Gradient Descent
ML 모델 에 대한 적합한 ( 와 같은) parameter 를 찾기 위한 방법
B) Visualization of Gradient Descent
아래는 parameter 와 에 대한 loss function 의 등고선 그래프이다. 이 그래프의 사용 목적은 비용 함수 가 등고면 바닥에 닿을 수 있는 parameter 를 찾기 위함이다. 즉, 두 parameter 의 적절한 값을 찾기 위해 비용 함수를 미분하여 어느 방향으로 parameter 값을 조정해야 하는지 확인 해야한다.
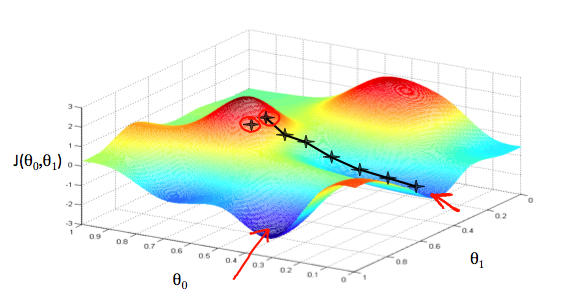
- 위의 십자가 모양의 표시는 parameters 가 변화한 순간들을 포착한 것이다.
- 변화한 순간의 간격이 일정한 듯 보이는데, 이러한 간격 (size of each step) 을 결정하는 것은 라는 학습률 (Learning rate) 이 결정한다.
- 또한 의 값이 어디서 시작하냐에 따라서 (그림에서의 두 빨간 동그라미들), parameter 가 수렴하는 값이 달라진다.
C) Gradient Descent for 2 Dim
gradient descent 알고리즘은 다음과 같은 수식으로 표현된다.
중요한 점은 각 parameter 에 대하여 업데이트 할 값 () 을 먼저 모두 구하고, parameter 의 값들을 update 해야 한다는 점이다.
아래 그림은 올바른 또는 올바르지 않은 update 방식을 나타낸다.
![[img-ed29cf33b4.png|img]]
- 는 assign 의 의미가 있으며, 는 assert 의 의미가 있다. 즉, 는 의 값을 에 부여하고, 는 와 의 값이 일치하는지 확인하는 것이다.
D) Gradient Descents 의 직관적 이해
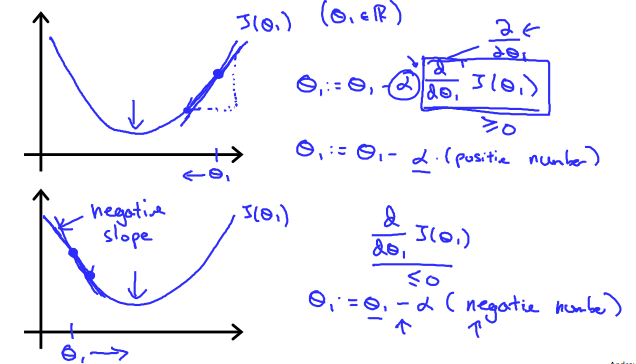
비용 함수 에서, parameter 을 찾기 위해, 다음과 같은 gradient descent 를 반복한다고 가정하자.
위의 식은 의 값은 점점 이 에 수렴하는 방향으로 update 될 것이다.
그 이유는 아래 그림을 참조하자.
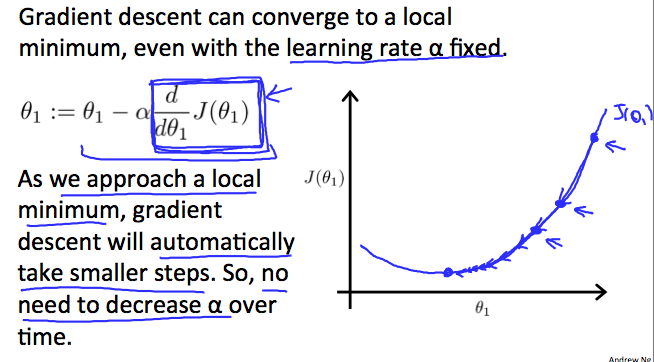
여기서 의문이 생길 수 있다: learning rate 값이 크다면 step size 가 커져서 가 수렴하지 못할 텐데, 이 수렴하는 과정에서 값도 점점 줄여줘야 하는 것인가?
답: 적절한 값만 설정한다면, 그럴 필요 없다. 왜냐하면 값이 수렴할수록, 값도 0 에 가까워지므로 step size 가 감소한다.
E) 예시
E.1) Gradient Descent For Linear Regression
의 비용 함수 을 이용하여 gradient descent 를 진행해보자. MSE 를 고려한 비용 함수 는 다음과 같다.
그리고 에 적용되는 Gradient Descent 는 다음과 같다.
여기서 를 의미한다.
위 식을 풀어 쓰면 다음과 같다.
SGD
전체 데이터에 대한 gradient를 한번에 계산(i.e. batch GD)하지 않고 일부 example만 batch로 샘플링하여 계산하는 방식을 stochastic gradient descent라 한다.
이때 batch size 이면, 이를 online 또는 incremental learning이라고 부른다. 그리고 을 만족하는 경우는 mini-batch GD 라고 불리는데, 그냥 SGD로 혼용되어 불리기도 하는 것 같다.
Mini-batch GD
Use examples in each iteration where is the mini-batch size (e.g. and ).
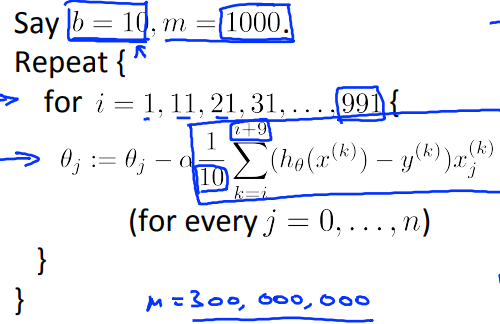
Choosing Your Mini-batch Size
- 학습 데이터 개수가 작을 경우 (약 2000 이하), batch gradient descent를 사용
- 일반적인 mini-batch sizes: 64, 128, 256, 512, (가끔 1024)
- 추가로, 모든 mini-batch 사이즈가 CPU 또는 GPU 메모리에 들어가도록 할 것
Related
Newton-Raphson method Batch Gradient Descent