Autoencoder
self-supervised Learning 방식이다. 학습된 manifold 근방의 데이터에 대해서만 제대로 작동함으로써 간접적으로 manifold 를 표현한다. 직접 manifold 를 추정하고 표현하는 기법은 t-SNE 다.
B) Applications
- Data denoising
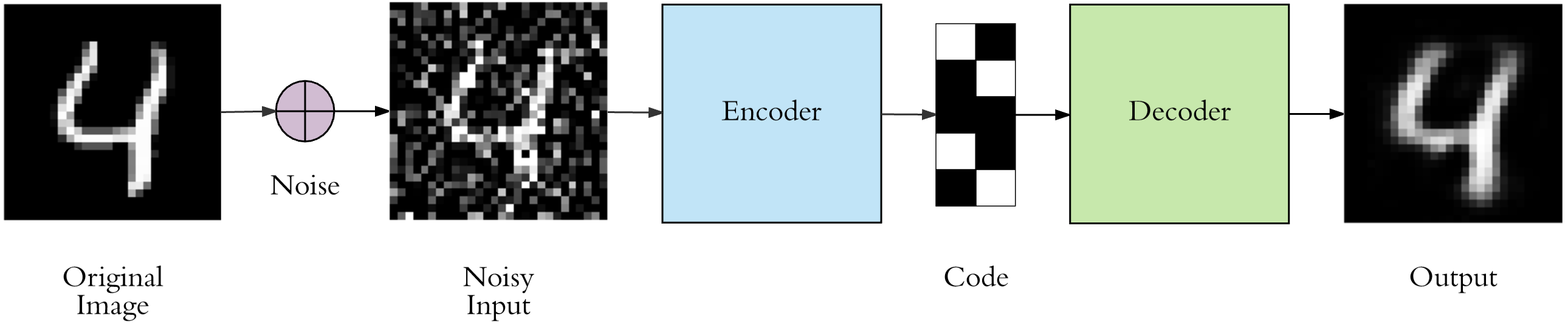
- Data Restoration

C) AE 의 장점
- 신경망에 non-linear activation function 을 사용하기 때문에, non-linear 한 데이터에 대한 차원 압축을 원활히 진행할 수 있다.
- Principal Component Analysis 는 주성분 벡터를 이용해 기존 데이터를 변형하므로, 선형 변환만 가능하다.
- 차원 변환 외에도 활용 가능성이 높다.
- Data denoising & Restoration
D) AE 의 단점
-
훈련에 많은 시간이 필요하다.
-
Data-specific: 훈련된 데이터와 비슷한 데이터만 올바르게 압축 및 복원할 수 있다.
- 다른 말로 하면, autoencoder 는 training set 이 형성하는 manifold 와 비슷한 형질을 지닌 데이터만 올바르게 복원할 수 있다.
- 어떻게 생각하면 autoencoder 의 디코더의 기능이 인코더가 특정 데이터를 인코딩 해 놓은 좌표에만 잘 작동하게끔 오버피팅 (overfitting) 되어 있는 상태라고도 말할 수 있을 것이다.
- AE 학습을 위해서는 축소된 차원을 복원하는 과정을 거쳐야 하는데, hidden layer 의 unit 이 일정 차원수 이상을 보장하지 않으면 축소 과정에서 정보 손실이 너무 커져서 올바른 복원이 되지 않고, 학습이 잘 이루어지지 않음
- 결과적으로 일정 차원수 이상을 보장해야 하는데, 이로 인해서 간접적인 manifold 의 표현밖에 가능하지 않음
- 군집 강도 형성이 부족: 인코딩 시 표현 벡터들의 위치를 선택하는 특정한 규칙이 없다
E) Stacked AutoEncoder (SAE)
얕은 network 를 가지는 autoencoder 는 한계가 있고, hidden layer 를 여러 개 쌓아서 deep architecture 로 확장시킬 수 있다. 이렇게 확장한 구조를 SAE 라고 한다.
E.1) Layer-wise Pre-training
여러 layer 의 autoencoder 를 한꺼번에 학습시키기 전에 다음과 같은 예비 학습 과정을 거치게된다.
