Stacked Autoencoder
얕은 network 를 가지는 AE 는 한계가 있고, hidden layer 를 여러 개 쌓아서 deep architecture 로 확장시킬 수 있다. 이렇게 확장한 구조를 Stacked autoencoder 라고 한다.
학습된 SAE 의 마지막 레이어에 원하는 레이어를 추가해서 문제에 따른 적합한 신경망을 구성할 수 있다. 예를 들어, 마지막 layer 에 classification 을 위한 layer 를 추가할 수 있다.
학습 과정: Layer-wise Pre-training
여러 layer 의 autoencoder 를 한꺼번에 학습시키기 전에 다음과 같은 예비 학습 과정을 거치게된다.
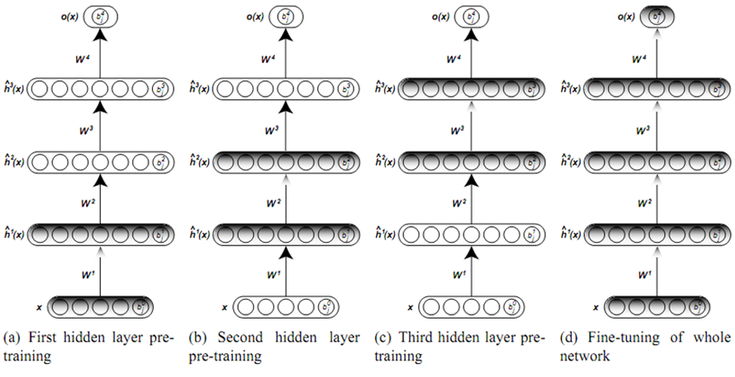
- 우선 첫번째 layer 를 학습시킨다.
- 입력은 , 출력은 로 일반적인 autoencoder 의 학습을 시킨다.
- 이후 첫번째 layer 의 weight 는 고정시키고, 두번째 layer 를 학습시킨다.
- 이번에는 입력을 첫번째 layer 에서 얻어지는 출력 을 입력으로 하고, 출력도 로 설정한다.
- 세 번째 layer 도 비슷한 방식으로 입력은 , 출력도 로 수행한다.
- 이렇게 마지막 layer 까지 반복적으로 학습하고, Layer-wise Pre-training 종료
이러한 학습 방법은 gradient vanishing 문제를 완화시킬 수 있었기에 혁신적인 연구였다.
하지만 지금은 GPU 성능 향상 및 대용량 데이터 확보와 같은 외부적인 영향으로 예비 학습 과정을 거치지 않아도 충분한 성능을 얻을 수 있게 되었다.