Monte Carlo Method
Monte Carlo Method 방법은 경험 (experience) 이 필요하다. 경험이란 환경과의 상호 작용을 통해 얻어지는 일련의 states, actions 그리고 rewards 의 sample 을 의미한다.
MC 방식은 MDP 를 알 수 없는 상황에서 value function 을 추정한다는 관점에서 model-free prediction 방식으로 불린다.
B) Monte Carlo Prediction
우선 몬테 카를로 방법으로 주어진 policy 에 대한 state-value function 을 찾는 것을 생각해보자.
state 의 값은 expected return 값이다 (expected cumulative future discount reward). experience 에서 state 값을 찾는 방법은 해당 state 를 방문 하고나서 측정된 returns 들의 평균을 구하는 것이다. 만약 많은 returns 들이 관찰된다면, 구해진 평균은 expected value 에 수렴할 것이다.
반면, 두 MC 방법은 모두 에 대해 방문하는 횟수가 무한으로 증가할수록 가 수렴한다.
MC 는 평균 sample returns 값을 이용하여 강화 학습 문제를 해결한다. 여기서는 terminal state 가 있는 episodic task 만 고려한다.
C) DP Vs MC
C.1) 차이점
MC 는 환경에 대한 dynamics 을 알 필요가 없다. 반대로 DP 는 다음 events 에 대한 모든 확률 분포를 알아야된다.
MC 도 transition 확률을 알 필요는 있다. 그렇지만 이것도 DP 처럼 가능한 모든 transitions 에 대한 확률 분포가 아닌 sample transitions 에 의해 생성되기만 하면 된다.
one-step transitions 을 통해 value 를 update 하는 DP diagram 과 달리, 몬테카를로 방법은 terminal state 까지의 trajectory 를 확인하고 value 를 estimate 한다.
이를 도식화 하면 아래와 같다.
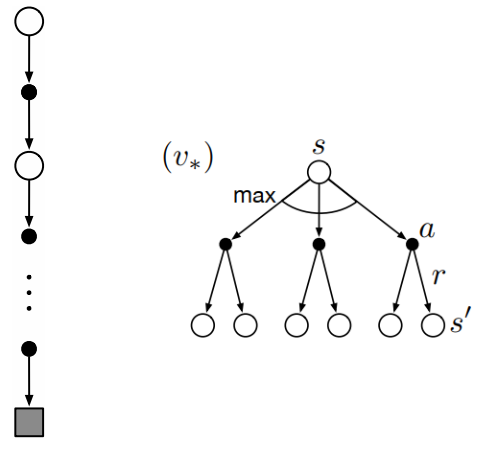
또한 MC 의 state 에 대한 value 추정값은 독립적이다. DP 는 반대로 다른 state 를 활용하여 특정 state 의 value 추정을 시도한다 (bootstrap).
D) Monte Carlo Estimation of Action Values
모델을 활용하는 것이 불가능하다면, state 값 대신, action 값 (state 와 action 의 쌍으로 이루어진 값) 을 추정하는 것이 유용하다.
DP 처럼 모델이 존재한다면, state value 와 transition probability 를 알기 때문에, 값을 이용해 policy 를 결정하는것이 충분했다.
MC 의 궁극적인 목적은 값을 추정하는 것이다 (policy evaluation for action values).
- policy evaluation for action values 는 를 추정하는 것
- : 에서 를 선택하고, 를 따랐을 때 얻을 수 있는 expected return
- pair 의 visit: 를 visit 하고 action 가 에서 취해졌을 때 visit 한다고 말함
- 이러한 접근의 문제점은 대부분의 state-action pair 의 값들은 visit 되지 않을 수 있다는 것이다 (경우의 수가 너무 많아서).
- 결과적으로, action 값을 비교해서 policy 를 정해야되는데 그러지 못하는 불상사가 생긴다.
Monte Carlo Control
DP 와 비슷한 GPI(Generalized policy iteration) 방식으로 MC 도 optimal policies 를 approximate 할 수 있다.
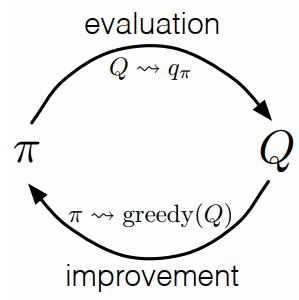
는 complete policy improvement 이고, 는 complete policy evaluation 이다.
- policy evaluation
- policy evaluation 은 first-visit MC prediction 과 완전히 동일하게 수행된다.
- policy evaluation 의 문제는 근사한 action-value 를 찾기 위해서는 evaluation 를 거의 무한히 반복해야된다는 것이다.
- DP 는 value-iteration 처럼 한번만 평가하고 improvement 하던가, single state value 를 평가할 때마다 improvement 하는 in-place 형식으로 진행했다 (아니면 policy-iteration 에서 처럼 특정 threshold 미만이면 evaluation 을 멈추던가).
- policy improvement
- action-value function 를 찾았기 때문에, 모든 에 대해서, 바로 다음과 같은 action 을 취하면 된다.
