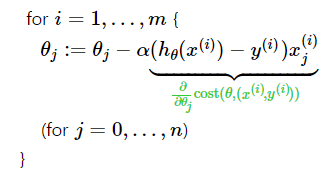Stochastic Gradient Descent
일반적인 Batch gradient descent(BGD) 를 이용한 방식은 한꺼번에 모든 학습 데이터에 대한 derivative 를 계산하기 때문에 데이터가 클 때 학습 속도가 느리다.
그러나 SGD 는 단일 training example 에 대한 cost 를 정의한다.
B) How to SGD ?
SGD 를 수행하기 전에, dataset 를 임의로 shuffle 한다 (섞는다). shuffle 의 이유는 데이터 자체가 특정한 structure 를 가질 수 있기 때문이다 (e.g. 시간 순서). 즉, 편향되지 않은 데이터에 대한 true gradient 를 얻기 위해서 데이터를 섞어줘야한다.
이후 아래와 같이 전체 개 examples 에 대한 parameter 업데이트를 각각 진행한다.