Dropout
Dropout 방식은 neural network 의 overfitting 문제를 완화하기 위해, 사용자 정의된 확률에 기반하여 각 레이어의 일부 노드들을 계산에 포함시키지 않는 방법을 의미한다.
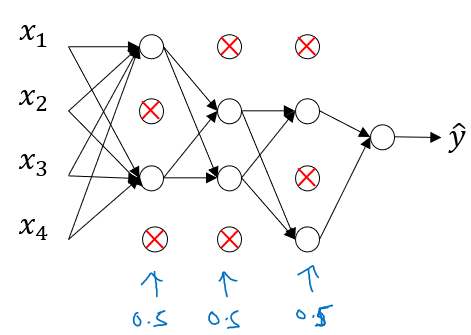
B) Example
코드 형식으로 dropout 이 적용되는 과정을 소개하겠다.
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob #1
a3 = np.multiply(a3, d3) #2
a3 /= keep_prob #3
# z4 = w4.dot(a3) + b4 ...d3은 boolean 형태 matrix 로, dropout 에서 살릴 units 들을 의미하며,a3은 3 번째 레이어의 출력을 의미한다. 즉,np.multiply(a3, d3)를 통해 노드의 출력을 살릴지 말지 결정한다.keep_prob은 사용자 정의된 확률을 의미한다.- 마지막
a3 /= keep_prob은 inverted dropout 이라는 기법인데, dropout 이 적용되더라도 layer 출력값a3의 기댓값이 일정하도록 유지해준다.
C) keep_prob
keep_prob=0.8 라면, 20% 의 노드들은 계산에 포함시키지 않겠다는 의미가 된다. 만약 keep_prob=1 이면, dropout 이 적용되지 않는 것이므로, inverted dropout 방법도 의미가 없어진다 (어차피 기댓값은 동일하므로).
C.1) keep_prob By Layers?
Dropout 확률을 레이어마다 다르게 유지해도 좋다. 다만, 이런 경우 각 layer 마다 hyperparameter 를 추가한것과 같으므로 tuning 에 추가적인 작업이 필요할 것이다.
D) Making Predictions at Test time
중요한 점은 dropout 으로 학습된 모델을 이용할 경우, 예측 단계에서는 dropout 을 사용하지 않아야 한다. 왜냐하면, dropout 은 순전히 임의로 유닛들을 죽이거나 살리므로, 이에 따라 모델의 출력값이 변화하면 안되기 때문이다.
그러나 RS 과정에서는 종종 exploration 을 위해 dropout 을 사용하기도 한다. Neural network 에서는 complexity 가 높으므로 Thompson sampling 과 같이 parameter 를 sampling 하는 것이 어렵다. 그래서 inference 에서도 dropout 을 켜서 확률적으로 output 을 다양화한다.
D.1) Concrete Dropout
dropout 확률을 자동으로 조절하는 방식이다.
E) Why Does Dropout Work?
직관적으로 설명하면 어떤 하나의 특징에만 의존할 수 없으므로, 가중치를 분산시켜야 하는 것이다.
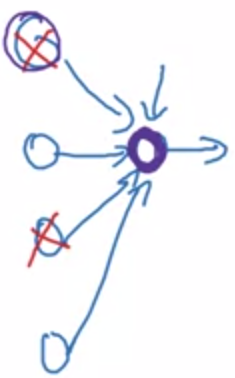
위 그림과 같이, 4 개의 units 중에 어떤 하나의 units 이 다음 output 을 결정하는데 중요한 역할을 한다고 해보자. dropout 은 그런 units 들을 종종 확률적으로 죽여서 다른 units 도 output 을 결정하는데 중요한 역할을 하게끔 만들어 준다.
이러한 효과는 weights 를 shrink 하게 하는 효과를 내는데, L2 norm 을 이용한 regularization 과 비슷한 효과를 발생시킨다.
F) Training with Dropout
Dropout 을 통해 학습하는 것은 확률적으로 units 을 죽이거나 살리므로, cost function 이 단조적으로 감소하지 않는다는 것을 의미한다. 결과적으로 dropout 을 적용한 모델의 cost function 을 iteration 마다 plot 하더라도, 해당 모델이 제대로 학습하고 있는지 알기가 모호해진다.
이런 모델이 올바르게 학습하고 있는지 확인하기 위해서는 Dropout 을 제거하고, cost function 이 단조적으로 감소하는지 확인하여 버그가 없는지 체크후, dropout 을 이용해 학습하는 것을 추천한다.