F1 Score
f1 score 는 Recall 과 precision 에 대한 조화 평균 (harmonic mean) 점수다.
F1 Score 는 0.0 ~ 1.0 사이의 값을 가지며 높을수록 좋다.
B) F1 Score 를 사용하는 이유
Recall 과 precision 의 불균형을 해결하기 위해 조화 평균 값인 F1 Score 를 사용한다.
어느 이진 분류 모델이 항상 모든 데이터를 positive 로만 분류하는 모델이라 가정해보자. 이 경우, Recall 은 의 값을 가지겠지만, precision 은 에 가까울 수 있다.
C) 기하학적으로 해석하는 F1 Score
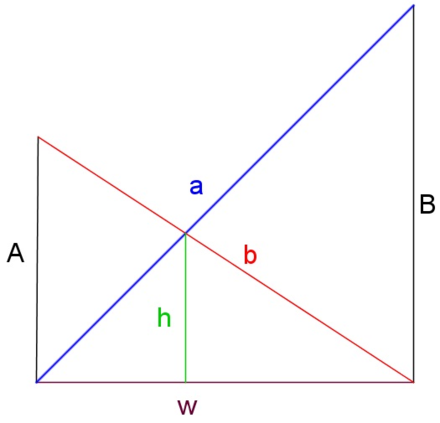
여기서 A 는 Recall 그리고 B 는 precision 이며, h 는 A 와 B 의 harmonic mean 인 F1 Score 이다.
- 만약 A 또는 B 한쪽이 너무 높거나 낮을 경우, h 는 감소한다.
- 반대로, 두 값이 모두 적절히 높을 때, h 는 증가한다.
D) For Multi-class Classification
다중 클래스 classification 문제에서는 각 클래스에 대해서 One-vs-Rest(OvR) F1 score 를 계산하는 것이 중요하다. 즉, 각 class 에 대하여 TP(True Positive), FP, FN 을 계산하여 precision, recall 을 구하고, 최종적으로 F1 Score 를 계산한다.
각 클래스마다 F1 score 를 구하기 보다는 이 score 를 평균내어 하나의 숫자로 표기하는게 전반적인 performance 를 확인하기 더 편하다. 평균을 내는 방식에는 총 세가지 방식이 존재한다.
D.1) (1) Macro Average
가장 단순 방식으로, 모든 클래스 당 F1-score 의 평균을 의미한다.
D.2) (2) Weighted Average
각 class 의 support 값에 따라 F1-score 평균 계산 시 가중치를 적용하는 방식이다. 이는 클래스 불균형에 대한 평가 방식을 좀 더 공정히하기 위해 고안한 방식이다.
D.3) (3) Micro Average
Micro 평균 방식은 F1-score 를 계산하기 위한 TP, FN, FP 를 각각 class 마다 합산하고, 합산된 결과를 활용하여 F1-score 를 계산하는 방식이다.
결과적으로 micro 평균 방식은 전체 관측 데이터 중 올바르게 분류된 관측 데이터의 비율을 계산하는 것과 동일하다. 즉, 전반적인 accuracy 를 고려하는 것과 같다.
추가적으로 micro-recall 또는 micro-precision 방식도 micro F1-score 와 동일한 값을 가지게 된다.
간단히 정리하면 이렇다.
D.4) 어느 방식이 가장 좋은가?
만약 분류하려는 class 가 모두 중요하고, 데이터셋의 클래스가 불균형하다면 macro average 가 무난한 선택이 될 것이다.
만약 분류하려는 class 의 중요도가 서로 다르고, 데이터셋의 클래스가 불균형하다면 weighted 방식이 좋다.
마지막으로 데이터셋의 클래스가 밸런스가 맞고 전반적인 performance 를 쉽게 이해할 수 있는 metric 을 고려한다면 micro average 방식이 좋다.
E) Fbeta-Measure
recall 또는 precision 에 더 가중치를 주는 방식. false positive 또는 false negative 에 더 많은 가중치를 주기 위해 사용한다.
위 식의 는 recall 에 주는 가중치를 의미한다. 낮을수록 recall 에 가중치를 낮게 준다는 의미.
- F0.5-Measure (beta=0.5): precision > recall
- F1-Measure (beta=1.0): precision = recall (F1-score)
- F2-Measure (beta=2.0): precision < recall