Introduction
- 추천 시스템에서 발생하는 loop 는 bias 를 일으킴
- (1) collect data, (2) train model, (3) deploy model loop
- off-policy learning 에서 biased data 로 부터 unbiased learning 을 지향하는 방법에는 importance sampling or [Inverse Propensity Score (IPS) weighting](inverse propensity score) 이 존재함
- [value-based models](value-based method)
1.1. Contributions
- off-policy recommendation 을 위한 reward model 에서 explicit pessimism 의 사용법을 제안
- 추천의 맥락에서 the Optimiser’s Curse 라는 decision-making 현상을 소개하고, 일반적인 naive reward 모델이 어떻게 영향을 받는지 보임
- pessimism 을 표현하기 위해 ridge regressor 의 posterior mean 과 variance 를 closed-form 으로 estimate 하는 방법을 제시하고, off-policy recommendation 에서 효율적으로 적용하는 방법을 제시
- 시뮬레이션을 통해 pessimism 이 ML 또는 MAP 기반 decision-making 방식과 비교해서, 온라인 추천 퍼포먼스를 향상시킬 수 있음을 보임
- target problem: [Batch Learning from logged Bandit Feedback (BLBF)](batch learning with logged bandit feedback, BLBF)
- online learning 과 달리, batch learning 은 system 상의 상호작용이 필요 없고, 기존 데이터를 재사용 할 수 있을 뿐만 아니라 offline cross-validation 기법도 적용이 가능함
2. Background and Related Work
- off-policy or counterfactual setting
- a dataset: , where and
- : context, : action, : reward
- logging policy : The policy that was deployed at data collection time
- a dataset: , where and
- Comparison with inverse propensity score and value-based method
-
- value-based method 의 경우 logging policy 모델에 의존하지 않고, context 가 주어진 action 의 reward 에 의존함
- The Optimiser’s Curse in Recommendation
- assumption
- binary reward that follows a Bernoulli distribution with parameter
- the probability of a positive reward is independent of the context
- obtained value estimates are conditionally unbiased in that
- environment
- 모든 action 은 클릭에 대한 true probability 가 존재:
- Maximum Likelihood Estimation 또는 maximum a posteriori probability 를 적용하여 를 추정
- statement
- even though the reward estimates are conditionally unbiased, this process leads to a negative expected surprise:
- meaning that, we incur less reward than predicted.
- reward model 이 서로 unbiased 하기 때문에, 모델 자체의 문제가 아니고 가장 큰 action 을 선택하는 decision making 방식 때문에 이러한 현상이 발생함
- assumption
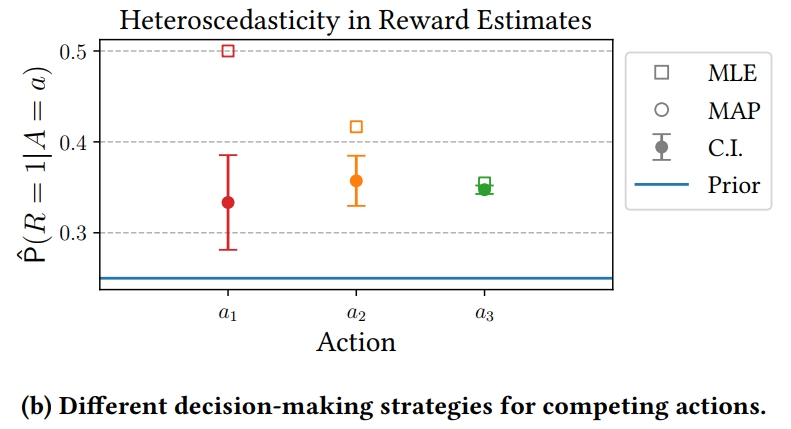
- heteroscedasticity in reward estimates
- a simple example
- Rewards for action are drawn as Bernoulli(), with ∼ Beta(, ).
- , , 으로 설정하고, prior 는 25% 확률로 클릭을 받는다고 설정:
- 많이 exploration 된 action 의 경우 variance 가 줄어서들어서 credible interval 이 tight 해진것을 알 수 있지만, under-explored 경우에는 error 와 variance 가 크게 늘어서 heteroscedasticity 의 현상을 보임
- 즉, under-explored context-action pair 들은 post-decision disappointment 에 취약하다.
- a simple example
- Pessimistic Decision-Making
- on-policy 의 Thompson sampling 이나 UCB 계열은 optimism 을 활용한 방식을 사용하지만, off-policy 설정에서는 불가능하다.
- 그러나 일반적으로 가장 maximal reward estimates 에 집중하는 naive 한 decision-making 방식은 위와 같은 방식과 크게 다를바가 없음
- 적절한 prior 를 설정하는 solution 은 unrealistic 함
- Lower Confidence Bound 를
- Pessimism in Policy Learning
- 이러한 pessimism 관련 아이디어는 기존에도 쉽게 확인할 수 있는 내용
이 외에도 variance regularisation, imitation learning, distributional robustness, 그리고 estimator lower bounds 등 이 offline RL 시나리오에서 pessimism 의 개념을 활용하고 있음
- Closed-Form Lower-Confidence-Bounds with Bayesian Ridge Regression
- Experiment
- logging policies
- 각 item 에 대한 history count 에 비례해서 policy 이 action 을 sampling
- 이렇게 하면 history 에 존재하지 않는 action 은 아예 뽑히지를 않게 되는데, 이는 inverse propensity score 가 unibased reward estimate 를 위한 가정을 위반하는 것임
- 또한, 아예 history 가 없는 경우 적절한 prior 나 conservative 한 decision making 을 진행
- 의 부족함은 -greedy 방식이 해결
- 각 item 에 대한 history count 에 비례해서 policy 이 action 을 sampling
- reco-gym 의 사용 이유는 off-policy 실험을 위한 public dataset 이 부족해서 그런것
- logging policies