Abstract
- Blindly fitting the data without considering the inherent biases will result in many serious issues, e.g., the discrepancy between offline evaluation and online metrics, hurting user satisfaction and trust on the recommendation service, etc.
- Recommendation System 에서의 bias 를 조사해보니 정의가 vague 하고 paper 마다 정의가 일정하지 않다.
- 추천 시스템에서의 7 개 type 의 bias 를 정의와 특성을 포함하여 요약하고, 몇개의 open challenges 와 미래의 방향성을 제시 (envision)
- 일부는 중요하지만 덜 조사된 topic 들도 존재함
github link: https://github.com/jiawei-chen/RecDebiasing
B) Introduction
- 추천 연구에서 bias 의 중요성이 높아지고 있음
- 알리바바가 주최한 KDD Cup 2020 의 한 문제는 E-commerce 추천에서 long-tail bias 를 해결하는 것이였음
- 이런 사람이 읽으면 좋음
- who are new to the bias issues and look for a handbook to fast step into this area
- who face bias issues in building recommender systems and look for suitable solutions
C) Preliminaries: Recommender System and Feedback Loop
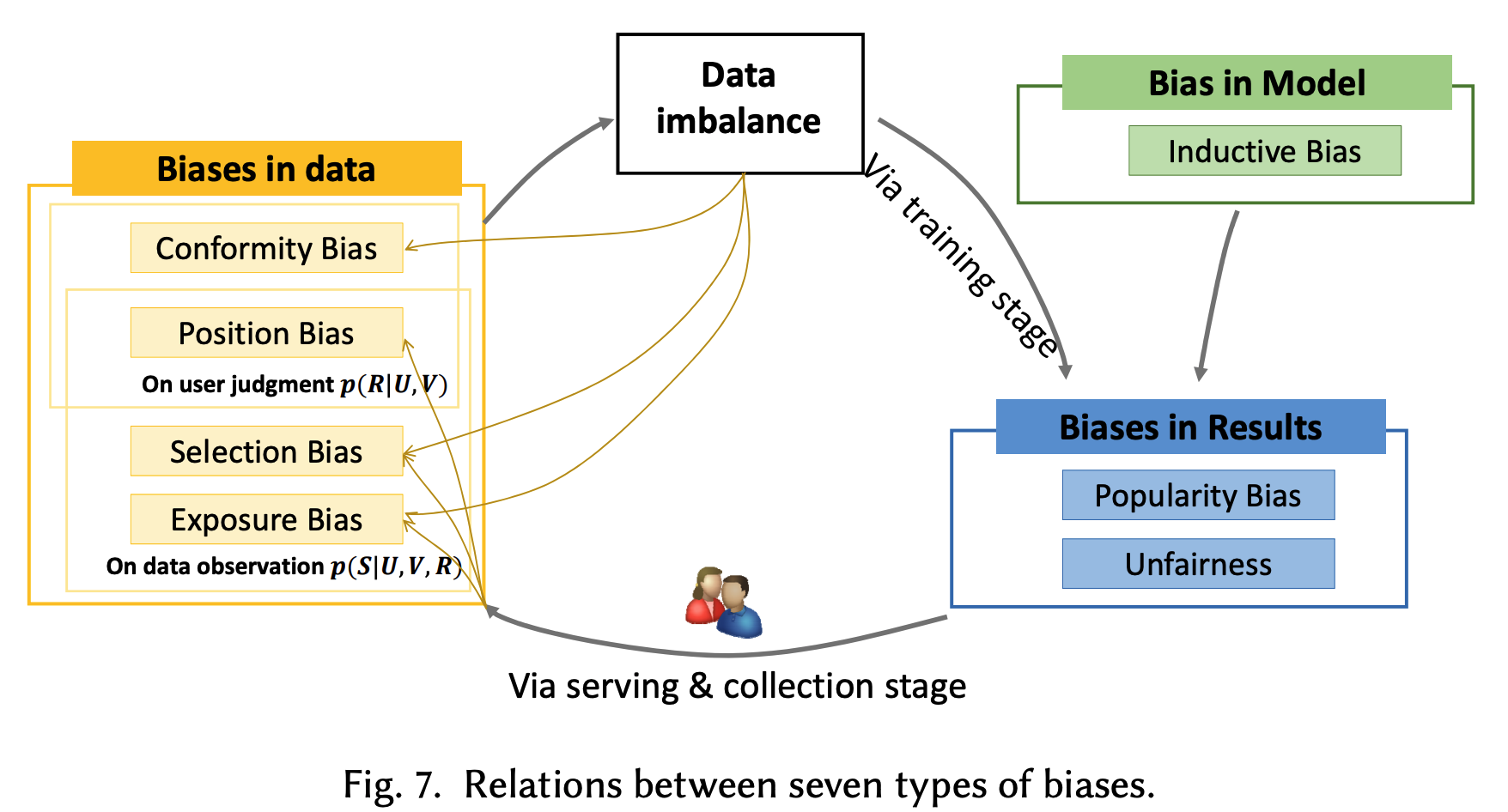
- Feedback Loop in Recommendation: three stages
- User -> Data (Collection): 사용자로부터 데이터를 모으는 단계
- Exposure Bias, (User-)Selection Bias, Conformity Bias, Position Bias
- Data -> Model (Learning): 모은 데이터를 이용하여 추천 모델을 학습하는 단계
- Inductive Bias
- Model -> User (Serving): 추천 결과를 사용자에게 보이는 단계
- Popularity Bias, Unfairness
- User -> Data (Collection): 사용자로부터 데이터를 모으는 단계
D) Bias in Recommendation
D.1) Collection: Bias in Data
D.1.1) Data Bias 정의
Data Bias 참고
D.1.2) Selection Bias (from Explicit feedback)
selection bias 는 사용자가 어떤 아이템을 평가할 것인지에서 비롯된다. 그래서 관측된 평가는 모든 평가들에 대한 대표적 샘플이 될 수 없다.
