KNN
어떤 문제를 푸냐에 따라 방식이 달라진다: 분류 또는 회귀.
- For classification: 비교 대상이 되는 데이터 주변에 가장 가까이 존재하는 개의 데이터와 비교해 가장 가까운 데이터 종류로 판별한다.
- For regression: 비교 대상이 되는 데이터 주변에 가장 가까이 존재하는 개의 데이터의 값을 aggregate 한다 (e.g. mean).
A.1) 예시
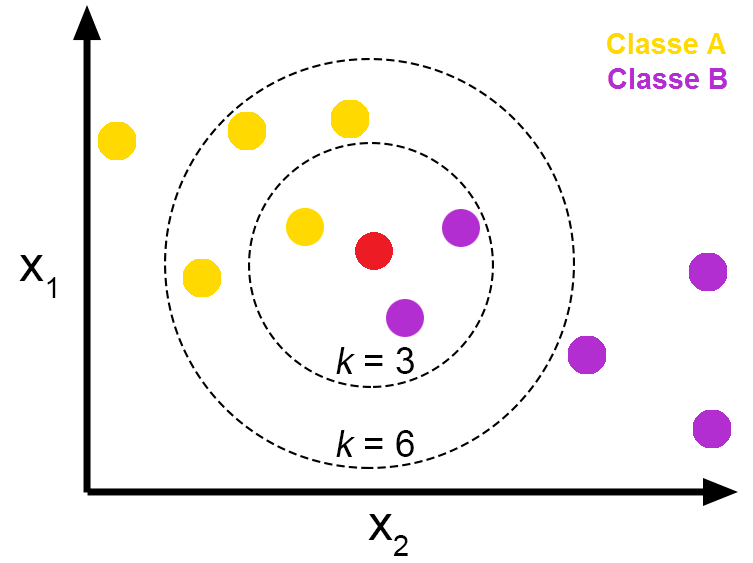
위 그림처럼 빨간색 데이터를 기준으로 의 KNN 을 수행했을 경우, 보라색 데이터 (class B) 가 많으므로, 빨간색 데이터는 class B 로 판별된다.
만약 의 경우는 노란색 데이터 (class A) 가 많으므로, 빨간색 데이터는 class A 로 판별된다.
A.2) 특징
- 아이템 분포에 대한 제약이 없다.
- item feature 유사도에만 의존한다 (e.g. Euclidean distance).
- 데이터 차원이 커질수록 curse of dimensionality 에 의해 성능 저하가 발생한다. 이에 대한 이슈를 해소하기 위해 locality sensitive hashing 을 이용하기도 한다.
- KNN 은 학습 과정에서 Lazy learning 방법을 사용한다.