Value Function
state 에서 policy 를 따를 경우 state-value function 은 다.
terminal state 의 값은 항상 임을 기억하자.
비슷하게, 에서 를 따르는 경우 를 취할 때의 action-value function 는 다음과 같이 정의된다.
state-value function 와 action-value function 의 function 간 recursive 관계는 매우 중요하다.
위의 가장 마지막 수식을 Bellman Equation 이라 한다.
expectation 을 구하는 것이기 때문에, 발생할 수 있는 모든 경우의 확률을 구하는 것이 필요하다.
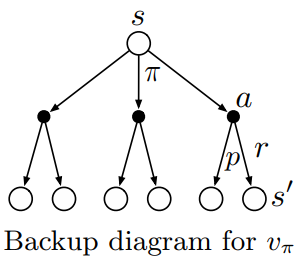
그래서 위의 그림 (backup diagrams) 처럼 에 대해서, 에 대해서, 에 대해서, 총 3 개에 대한 확률을 구할 필요가 있다 ()
the value of the start state () must equal the (discounted) value of the expected next state (), plus the reward expected along the way.
state-value function 와 action-value function 의 의존관계는 다음과 같이 표현될 수 있다.
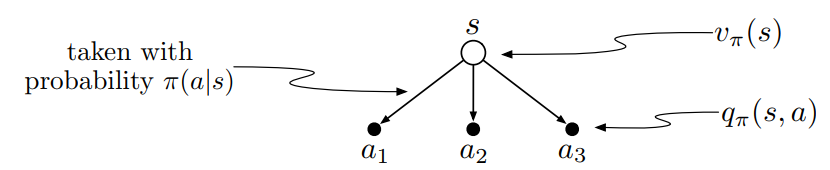
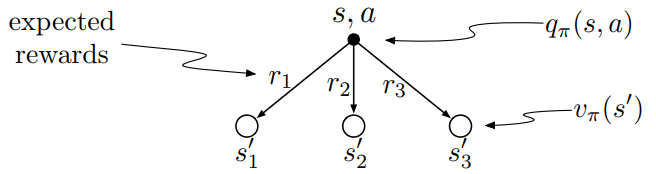
Optimal Value Function
optimal state-value function
최적의 policy 에 대한 state-value function
는 모든 policy 에 대해서 를 만족한다.
if and only if for all
optimal action-value function