Cross-validation
cross-validation 은 데이터를 나눠서 모델을 검증하는 방식을 의미한다.
B) 교차 검증을 사용해야 하는 이유?
고정된 training set 에 대한 overfitting 현상을 막기 위해서 사용한다. 즉, 더 일반화된 모델을 학습하기 위해서 사용한다.
C) Cross Validation 종류
C.1) Holdout Cross-validation
가장 일반적인 교차 검증 방법으로서, training set 의 일부를 validation set 으로 나누어 검증하는 방법이다.
일반적으로 8:2, 7:3, 9:1 등으로 비율을 나눠서 사용한다.
validation 데이터에 대해서 가장 낮은 error 를 보이는 모델을 선정하고, 최종 (best) 모델은 전체 데이터를 이용하여 학습한다.

C.1.1) 단점
- Holdout cross-validation 방법은 validation data 가 고정되어 있다는 문제가 존재한다.
- 즉, validation 에 의에 검증된 모델은 해당 validation dataset 에 overfitting 될 가능성이 높다.
C.2) K-fold Cross-validation
전체 데이터 셋을 개의 validation subset 으로 나누고 번의 평가를 실시하게 되는데, validation set 은 겹치는 구간이 없도록 만들어서 모델의 평가를 각각 진행한다.
여기서 는 hyperparameter 이고, 나눠진 validation subset 을 data fold set 이라고 부른다.

이후 개의 평가 지표를 aggregate (e.g.평균) 해서 최종적으로 모델의 성능을 평가하게 된다.
C.2.1) Pros and Cons
Pros
모든 데이터 셋을 평가에 활용하여 모델이 특정 데이터에 overfitting 되는 현상을 막을 수 있고, 모델의 성능을 향상 시킬 수 있다.
Cons
가 높을수록, 데이터를 나누고 학습 및 평가하는 횟수가 많아지므로, 시간이 오래 걸린다.
C.3) Leave-p-out Cross-validation
전체 데이터 (서로 다른 데이터 샘플들) 중에서 개의 샘플들을 선택하여 모델 검증에 사용하는 방법이다.
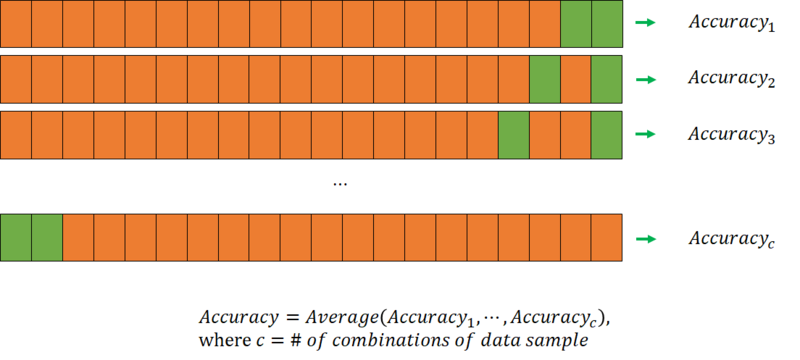
Validation set 을 구성할 수 있는 경우의 수는 이다 ( 은 데이터 샘플의 총 개수).
-fold cross-validation 과 마찬가지로, 각 data fold set 에 대하여 나온 검증 결과들을 aggregate 하여 최종적인 검증 결과를 도출하는 것이 일반적이다.