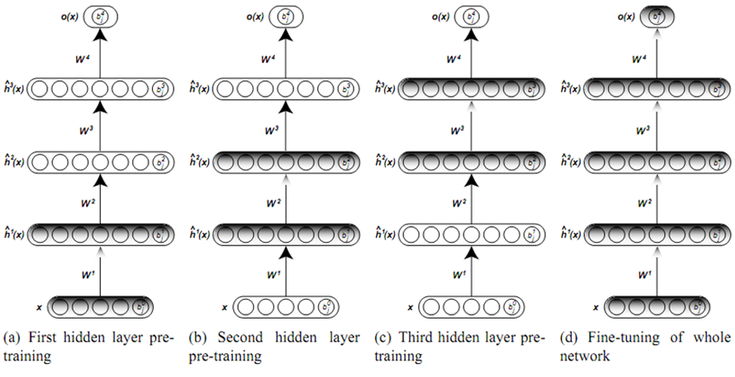
- 우선 첫번째 layer 를 학습시킨다. 이때 입력은 , 출력은 로 일반적인 autoencoder 의 학습을 시킨다.
- 이후 첫번째 layer 의 weight 는 고정시키고, 두번째 layer 를 학습시킨다. 이전 학습 시, 를 입력했을 때 첫번째 hidden layer 에서 얻어지는 출력 을 입력으로 하고, 출력도 로 하게 만든다.
- 세번째 layer 도 비슷한 방식으로 입력은 , 출력도 로 수행한다.
- 이렇게 반복적으로 하고, 마지막에 원하는 layer 를 추가하면 된다.
- 예를 들어서 마지막 layer 에 classification 을 위한 layer 를 추가할 수 있다.
이렇게 층별 레이어 학습을 통해서 gradient vanishing 문제를 완화시킬 수 있었기에, 혁신적인 연구였지만, 지금은 GPU 성능 향상 및 대용량 데이터 확보와 같은 외부적인 영향으로 예비 학습 과정을 거치지 않아도 충분한 성능을 얻을 수 있게 되었다.
F) Variational AutoEncoder (VAE)
VAE 는 학습 데이터의 확률 분포에 대한 latent vector 를 찾아서, AE 보다 높은 군집 강도를 형성할 수 있게끔 도와주는 신경망이다.
- VAE 를 통해 생성된 latent vectors 는 AE 보다 차원상에서 compact 하게 뭉쳐져 있다.
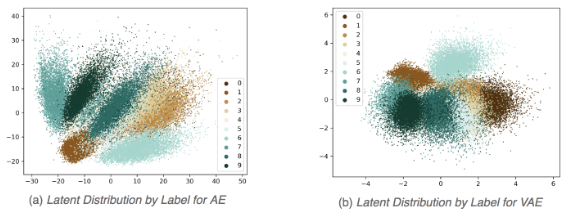
VAE 는 분포에 대한 예측과 이 분포에 대한 sampling 을 수행하므로, generative model 이라고 할 수 있다.
F.1) VAE 의 학습 과정
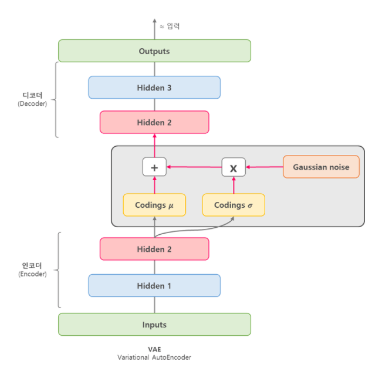
- VAE 의 encoder 네트워크는 입력 샘플
x를 잠재공간 (latent space) 에서 두 개의 매개 변수 와 로 변환시킨다. - Reparameterization Trick: 를 잠재정규분포로 정하고, 과 유사한 데이터를 무작위로 sampling 한다.
- 은 gaussian noise 로, 임의의 정규 tensor 다.
- decoder 네트워크는 sampling 된 데이터를 원래의 입력 데이터로 복원한다.
F.2) VAE 의 장/단점
장점
- GAN 에 비해 학습이 안정적 (reconstruction error 같이 평가 기준이 명확)
- 데이터뿐 아니라 데이터에 내재한 잠재변수 도 학습 가능 (feature learning)
단점
- 출력이 선명하지 않고 평균값 형태로 표시됨
- reparameterization trick이 모든 경우에 적용되지 않음