- 즉, 를 통해서 을 찾으면 되는데, 이렇게 찾아진 와 의 관계는 모든 에 대해서 다음과 같다.
E) MC Exploring Starts
MC 는 episode 마다 evaluation 과 improvement 를 번갈아 수행하는 것이 자연스럽다.
각 에피소드마다 관측된 returns 값들은 evaluation 과, 에피소드에서 마주친 모든 에 대한 improvement 에 사용된다.

- 여기서 exploring starts 의 가정을 위해, 특정 state 에서 시작하는 것이 아니라, 임의의 pair 에서 시작해서 episode 를 진행한다.
- MC ES 는 조금 비 효율적이다. 왜냐면, 를 저장하는 list 를 계속 보관하면서 평균 ( average Returns ) 을 구하기 때문이다. (이를 조금만 수정하면 좋아질수있다)
- MC ES 는 궁극적으로 최적의 해에 도달하는데, 이를 공식적으로 증명하진 못했다.
-
If it did, then the value function would eventually converge to the value function for that policy, and that in turn would cause the policy to change.
-
F) Monte Carlo Control without Exploring Starts
Exploring starts 는 모든 를 무한히 확인해봐야 한다는 가정이 존재한다. 이러한 가정을 보장하는 방법으로는 on-policy 방법과 off-policy 방법이 존재한다.
On-policy 방법은 생성된 sample 을 기반으로 policy improvement 와 evaluate 를 진행한다.
- MC ES 는 on-policy 방법의 example 이다.
- 반대로, off-policy 방법은 생성된 sample 과 다른 것을 이용해 policy improvement 와 evaluate 를 진행한다.
- On-Policy
- On-policy 방법은 soft 성질을 가진다.
- soft 성질이란, 항상 를 만족하지만, 점점 deterministic optimal policy 에 접근하는 것을 의미한다.
- 이를 위한 방법으로 -greedy policies 가 있다.
- 대부분 action 을 결정할 때, 추정된 action 값 중 최대 값에 해당하는 action 을 고르지만, 확률 으로 임의의 행동을 선택한다.
- 이 말은 모든 nongreedy 값에 대한 action 은 최소한의 선택 확률이 존재한다는 것이다 ().
- 즉, soft 성질을 만족한다:
- 
- 참고로 에 해당하는 action 은 딱 하나로 정해졌기에 다음이 성립한다.
-
- Policy improvement theorem of On-policy first-visit MC control
- DP 에서는 가장 큰 action-value 에 해당하는 action 을 선택하면 항상 최적의 policy 로 수렴한다는 것이 보장됬다 (policy improvement theorem).
- 위와 같은 알고리즘도 보장되는가?
- 를 -greedy policy 라 가정할 경우, 어떤 에 대해서 policy improvement theorem 이 다음과 같이 적용된다.
-
- 은 총합이 1 이되는 음이 아닌 가중치를 적용한 평균이고, 이를 모두 더하면 1 이 된다. 결과적으로, 최대값에 대한 평균보다는 반드시 작거나 같아야한다.
-
Off-policy Prediction via Importance Sampling
- Off-policy 는 두가지 policy 를 통한 전체 process 를 의미한다.
- target policy: optimal policy 를 위해 최적의 행동을 찾아서 수행하는 정책
- behavior policy: 탐험적이고 다양한 sample(behavior) 을 생성하기 위해 수행하는 정책
- 장/단점
- Off-policy 는 서로 다른 정책으로부터 학습하기 때문에 variance 가 크고 수렴 속도가 느리다.
- 그러나 더 일반적이고 강력하다.
- 일반적 (general): on-policy 는 off-policy 의 target 과 behavior policy 가 동일한 경우의 special case 다.
- Off-policy prediction
- 두 policy, : target policy, : behavior policy 가 존재
- 를 따른 에피소드를 통해 얻어진 samples 로 에 대한 values 를 estimate 해보자.
- 올바른 수렴 (coverage) 의 보장을 위해 에서 수행되는 행동은 적어도 때때로 에서도 행해져야 한다.
- 즉, 가 를 의미해야 한다.
- 해당 보장이 만족되면, 학습이 반복될수록, target policy 는 a deterministic optimal policy 가 되고, behavior policy 는 stochastic and more exploratory 한 policy 가 된다.
- importance sampling
- 대부분의 off-policy 는 importance sampling(중요도 추출법) 을 사용한다.
- 이 방법은 어떤 분포로 얻어진 sample 이 주어질때, 그 sample 을 이용하여 다른 분포에서 얻을 수 있는 expected value 를 추정하는 방법이다.
- importance-sampling ratio
- target 과 behavior policy 를 통해 얻어지는 trajectory 를 이용해 importance-sampling ratio 라는 상대적 확률을 계산할 수 있다.
- 이 확률에 따라 return 값에 가중치를 부여하는 방식으로 importance sampling 을 수행할 수 있다.