다른 말로하면, rating data 는 종종 missing not at random (MNAR) 이다.
D.1.3) Exposure Bias (from Implicit feedback)
exposure bias 는 사용자가 오직 일부 특정 아이템들에 대해서만 노출되어, 관측되지 않은 상호작용이 언제나 negative 성향을 의미하지는 않게되는 현상을 의미한다.
- exposure bias 는 positive 한 feedback 밖에 존재하지 않는 one-class (implicit) 데이터에서만 발생한다.
- conformity bias
D.1.4) Position Bias
아이템의 연관성과 상관없이 높은 position 에 있는 아이템과 주로 상호작용하는 경우 position bias 가 발생하여, 상호작용한 결과가 실제로 유저와 relevant 한지 애매해지는 경우를 의미.
D.2) Learning: Bias in Model
D.2.1) Inductive Bias
모델이 특수한 성질을 띄게 만들기 위해 의도적으로 추가된 bias
D.3) Serving: Bias and Unfairness in Results
D.3.1) Popularity Bias
- 인기 아이템이 해당 아이템의 인기 정도보다 더 많이 추천되는 현상
- long-tail 현상: 대부분의 사용자 상호작용을 인기 아이템 일부가 담당하고 있는 현상
- 일반적으로 long-tailed 데이터를 통해 학습한 모델은 인기 아이템에 대해서 높은 score 를 주고, 인기가 없는 아이템에 대해서는 낮은 score 를 준다.
- popularity bias 를 무시하는 것은 다음과 같은 이슈가 존재함
- 개인화의 레벨을 감소시키고, serendipity 의 정도를 낮춤
- 추천의 fairness 정도를 감소시킴
- Matthew effect issue
D.3.2) Unfairness
- 시스템이 불공평하게 특정 개인이나 그룹에 대해 차별하는 것
D.4) Feedback Loop 는 Bias 를 증폭시킨다
E) Debiasing Methods
E.1) Methods for selection bias
E.2) Methods for exposure bias
E.2.1) Debiasing in Evaluation
E.2.2) Debiasing in Model Training
implicit feedback 의 negative signal 을 추출해내기 위한 전통적인 방법은 관측되지 않은 모든 상호작용을 negative 로 보고, 거기에 confidence 를 부여하는 것이다.
이러한 방법의 대부분의 objective function 은 다음과 같다
- 는 사용자 와 item 간 상호작용이 관측되었는지 아닌지의 여부를 나타내는 surrogate label
- 는 confidence weight
confidence weight 를 정하는 방식은 크게 세 가지로 나뉘어짐
E.2.2.1) Heuristic Weighting
E.2.2.1.1) Methods
- 관찰되지 않은 상호작용에 대해서 uniform 한 낮은 가중치를 부여하는 방식: WMF, dynamic MF
- 사용자의 activity level 에 기반해서 confidence 를 설정하는 방법도 있음 (i.e. )
- 아이템 인기도를 고려하는 방법도 존재함
- 더 인기있는 아이템일수록 노출될 가능성이 높다는 가정
- Fast matrix factorization for online recommendation with implicit feedback
- user-item feature 유사도 역시 confidence 를 결정하는데 활용되기도 했음
E.2.2.1.2) Pros and Cons
- pros: simple
- cons: 최적의 confidence 는 사용자와 아이템 조합에 따라 다르다. 그리고 적절한 가중치를 정하는 것은 grid search 를 통해 많은 리소스가 요구된다.
