AB Test
A/B Test 는 사용자들에게 동시에 A 와 B 결과를 노출하고 이 둘의 결과를 비교하는 지표 측정 방법론이다. 즉, 일부 사용자들에게는 A 로직을 보여주고 다른 일부 사용자들에게 B 로직을 보여주면서 더 반응이 좋은 로직이 무엇인지 비교하는 것이다.
주로 모델의 성능을 측정하기 위한 online evaluation 방법 중 하나로 사용된다.
A.1) 유의할 점
A/B Test 는 동시에 추천 결과를 노출하는 것이 중요하다. 왜냐하면, 순간적인 유행의 변화, 새로운 콘텐츠의 등장, 요일이나 시간대에 따른 행동 패턴 변화 등 로직 외에도 지표에 영향을 주는 요소가 많기 때문이다.
TOROS 는 신규 로직을 5% 에서 10% 정도의 작은 확률로 노출해 기존 로직과 성능을 비교한다. 만약 기존 로직보다 좋은 신규 로직이 나타나면 그 로직이 기본 로직이 되고 또 다른 AB Test 를 반복한다.
B) 고려해야할 기본적인 사항들
- 명확한 목표 설정 (Define Clear Objective & KPI):
- 무엇을 개선하고 싶은가? (예: 구매 전환율 증가, 클릭률 향상, 평균 체류 시간 증가 등)
- 핵심 성과 지표(KPI)는 무엇인가? 목표를 측정할 수 있는 구체적인 지표를 설정해야 합니다.
- 가설 수립 (Formulate a Hypothesis):
- “만약 [변경 사항 A]를 적용하면, [특정 결과 B]가 나타날 것이다. 왜냐하면 이유 C 때문이다.” 와 같이 구체적이고 검증 가능한 가설을 세웁니다.
- 예: “만약 CTA 버튼 색상을 녹색에서 주황색으로 변경하면, 클릭률이 10% 증가할 것이다. 왜냐하면 주황색이 더 눈에 잘 띄고 긴급성을 주기 때문이다.”
- 변경 사항 최소화 (Isolate Variables - One Variable at a Time):
- 한 번의 테스트에서는 단 하나의 요소만 변경하는 것이 좋습니다. 여러 요소를 동시에 변경하면 어떤 요소가 결과에 영향을 미쳤는지 알 수 없습니다.
- 예: 버튼 색상만 변경하거나, 문구만 변경해야 합니다. 색상과 문구를 동시에 변경하면 안 됩니다.
- 테스트 대상 정의 (Define Target Audience):
- 누구를 대상으로 테스트할 것인가? (예: 신규 방문자, 특정 지역 사용자, 모바일 사용자 등)
- 테스트 결과가 특정 세그먼트에만 유효할 수 있으므로, 타겟을 명확히 해야 합니다.
- 무작위 할당 (Randomization):
- 테스트 그룹(A)과 대조군(B)에 사용자를 무작위로 공평하게 배정해야 합니다. 이는 외부 요인으로 인한 편향(bias)을 최소화합니다.
- 대부분의 A/B 테스트 도구가 이 기능을 제공합니다.
- 적절한 표본 크기 (Sample Size) 설정:
- 통계적으로 유의미한 결과를 얻기 위해 충분한 수의 사용자가 필요합니다.
- 표본 크기가 너무 작으면 우연에 의한 결과일 가능성이 높습니다.
- 표본 크기 계산기(Sample Size Calculator)를 활용하여 예상되는 개선율, 현재 전환율, 통계적 유의수준 등을 고려하여 결정합니다.
- 테스트 기간 설정 (Determine Test Duration):
- 너무 짧으면 계절성, 요일별 편차 등을 반영하지 못할 수 있습니다.
- 너무 길면 외부 요인(경쟁사 활동, 시장 변화 등)의 영향을 받을 수 있습니다.
- 일반적으로 최소 1~2주, 비즈니스 사이클(예: 주간 판매 패턴)을 최소 한 번 이상 포함하는 기간을 권장합니다. 표본 크기가 충족되는 시점도 고려해야 합니다.
- 통계적 유의성 확인 (Statistical Significance):
- 결과가 우연에 의한 것인지, 아니면 실제 효과인지를 판단하는 기준입니다.
- 일반적으로 유의수준(p-value) 0.05 이하, 신뢰수준 95% 이상을 기준으로 합니다.
- 결과 해석을 위해 통계적 유의성 계산법 을 고려한다.
- 결과 분석 및 해석 (Analyze and Interpret Results): 단순히 어떤 버전이 이겼는지 뿐만 아니라, 왜 그런 결과가 나왔는지 분석해야 합니다. 필요하다면 사용자 세그먼트별(e.g., 신규 vs. 재방문, 디바이스별)로 결과를 나누어 분석하여 더 깊은 인사이트를 얻을 수 있습니다.
- 결과 기록 및 공유 (Document and Share Findings): 테스트 목표, 가설, 과정, 결과, 결론, 배운 점 등을 상세히 기록하고 팀과 공유하여 조직의 지식 자산으로 만듭니다.