- 에서 시작해서, policy 하에 발생하는 state-action trajectory () 에 대한 확률은 다음과 같다:
- 는 state-transition probability function 이다.
- 위 확률을 이용해서 얻어지는 target 과 behavior polices 의 relative probability 는 다음과 같다:
- target 과 behavior policy 를 통해 얻어지는 trajectory 를 이용해 importance-sampling ratio 라는 상대적 확률을 계산할 수 있다.
- Off-policy 는 두가지 policy 를 통한 전체 process 를 의미한다.
- 가 서로 동일하므로 서로 약분하여 사라지고, 결과적으로 importance-sampling ratio 는 policy 에 따른 결과에만 영향을 받는다.
- 원래는 target policy 로 부터 expected returns 값을 추정했지만, 이제는 behavior policy 에 의한 returns 값만 있다.
- 이 값은 를 계산할수는 있지만, 를 계산할 수는 없다. 이때, importance sampling 을 활용한다.
- Ordinary importance sampling
- 를 추정하기 위해, scaling 과 average 를 적용한 의 정의는 다음과 같다.
-
- 는 time step 으로, episode 에 관계없이 1 부터 시작하는 자연수 값이다.
- 여기서 는 상태 를 visited 한 모든 time steps 의 집합을 의미한다.
- 는 이후에 나타나는 최초의 termination time 을 의미한다.
- 예를 들어, 에서 시작해서 에 끝난다면, T(t)=100\(1\let\le100) 이다.
-
- Weighted Importance sampling
- 가중치가 적용된 평균을 구하는 방법이다 (분모쪽이 다름).
-
- 분모가 0 일 경우, 분자도 0 이 된다.
-
- First-visit methods for Ordinary vs Weighted
- Ordinary : bias 가 없음, variance 의 값이 매우 커질 수 있음 (unbounded)
- Weighted : bias 가 존재함 (하지만 학습하면서 수렴), variance 가 작음
- Every-visit methods for Ordinary vs Weighted
- Ordinary 와 Weighted 상관없이 둘 다 편차가 존재함. (하지만 결국 0 으로 수렴)
- 가중치가 적용된 평균을 구하는 방법이다 (분모쪽이 다름).
-
Incremental Implementation
- 이제 실제로 importance sampling 을 이용해서 off-policy MC 를 구현하는 방법에 대해 알아보자.
- MC 는 평균 returns 을 활용하는 방법이라는 것을 기억하자.
- 이러한 점은 평균 rewards 를 활용하는 incremental methods 와 비슷하다.
- Incremental Implementation
- 다음과 같은 rewards 의 평균 값 은 incremental method 를 통해 효율적으로 구해질 수 있다.
- 이제 MC 구현으로 돌아가서, 모두 같은 state 에서 수행한 일련의 returns 값 이 존재하고, 임의의 가중치 (e.g. ) 가 존재한다고 하자.
- 이들을 이용해서 을 다음과 같이 추정한다 (weighted 방식).
- 그리고 을 구하는 것은 다음과 같이 계산된다.
- 은 개의 returns 에 주어지는 가중치의 누적합을 의미하고, 이다.
- (또한 은 임의의 값으로 처리해도 무방함)

- (또한 은 임의의 값으로 처리해도 무방함)
- 위 알고리즘은 weighted importance sampling 을 이용한 off-policy 방법이지만, target 과 behavior policy 를 동일하게 만든 on-policy 경우에도 동일하게 먹힌다.
- 이 경우 이고, 는 항상 1 이다.
- 가 와 다른 정책을 통해 모든 action 이 선택되는 동안 근사 값은 에 수렴한다.
- Off-policy Monte Carlo Control
- 근사 를 찾았다면, 이를 활용하여 policy 를 update 하는 control 을 살펴보자.
- Control 방법은 behavior policy 를 따르고 target policy 를 improve 한다.
- behavior policy 는 target policy 가 선택할 수 있는 모든 actions 들을 수행할 확률이 있어야 한다. (soft policy: all actions in all states with nonzero probability)

- weighted importance sampling 과 GPI 에 기반한 control method
- 이전의 policy evaluation 과 달리 control 은 update 를 위해서 대신 를 곱한다.
- 이래도 올바르게 동작하는 이유는 가 의 경우에만 업데이트 될 뿐더러, 가 deterministic 하므로 로 설정해도 업데이트에 문제가 없다.
- 가 의 경우에만 업데이트되는 이유는 target policy 와 behavior policy 가 동일한 action 을 취하는 경우기 때문에
- 만약, 조건을 지웠다면 업데이트 방식도 이전과 동일해야한다.
- 이래도 올바르게 동작하는 이유는 가 의 경우에만 업데이트 될 뿐더러, 가 deterministic 하므로 로 설정해도 업데이트에 문제가 없다.
- 실제 구현을 해보니 이전의 evaluation version 이 훨씬 수렴성이 좋다.
- behavior policy 는 target policy 가 선택할 수 있는 모든 actions 들을 수행할 확률이 있어야 한다. (soft policy: all actions in all states with nonzero probability)