Bellman Optimality Equation
state-value function 에 대한 Bellman Equation 은 다음과 같다.
하지만 optimal state-value function 는 가 필요없다. 왜냐하면 항상 최적의 policy 는 누적 보상을 최대화하는 action 을 이미 알고있기 때문이다.
결과적으로 optimal policy 에 대한 state-value function 에 대한 bellman 수식, 즉, bellman optimality equation 은 다음과 같이 바꿔쓸 수 있다.
A.1) 식 풀어 쓰기
여기서 는 이전에 수식을 활용하여 유도된다.
A.2) For Action-value Function
optimal action-value function 에 대한 Bellman Optimality Equation 은 다음과 같다.
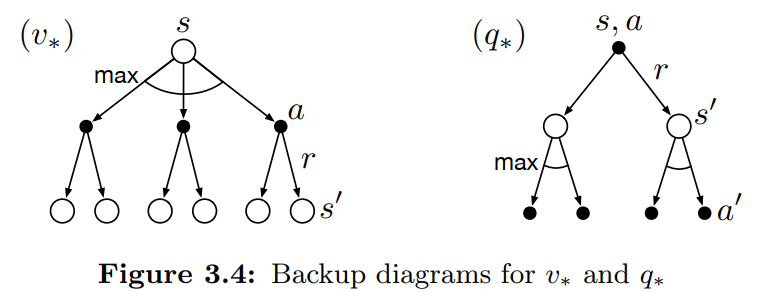
Bellman Optimality Equation 을 푸는 것은 optimal policy 를 찾는데 사용할 수 있다. 하지만 실제로는 그렇게 유용하지 못한데, 왜냐하면 다음과 같은 세가지 조건이 만족되어야 하기 때문이다.
- 환경에 대한 dynamics 를 정확히 알아야 한다.
- 계산을 위한 충분한 자원이 있어야 할 것
- state 가 Markov property 를 따를 것
예를 들어 벡가몬 게임의 경우 (1), (3) 은 만족하지만 (2) 의 경우 에 대한 경우의 수를 처리해야 한다.