Association Rule Learning
연관 규칙 학습은 데이터베이스에 존재하는 변수들 간의 연관성을 발견하는 방법이다. 여기서, 연관 규칙들은 일반적으로 사용자가 정의한 최소 support 값과 최소 Confidence 값을 동시에 만족시킬 수 있는 규칙을 의미한다.
연관 규칙은 일반적으로 다음과 같이 표기된다.
위 규칙은, 어떤 고객이 양파와 감자를 함께 샀다면, 햄버거도 같이 살 확률이 높다는 것을 의미한다. 이러한 정보를 기반으로 마켓팅 활동에 대한 결정을 내린다.
Notations with Example
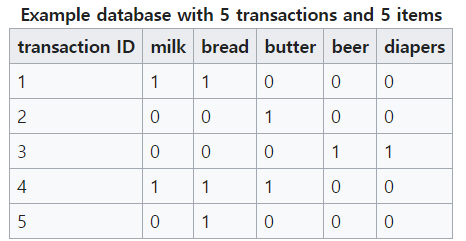
-
는 items 이라 불리는 개의 이진 속성들을 의미한다.
- 테이블 예시를 통해서 로 표현된다.
-
는 database 라 불리는 transactions 의 집합을 의미한다.
- 테이블 예시를 통해서 transaction 는 milk 와 bread item 으로 구성되있음을 알 수 있다.
-
에 존재하는 각 transaction 은 고유 ID 와 에 존재하는 items 의 부분 집합을 포함한다.
- ID = 1 인 은 라는 의 부분 집합을 가진다.
-
규칙은 다음과 같은 암묵적 형태로 표현된다: , where
- 또한 규칙은 특정 집합과 하나의 item 에 대해서만 정의된다: for
- 는 butter 와 bread 가 같이 구매되면, 해당 고객은 milk 도 함께 산다는 규칙을 의미한다.
-
연관 규칙 생성 Process
-
연관 규칙들을 생성하는 과정은 두 step 으로 분리된다.
- 최소 support 임계치 (threshold) 는 데이터베이스에 존재하는 frequent itemset 들을 전부 찾기위해 사용된다.
- 최소 Confidence 제약 (constraint) 은 (1) 에서 찾은 frequent itemset 으로부터 규칙을 형성하기 위해 사용된다.
-
과정 (2) 는 상당히 직관적이지만, (1) 에 대해서는 많은 연산량이 요구된다.
-
-
Algorithms
- 아래 주어진 알고리즘은 frequent itemset 을 효율적으로 찾기 위한 알고리즘이다.
- 해당 알고리즘은 오직 frequent itemset 을 찾는 과정에만 관여하기 때문에, 이후 찾은 itemset 에 기반하여 최소 confidence 값을 만족하는 규칙들을 찾는 것은 여러분들의 몫이다.
- Apriori
- Eclat
- FP-growth algorithm
- FP-Tree Mining
- 아래 주어진 알고리즘은 frequent itemset 을 효율적으로 찾기 위한 알고리즘이다.