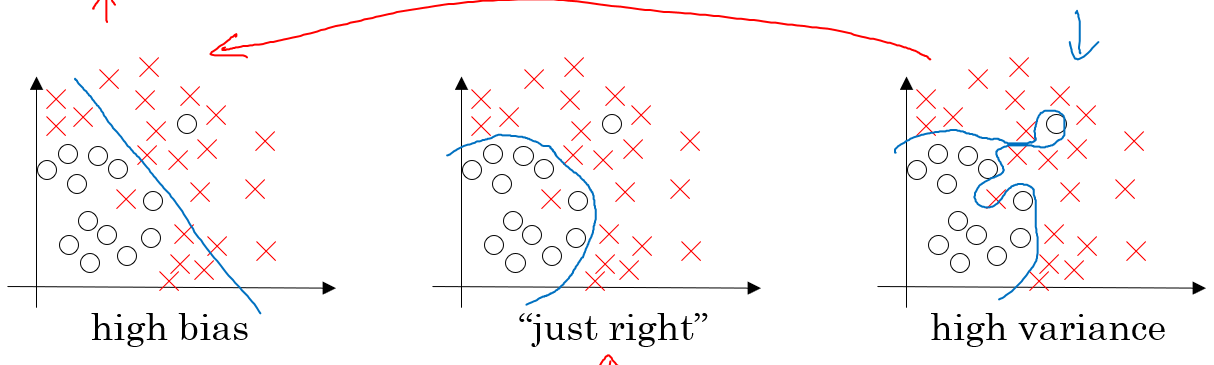
Regularization
Regularization 은 overfitting 문제를 완화하기 위한 방법이다.
B) Apply Regularization to Model
Regularization 을 logistic regression 에 적용하기 위해서 L2 norm 을 사용하고, neural network 에는 Frobenius norm 을 적용한다.
B.1) Logistic Regression 의 경우
Regularization term 이 붙은 cost function 는 다음과 같이 계산된다.
- 여기서 는 L2 norm 을 의미한다 ().
B.1.1) 왜 Bias 는 Regularization 을 적용하지 않는가?
실제로 regularization term 에 bias 를 추가해도 상관없다. 그러나, 높은 차원의 벡터는 high variance 에 크게 관련있는 반면, bias 는 단순히 숫자 (single number) 일 뿐이므로 high variance 에 큰 영향을 주지 않는다.
B.1.2) L1 Norm instead of L2 Norm?
L1 Norm 역시 적용할 수 있다.
L1 Norm 을 적용하여 나타나는 현상은 weight 값들이 sparse 해진다는 것이다. 즉, 대부분의 원소들이 0 의 값을 가진다. 그래서 일종의 feature selection 역할을 맡는다.
몇몇 사람들은 이러한 결과가 메모리를 절약하는데 도움을 준다고는 하지만, 실제로는 큰 영향이 없는 것으로 확인되었다. 결과적으로 L2 Norm 을 가장 많이 사용한다.
B.2) Neural Network 의 경우
Regularization term 이 붙은 cost function 는 다음과 같이 계산된다.
- 는 의 크기를 가진 matrix 이다.
- 그리고 는 matrix 의 Frobenius norm 이다:
- 는 해당 layer 의 unit 개수 를 나타내고, 는 이전 layer 의 unit 개수 를 나타낸다.
B.2.1) Weight Decay
위 cost function 를 이용한 back propagation 은 어떻게 계산되는가? Frobenius norm 을 이용한 back propagation 을 종종 weight decay 라고 부른다.
우선 Frobenius norm 의 미분은 로 표현되며 weight update 는 다음과 같다..
- 은 regularization term 을 제외한 나머지 부분에 대한 backprop 계산의 결과다.
위 식에서 을 만족하므로, weight 이 update 될 때마다 점점 감소한다 하여 weight decay 로 불린다.
C) How Does Regularization Prevent Overfitting?
값이 높아지면, cost function 을 최소화하는 것이 학습의 목적이므로 weight 가 줄어든다. 결과적으로, 줄어든 weight 를 통해서 계산된 각 layer 의 output 은 0 에 가깝게 된다.
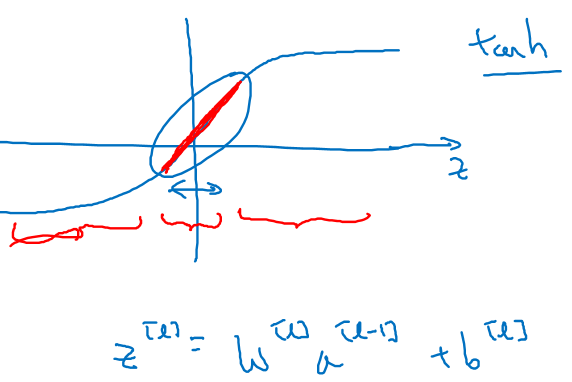 위 그림은 activation function 중 tanh function 에 대한 그림이다.
위 그림은 activation function 중 tanh function 에 대한 그림이다.
weight 가 작다면, 0 의 값 중심으로 layer 의 output 이 몰릴것이고, 해당 레이어는 선형 (linear) 모델과 비슷하게 된다. 만약, 전체 레이어가 이와같은 선형 모델이라면, 결과적으로 모델 자체가 선형 모델에 가깝게 될 것이고, 이는 곧 모델 단순화의 원인이 되어 overfitting 을 예방한다.