13.12%: 고품질 아이템이 충분한 예산을 못 받음
- 3 → 4 Stage 전환의 marginal gain이 미미 (CTR +0.06%p, ROI +0.25%p). 운영 복잡도 대비 3 Stage가 최적
G.3) Stacking Fine-Tuning 효과 (RQ3)
| Metric | Offline AUC | 3일 PV | 3일 PCTR | 7일 PV | 7일 PCTR |
|---|---|---|---|---|---|
| 개선 | +2.24% | +8.30% | +10.71% | +7.39% | +11.40% |
AUC +2.24%는 cold item에 대한 랭킹 품질이 의미있게 향상됨을 보여준다. PCTR(Predicted CTR) 개선이 PV 개선보다 크다는 것은 더 정확한 예측 → 더 적합한 유저에게 노출 → CTR 향상 의 선순환을 의미.
G.4) Item-Oriented Bidding 효과 (RQ4)
| 설정 | CTR | Pay | GMV | Traffic Share | ROI | Hot Count |
|---|---|---|---|---|---|---|
| w/o Bidding 전체 | -45.31% | -38.21% | -42.11% | -8.96% | -21.39% | -9.36% |
| w/o Speed Factor | -18.11% | -14.98% | -21.93% | -4.09% | -8.09% | -4.67% |
| w/o User Pref Factor | -28.38% | -20.81% | -26.03% | -5.69% | -11.31% | -3.56% |
핵심 발견:
- Bidding 제거 시 CTR -45.31% — 가장 치명적. 입찰 없이 무작위로 노출하면 관련 없는 유저에게 보여줘서 CTR 급락
- User Preference Factor가 Speed Factor보다 영향이 큼 (CTR -28% vs -18%). “누구에게 보여줄까”가 “얼마나 빨리 보여줄까”보다 중요
- Speed Factor 제거 시 GMV -21.93%: 예산이 불균등하게 소비되어 일부 아이템은 과다 노출, 나머지는 노출 부족
G.5) Matthew Effect 완화 (RQ5)
| 순위 | 7일 | 14일 | 21일 | 30일 |
|---|---|---|---|---|
| Top 100 | -71.6% | -65.1% | -53.8% | -42.7% |
| Top 1000 | -56.3% | -43.2% | -36.9% | -29.2% |
해석:
- 7일 후 Top 100 아이템의 71.6%가 교체 됨 — 기존 독점 아이템들이 새 아이템에 의해 대체
- 시간이 지나면 교체율이 감소하는 건 자연스러운 현상 — 진짜 인기 있는 아이템은 살아남아야 함
- AliBoost가 “부익부” 루프를 깨고 신규 아이템에게 공정한 경쟁 기회 를 제공한다는 증거
G.6) Offline Baseline 비교 (Appendix)
| Model | Cold AUC | Warm AUC | All AUC |
|---|---|---|---|
| DeepFM | 0.6523 | 0.7112 | 0.7002 |
| DIN | 0.6634 | 0.7245 | 0.7123 |
| ALDI | 0.6756 | 0.7289 | 0.7156 |
| ColdLLM | 0.6834 | 0.7156 | 0.7078 |
| AliBoost | 0.6989 | 0.7301 | 0.7212 |
- Cold AUC에서 DeepFM 대비 +4.66%p, ColdLLM 대비 +1.55%p 개선
- Warm AUC도 유지/소폭 개선 — Stacking 구조 덕분에 Foundation 모델 성능을 해치지 않음
G.7) 카테고리별 성과 (Appendix)
| 카테고리 | Click 개선 |
|---|---|
| Pets | +181% |
| Auctions | +206% |
일부 niche 카테고리에서는 200%+ 개선. 이런 카테고리는 원래 cold item 비율이 높아서 부스팅 효과가 극대화된 것.
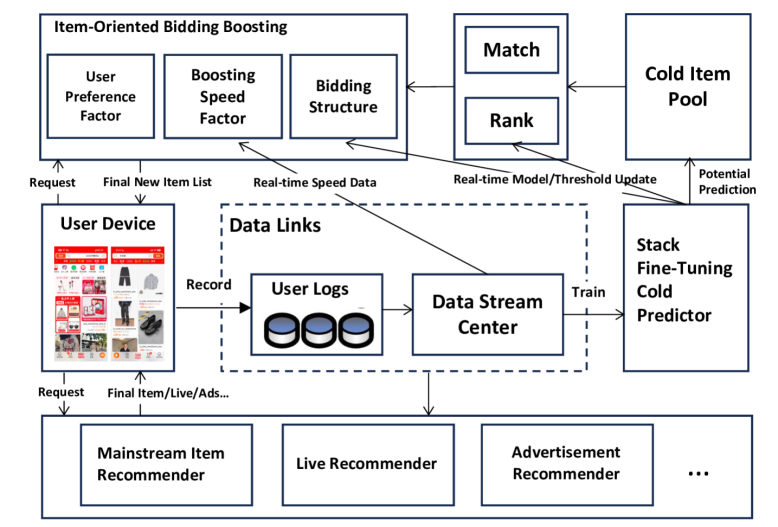 Figure 5: AliBoost 배포 아키텍처
Figure 5: AliBoost 배포 아키텍처
H) 실무적 시사점 종합
- Cold-start는 모델 문제가 아니라 생태계 문제: CTR 예측 정확도를 올리는 것만으로는 부족. 노출 기회 자체를 체계적으로 관리해야 한다
- 단계적 검증이 핵심: 한 번에 큰 예산을 주는 것보다 3단계로 나눠서 성과 기반 승격/퇴출하는 것이 ROI 13% 더 높다
- Bidding 메커니즘이 가장 중요한 모듈: 제거 시 CTR -45%. “누구에게 보여줄지” 결정이 전체 프레임워크의 핵심
- User Fatigue 관리 필수: 피로한 유저에게 계속 cold item을 보여주면 역효과. User Preference Factor가 두 번째로 중요한 요소
- Non-Disturbance Principle (): 부스팅이 기존 유저 경험을 해치지 않아야 한다는 안전 장치가 플랫폼 전체 메트릭 개선의 전제 조건
- Stacking > Fine-tuning: Foundation 모델을 직접 fine-tune하면 warm item 성능이 떨어진다. Stacking으로 cold-specific layer만 학습하는 것이 실용적
I) Related
J) References
- AliBoost: Ecological Boosting Framework in Alibaba Platform (arxiv)
- KDD 2025, ACM DOI: 10.1145/3711896.3737188