Markov Decision Process
MDP 는 sequential decision-making 문제를 풀기위한 모델을 설정할 때 사용할 수 있는 프레임워크를 의미한다.
A.1) MDP 구성 요소
MDP 는 Markov Reward Process 와 다르게 Action 이 추가된 구성을 가진다.
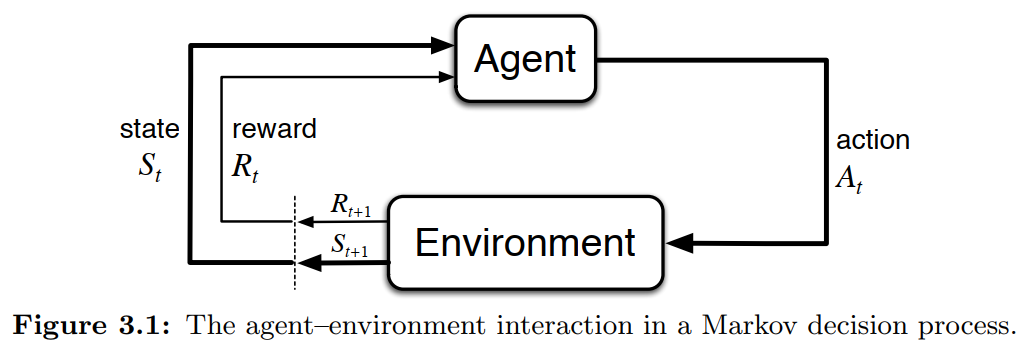
- States : (states 는 다양한 형태로 존재할 수 있음)
- Action:
- Reward :
MDP 의 time 는 굳이 시간에 대한 개념이 아니라 stages 로 생각하면 좋다.
A.2) Markov Property
Markov property: MDP 의 와 는 무조건 와 에 의해서만 영향을 받음
B) Dynamics of the MDP
time step 에서 를 통해 에서 으로 옮겨서 를 받을 확률
- 는 definition 이라는 뜻
가능한 모든 dynamics 를 더하면 1 이 된다.
C) State-transition Probabilities
상태 전이 확률은 다음과 같이 계산된다.
- dynamics of the MDP() 의 three-arguments 버전
- 에서 받을 수 있는 reward 에 대한 확률을 다 합친 것임
Expected rewards
에서 를 수행했을 때, 받을 수 있는 reward 의 기댓값 (expectation)
- 에서 를 수행하여 로 이동했을 때, 받을 수 있는 reward 의 기댓값
는 다음과 같음
D) MDP in Recommendation Scenario
- States: time step 에 존재하는 interaction history 의 representation
- actions: 추천 가능한 후보 아이템들의 전체 집합
- Transition probability: agent 가 사용자 feedback 을 받고 state 에서 으로 넘어갈 확률
- Reward Function : user’s feedback
- : Discount Factor