GMM
GMM 이란, 여러 Gaussian distribution 이 혼합된 모델을 의미한다.
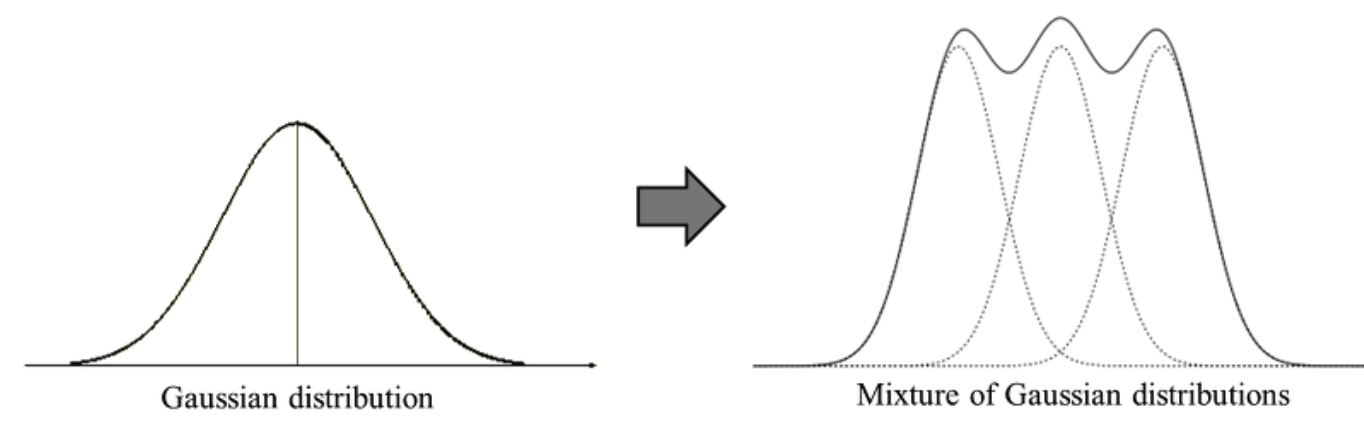
B) GMM
주어진 데이터 가 GMM 에서 발생할 확률
는 mixing coefficients 라고 부르며, 일종의 weight 역할을 한다. 즉, 어떤 가우시안 분포에 포함되는지 soft clustering 같은 의미 부여 역할을 한다.
- 도 확률 분포의 특성을 가지므로, multinomial distribution 을 따른다.
개의 가우시안 분포에서 가 발생할 확률을 전부 더한다고 생각하고, 특정 분포가 선택된 것을 표기할때 로 둔다고 하면 다음과 같이 표현이 가능하다.
개의 가우시안 분포에서 가 발생할 확률을 전부 더한다고 생각하고, 특정 분포가 선택된 것을 표기할때 로 둔다고 하면 다음과 같이 표현이 가능하다.
개의 가우시안 분포에서 가 발생할 확률을 전부 더한다고 생각하고, 특정 분포가 선택된 것을 표기할때 로 둔다고 하면 다음과 같이 표현이 가능하다.
- selection variable 는 다음과 같은 특성을 갖는다
:
- Log likelihood of the dataset
- Classification of GMM
- 이 주어졌을 때, 번째 가우시안 분포에 포함될 확률을 계산
- 이 확률을 responsibility 라고 표현한다.
- 이 주어졌을 때, 번째 가우시안 분포에 포함될 확률을 계산
- 분수 형태로 바뀐 이유는 Bayes theorem 을 적용했기 때문
C) Training GMM: EM algorithm
C.1) Expectation Step: the Assignment Probability
Given the parameters and the data point, calculate the likelihood
가 주어졌을 때, 를 계산한다. 즉, 각각의 데이터 포인트가 어떤 가우시안 분포에 속하는지의 확률을 계산한다.
C.2) Maximization step
Update the parameters given
총 3 개의 변수들에 대해서 likelihood 를 각각 미분한 후, 0 이 되는 값을 찾음
mixing coefficient 는 constraint 이 존재하므로 Lagrange multiplier method 를 적용하였다.
각 parameter 는 를 활용하여 다음과 같이 계산될 수 있음
- 모든 parameter 를 계산하면, 다시 E-step 으로 돌아가서 를 재 계산한다. 이를 수렴할때까지 반복한다.
C.3) Why not Use Gradient Descent Method?
stochastic gradient descent 를 이용해서 학습할 수 있지만, 두 가지 이유로 EM 보다는 비 효율적이다.
- GMM 에서의 가우시안 분포들의 covariance matrix 는 [positive semi-definite](positive definite) 여야 한다는 조건이 붙는다. 하지만 SGD 로는 이러한 제약조건을 명시하면서 학습할 수 없다.
- EM 방식은 주어진 문제의 structure 를 활용할 수 있다. 즉, SGD 보다 EM 이 더욱 적은 iteration 만으로도 optimal 한 결과에 다다를 수 있다 (더 낮은 loss 또는 높은 likelihood 포함).
D) Expression of GMM by Bayesian network
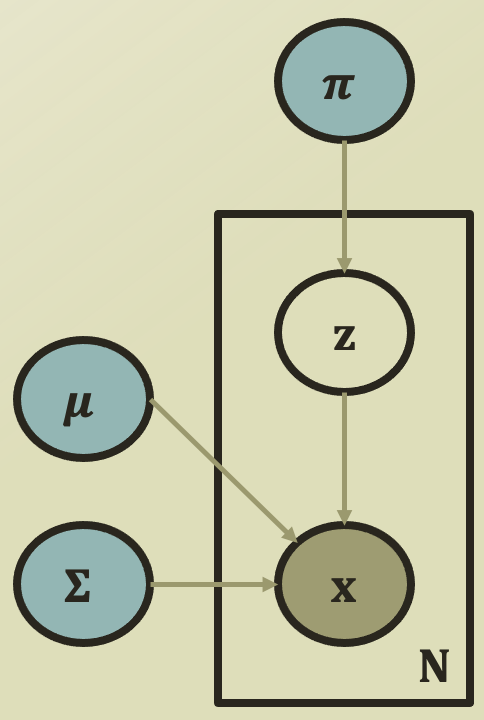
- 파란색 원은 parameters, 갈색 원은 observations, 은 데이터셋 개수를 의미