- 일관성 유지 (Maintain Consistency):
- 테스트 기간 동안 A그룹과 B그룹 사용자 경험의 일관성을 유지해야 합니다. 특정 그룹에만 다른 프로모션을 진행하거나 UI를 크게 변경하는 등의 행위는 피해야 합니다.
- **외부 요인 통제 (Control for External Factors):**테스트 기간 동안 대규모 마케팅 캠페인, 언론 보도, 서비스 장애, 공휴일 등 결과에 영향을 줄 수 있는 외부 요인을 최대한 통제하거나 기록하여 결과 분석 시 고려해야 합니다.
- 지속적인 테스트와 학습 (Iterate and Learn): A/B 테스트는 일회성 이벤트가 아니라 지속적인 개선 과정의 일부입니다. 하나의 테스트 결과로부터 배우고 다음 테스트 아이디어를 도출해야 합니다.
C) Offline AB Test
C.1) NDC21 (추천알고리즘 Offline AB Test)
Offline A/B 테스트란, 과거 A 알고리즘이 실제 서비스에 적용되었던 history 데이터를 이용하여 B 모델의 실제 성능을 추론해 보는 것
- 사용자의 경험 비용 최소화
- 새로운 아이디어를 빠르게 확인하여, 사전에 성능이 떨어지는 알고리즘은 미리 제외하고 성능이 보장된 알고리즘만 online 에 적용 가능함

- 하지만, 많은 가정이 필요하고 offline 테스트 결과와 다를 수 있다는 리스크가 있음
- 과거 데이터는 A 알고리즘과 그로부터 생성된 사용자의 반응에 bias 가 존재함
- 즉, 이미 적용된 알고리즘을 통해 추천된 콘텐츠에 대해서만 반응을 평가할 수 있고, test 알고리즘이 새롭게 제시할 콘텐츠에 대한 사용자 선호도를 평가하기 어려움
Online A/B 테스트는 비용이 높다.
- 테스트 알고리즘이 좋은 성능을 보장하지 못하면, 최악의 경우 부정적인 경험을 한 사용자가 서비스를 탈퇴할 수도 있음
- 또한, 광고의 경우 클릭이 수익으로 직결되기 때문에 매출이 급격히 하락할 수도 있음
counterfactual thinking 접근
- 만약 ~ 했다면 (조건), ~ 했을 텐데 (결과)
- 예시) ‘ 만약 X 음악이 A 알고리즘이 아닌 B 알고리즘에 의해 추천되었다면, 20% 확률로 클릭되었을 텐데 ’
- B 알고리즘의 추천 확률 개념을 이용해서 사용자의 반응에 가중치를 다시 매기는 (re-weighting) 방법
참고: youtube link
D) Offline A/B 테스트 추론 방법
- importance weight
- weight 계산 방법: (B 알고리즘 내 k 번째 추천될 확률) / (A 알고리즘 내 k 번째 추천될 확률 + )
- 은 확률이 0 이 되는 것을 방지해주기 위한 작은 수

- weight 는 monte carlo simulation 을 통해 계산: n 번 추천리스트를 생성한 다음 각 아이템이 k 번째 추천될 확률 계산
- IS 에 의한 추정 반응률: A 알고리즘에 비해서 B 알고리즘의 성능이 얼마나 향상될지 혹은 감소할지 추정,
- : weight, : response, : number of data
- importance sampling:: weight 를 기반으로 사용자의 반응을 보정
- 이 방식의 단점은 A 알고리즘에서 매우 낮은 확률로 노래가 추천되는 경우, 굉장히 큰 weight 값이 생성될 수 있어서, 전체 결과에 큰 영향을 미칠 수 있다는 점이다.
- 이러한 문제를 해결하기 위해 CIS(Capping Importance Sampling) 을 제안
- CIS::
- 는 capping value
- 다른 방법으로는 NCIS (Normalized CIS) 가 존재함
- CIS::
- 예시)
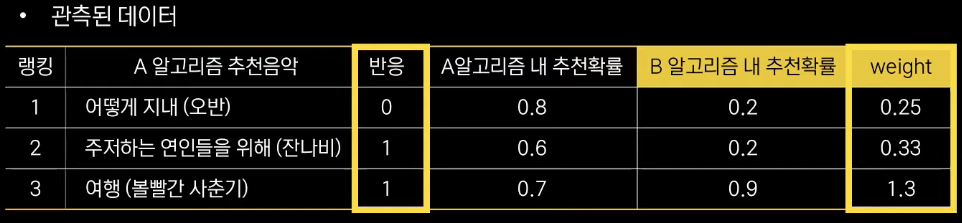
- IS 에 의한 B 알고리즘의 추정 반응률:
- 확인한 부분
- offline A/B 테스트 measure 중에서 NCIS 의 성능이 가장 좋았음
- 추가적으로 아래 2 가지 방법론 적용 가능
- pieceNCIS: 데이터를 적절한 그룹별로 나눠서 normalization
- pointNCIS: 데이터 각각을 normalization
- NCIS 와 같은 방법은 추천 확률을 이용하여 결과를 예측하므로, deterministic 알고리즘은 적용하기가 어려움
- stochastic model 로 근사화
- Ranking score 기반의 weighted sampling 을 통해 추천 확률을 생성할 수 있음
- Doubly Robust 방법론을 적용해 볼 수 있음