REINFORCE
REINFORCE 방식은 몬테카를로 방식의 Policy Gradient 이다. 즉, 큰 분산 (high variance) 을 가질 수 있고, 따라서 학습 속도가 느려질 수도 있다.
policy gradient theorem 의 우변은 policy 하에서 얼마나 자주 state 들이 발생할 것인지에 따라 가중치를 적용한 합계다. 즉, 를 따른다면, 가중치 (weight) 에 해당하는 비율로 각 state 를 마주칠 (encounter) 것이다.
이제 위 식을 stochastic gradient-ascent algorithm 에 사용할 수 있다.
- 은 에 대한 학습된 근사값이다.
- 위 update algorithm 은 all-actions method 라고 부린다. 왜냐하면 모든 actions 에 관련된 update 를 진행하기 때문이다. 하지만, 모든 actions 에 대한 sample 을 전부 모으기는 너무 많은 시간이 소요되므로, 각 state 가 아닌 각 action 에 대해서 update 를 진행할 필요가 있다.
- REINFORCE 알고리즘은 대신, 에 대한 update 를 수행한다.
- 는 에 취한 하나의 action 을 의미한다.
- 위의 식은 expectation 계산에 필요한 와 같은 가중치를 주지 않았다. 그래서, 위 식과 동일하게 만들도록, 를 도입하되, 를 다시 나누는 방식으로 equality 를 유지한다.
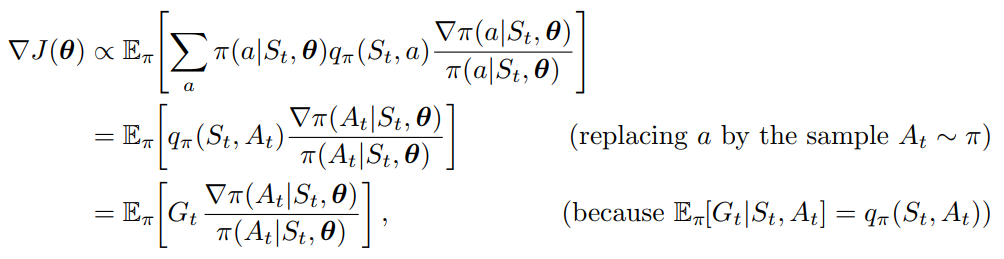
- 는 return 을 의미한다.
- 이제 이 식을 이용해서 stochastic gradient descent algorithm 을 수행한다. 이 방식을 REINFORCE update 라 한다.
-
- 벡터 의 방향은 미래에서 를 마주쳤을 때, 행동 를 취할 행동 확률을 가장 많이 증가시키는 방향이다.
- 그리고, 이 방향이 업데이트 되는 정도 는 보상을 많이 받을수록 커지고, 적게 받을 수록 줄어든다.
- 결과적으로, 이득 (return) 을 가장 많이 산출하는 행동을 선호하는 방향으로 parameter 가 이동할 것이다.
- 벡터 의 방향은 미래에서 를 마주쳤을 때, 행동 를 취할 행동 확률을 가장 많이 증가시키는 방향이다.
- REINEFORCE 는 시간 부터 계산되는 완전한 return 을 사용한다. 즉, 에피소드가 끝날 때 까지의 미래 보상들을 전부 더한 값을 이용하므로, REINEFORCE 는 몬테카를로 (MC) 알고리즘이고, episodic case 의 경우에 대해서만 잘 사용될 수 있다.

- 마지막 줄 은 update 방식과 다르게 보이는데, 이는 벡터 에 대해서 압축적 표현으로 를 사용한다는 것이다. ()
- 또한 update 방식에는 사용되지 않은 discount factor 가 적용되었는데, update 방식이 인 경우에 대한 식이기 때문이다.
REINFORCE with Baseline
어떤 상태에서는 모든 행동이 높은 가치를 가지기 때문에 가치가 더 높은 행동을 가치가 낮은 행동과 구별하기 위해서는 높은 기준값이 필요하다.
반대로, 어떤 상태에서는 모든 행동이 낮은 가치를 가질 것이고, 이 경우에는 낮은 기준값이 적절하다.
- 즉, policy gradient theorem에 기준값 (baseline) $b(s)$을 추가함으로써 [[REINFORCE]]의 [[variance]]를 크게 감소시킬 수 있다.
- $\displaystyle\nablaJ(\boldsymbol{\theta})\propto\sum_{s}\mu(s)\sum_{a}\left(q_{\pi}(s,a)-b(s)\right)\nabla\pi(a\mids,\boldsymbol{\theta})$
- $b(s)$는 function 또는 random variable등 이 될 수 있다.
- 기준값을 추가해도 policy gradient theorem이 equality를 유지할 수 있는 이유는, baseline에 따라 행동 $a$이 변하지 않으면 되기 때문이다.
- $\displaystyle\sum_{a}b(s)\nabla\pi(a\mids,\boldsymbol{\theta})=b(s)\nabla\sum_{a}\pi(a\mids,\boldsymbol{\theta})=b(s)\nabla1=0$
- Baseline을 추가한 새로운 update 방식은 다음과 같다.
- $\displaystyle\boldsymbol{\theta}_{t+1}\doteq\boldsymbol{\theta}_{t}+\alpha\left(G_{t}-b\left(S_{t}\right)\right)\frac{\nabla\pi\left(A_{t}\midS_{t},\boldsymbol{\theta}_{t}\right)}{\pi\left(A_{t}\midS_{t},\boldsymbol{\theta}_{t}\right)}$
- 기준값을 선택하는 자연스러운 방법 중 하나는 state value $\hat{v}\left(S_{t},\mathbf{w}\right)$ 의 추정값을 기준값으로 선택하는 것이다.
- $\mathbf{w}\in\mathbb{R}^{d}$ 는 weight vector다. ($\boldsymbol{\theta}$ 와 다른 추가적인 weight vector)
- 이렇게 두개의 parameter $\mathbf{w}$, $\boldsymbol{\theta}$를 사용하면, 둘 다 동시에 몬테카를로 방법으로 학습하면 된다.
- ![[img-e1d812ee38.png|image-20201107001619998]]