Abstract
- Item recommendation 문제를 풀기 위한 기존 방식들: matrix factorization, adaptive-k-Nearest Neighbors 등은 ranking 을 위한 optimzation 에 바로 사용되지 못하고 있음
- 해당 논문에서는 개인화 랭킹을 위한 최적화 기준인 BPR-Opt 를 제시 (MAP 활용)
- 또한, BPR-Opt 에 관련된 모델을 학습하는 알고리즘 LearnBPR 도 제시
- 기존 방식들 (MF, kNN) 에 LearnBPR 을 적용하는 사례를 보임
- Pointwise approaches considers a single interaction at a time and train a classifier or a regressor to predict individual preferences.
B) Introduction
BPR-Opt 를 최적화 하는것은 ROC Curve 의 넓이를 최대화 하는것과 같다.
LearnBPR 알고리즘 제시: bootstrap sampling (of training triples) 을 이용한 stochastic gradient descent 기반의 방법
C) Related Works
SVD 를 통한 MF 는 overfitting 에 취약하다는 문제점이 있다. 이를 해결하기 위해 a regularized least-square optimization with case weights (WR-MF) 를 제안한다.
해당 논문은 offline learning 을 메인으로 다룬다.
C.1) Personalized Ranking
이 논문은 implicit feedback 으로 부터 ranking 추론이 진행된다는 시나리오를 가정한다.
이 implicit feedback 은 오직 positive feedback 만 있다고 주장 (그 외에는 관찰되지 않은 user-item pair)
D) Formalization
크기의 implicit matrix 대신, item 간 사용자 선호도를 표현할 수 있는 matrix 를 사용자마다 만든다. 즉, 전체 training dataset 은 의 크기를 가진다.
- 의 의미는 는 를 보다 선호한다는 의미를 가짐
D.1) -> Figure
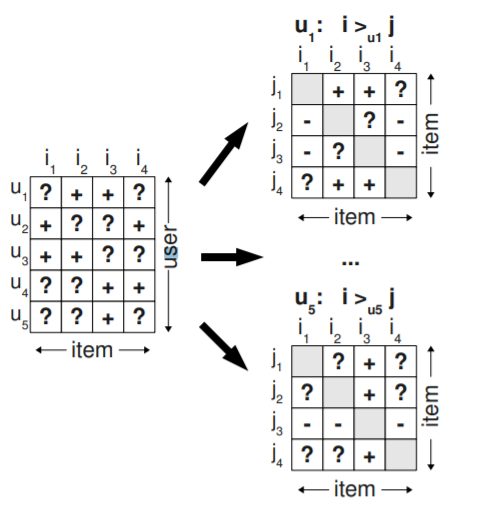 이렇게 하면, 단순히 특정 유저가 implicit feedback (click) 이 없다고 해서 전체가 모두 negative feedback 로 처리되는 것을 막을 수 있음
이렇게 하면, 단순히 특정 유저가 implicit feedback (click) 이 없다고 해서 전체가 모두 negative feedback 로 처리되는 것을 막을 수 있음
E) Bayesian Personalized Ranking (BPR) Loss
베이지안 관점에서 모든 아이템 에 대해서 올바른 랭킹을 찾는 것은 다음과 같은 posterior 확률을 최대화 하는 것과 같다
는 임의의 추천 모델의 parameter 를 의미하고, 는 사용자 에 대한 전체 아이템의 적절한 개인화된 랭킹 결과를 의미한다. prior 는 평균이 0 이고 분산은 라는 convariance matrix 를 가지는 normal distribution 이다. 분산 행렬의 경우 간단히 로 표현할 수 있다.
위 식을 개인화 추천을 위한 일반적인 최적화 식으로 바꾸면 아래와 같다.
위에서 는 학습 데이터이고, 는 유저 가 좋아하는 아이템, 는 좋아하는 아이템은 아닌 아이템을 의미한다 (싫어한다는 의미는 아니다). 만약, BPR 이 최적화되었다면, 유저가 아이템 에 대한 평가가 당연히 에 대한 평가 보다는 높게 나와야 할것이다. 결과적으로 위의 BPR 식은 점점 최대화가 되는 것이다.
F) Implementation
mxnet 으로 구현한 BPR loss 가 있어서 가져왔다. 읽는데 라이브러리의 영향은 없다. regularization 부분은 제외된듯.
class BPRLoss(gluon.loss.Loss):
def __init__(self, weight=None, batch_axis=0, **kwargs):
super(BPRLoss, self).__init__(weight=None, batch_axis=0, **kwargs)
def forward(self, positive, negative):
distances = positive - negative
loss = - np.sum(np.log(npx.sigmoid(distances)), 0, keepdims=True)
return lossF.1) Using Hinge Loss
hinge loss 를 이용해서 BPR loss 를 구현해도 비슷한 효과를 얻을 수 있다.
여기서 은 margin size 라고 한다. 위 식을 최소화하는 방향으로 생각하면 positive item 은 가까워지고, negative item 은 서로 밀어내려한다.
구현은 간단하다.
def forward(self, positive, negative, margin=1):
distances = positive - negative
loss = np.sum(np.maximum(- distances + margin, 0)) return loss
return loss