E.2.2.2) Sampling
유저와 아이템 상호 작용의 샘플링 확률을 라 할때, sampling 을 통해 추천 모델을 학습하는 것은 다음과 같은 가중치 목적 함수를 가진 모델을 학습하는 것과 동일하다
- Methods
- [LMF](Logistic Matrix Factorization for Implicit Feedback Data), [BPR](BPR - Bayesian Personalized Ranking from Implicit Feedback), 또는 대부분의 신경망 기반 추천 모델들 ([NCF](Neural Collaborative Filtering), LightGCN)
- 인기있는 negative items 을 oversampling 하는 것도 고려한 연구가 존재
- sampler 를 향상시키기 위해 side-information 을 사용하는 방법도 고려했음
- 노출되었지만 클릭하지 않은 데이터를 통해 사용자의 노출 정도를 평가하는데 활용함: [46](An Improved Sampler for Bayesian Personalized Ranking by Leveraging View Data), [47](Reinforced Negative Sampling for Recommendation with Exposure Data)
E.2.2.3) Exposure-based Model
노출 기반 모델은 어떤 유저가 한 아이템에 대해서 얼만큼 노출될 가능성이 있는지 측정하는 모델을 의미한다.
EXMF 에서 exposure variable 를 소개하고 implicit feedback 에 대한 생성 과정을 다음과 같이 가정하였다
E.2.2.4) Others
E.3) Methods for popularity bias
E.3.1) Regularization
모델 학습 시, regularization 을 추가하여 균형있는 추천을 목적함
E.3.1.1) LapDQ Regularizer
- 는 item embedding matrix, 은 matrix 의 trace, 는 의 Laplacian matrix 를 의미한다.
- : item 그리고 가 동일한 집합에 포함됨을 의미 (popular items or long-tail items). 포함되지 않으면 .
E.3.1.2) Mean-match Regularizer
E.3.1.3) Pearson Coefficient Regularizer
decrease the correlation between item popularity and model output scores: ^507444
E.3.1.4) Entire Space Adaptation Model (ESAM)
ESAM 은 popular item 에 대해 잘 학습된 knowledge 를 long-tail item 으로 전달한다.
- Domain Adaptation(DA) with item embedding
E.3.2) Adversarial Learning
adversarial learning 의 기본 아이디어는 추천 시스템 와 adversary 가 min-max game 을 진행하여 가 niche(long-tail) items 을 추천할 수 있도록 signal 을 보내게 하는 것이다 (^c2176e)
adversary 는 popular-niche 아이템 쌍 에 대해 생성된 합성 데이터와 동일한 수의 실제 데이터 쌍을 입력으로 받는다.
- 실제 쌍은 global co-occurrence 에서 샘플링되고, 합성 쌍은 recommender 에 의해 생성된다.
- 는 [NCF](Neural Collaborative Filtering) 와 같은 추천 모델이 될 수 있음
는 popular 와 niche 아이템 간 암묵적 관계를 학습하고, 는 사용자 history 기반의 더 niche 한 item 을 찾아냄으로써 , long-tail 아이템을 추천 가능하게 함
E.3.3) Causal Graphs
leverage causal graph to tackle popularity bias
E.3.4) Others
- side information 을 추가해서 popular bias 를 감소시킴 ^74fae7
- popularity 에 기반한 re-ranking 방식: ^73df85
- exposure bias 와 동일하게 propensity score 도 적용 가능
E.4) Methods for Position Bias
E.4.1) Click Models
유저의 true preference 를 찾기 위해 다음과 같이 사용자가 position 의 item 를 클릭할 확률을 모델링한다.
\begin{equation} \begin{aligned} &P(C=1 \mid u, i, p) \\ &=\underbrace{P(C=1 \mid u, i, E=1)}_{r_{u i}} \cdot \underbrace{P(E=1 \mid q)}_{h_{q}} \end{aligned} \end{equation}$$ 여기서 숨겨진 랜덤 변수 $E$ 는 유저가 아이템을 확인했는지 여부를 나타낸다. 이 모델은 position으로 노출 확률을 모델링하는 것만 제외하면, exposure bias를 위한 exposure-based 모델과 유사하다. #### E.4.1.1) Cascade Model 이 모델은 유저가 처음부터 끝까지 전체 아이템을 순서대로 검사한다고 가정한다. 그리고 각 query session (추천 발생)마다, 최대 한개의 클릭만 발생한다고 가정한다. 클릭 모델들은 많은 양의 클릭 데이터가 필요한데, 이러한 데이터가 sparse 하다면 올바른 모델을 만들기가 어렵다. ### E.4.2) Propensity Scores position bias을 위한 the propensity score를 추정하는 방식 randomization: ranking 결과를 랜덤하게 섞고 클릭 정보를 모아서 propensities score를 계산 위 방식은 사용자 만족도를 해치므로 다음과 같은 방법들이 제안됨 1. intervention harvesting: 여러 랭킹 모델이 필요함 2. propensity model 과 recommendation model을 dual problem으로 인식하고 EM 알고리즘을 통해 두 모델을 학습하려 하는 시도가 있음 3. ### E.4.3) Trust-aware Models # F) References * [[Popularity Bias in Ranking and Recommendation]] ^73df85 * [[An Adversarial Approach to Improve Long-Tail Performance in Neural Collaborative Filtering]] ^c2176e * [[The Limits of Popularity-Based Recommendations, and the Role of Social Ties]] ^74fae7 * [[Popularity-Opportunity Bias in Collaborative Filtering]] ^507444