Cost Function
2. Cost Function 을 최소화 한다는 것의 직관적 이해
linear regression 의 Cost Function
- 가설 의 정확도를 측정하기 위해 사용하는 함수
- 형식으로 번째 training 데이터를 표현
- 은 training 데이터의 개수 (# of training examples)
- 수식을 로 나누는 것은 gradient descent 계산 시, 미분 term 을 구하는데 편리해지기 때문
-
The mean is halved as a convenience for the computation of the gradient descent, as the derivative term of the square function will cancel out the term.
-
를 간소화해서 을 이라 하자. 즉, 을 최소화하는 문제로 바꿔보자:
아래의 왼쪽 그림은 예측 모델 그리고 오른쪽은 비용 함수 이다.
-
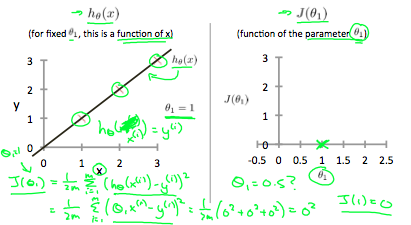
- 학습 데이터는 $\theta_1=1$일 때의 모델 $h$와 정확하게 직선상에 일치하고, 오른쪽 그림에 $(\theta_1,J(\theta_1))$은 $(1,0)$으로 표기된다. -
이후 계속 를 그려보면 다음과 같다.
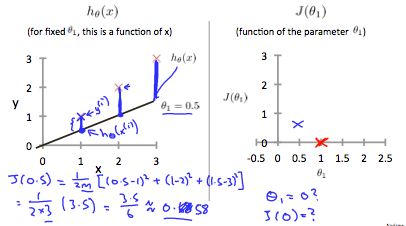
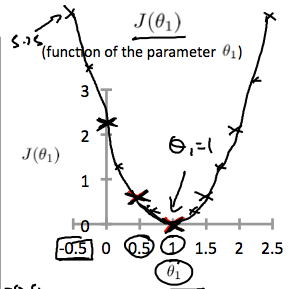
- 비용 함수를 최소화 하는 것이 목적이므로, 을 선택하고, 이를 global minimum 이라 부른다.
-
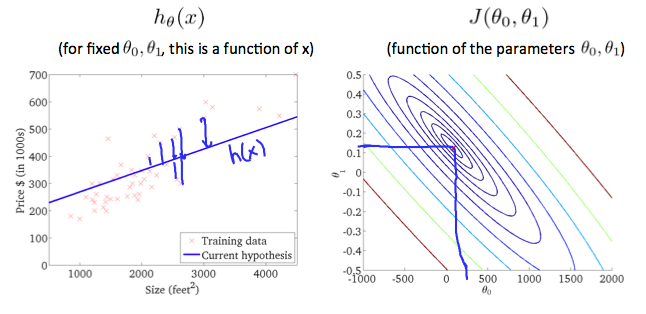
이제 이었던, 를 다시 사용해보자.
- 더 이상 은 일반적인 선 그래프로 표현하기 힘들다.
- 두 개의 features() 를 사용하는 경우, 등고선 (contour plot) 을 사용한다.
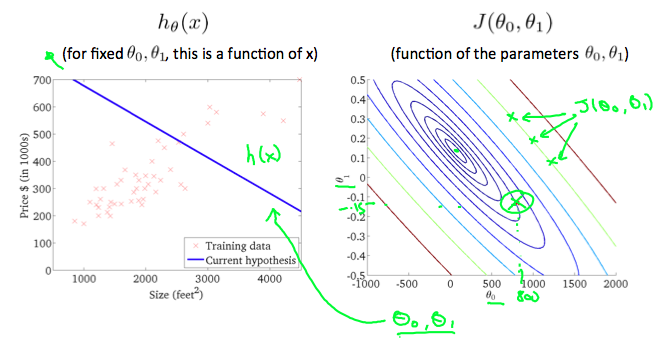
모델 가 학습 데이터에 더욱 적합해질수록, 값은 등고선의 중심에 다가간다.
3. L1 Loss and L2 Loss
- 실제 값 와 예측값 사이의 관계
- L1 Loss
-
-
L2 Loss 는 outlier 의 변화에 민감하다. 반면 L1 Loss 는 outlier 에 대해서 상대적으로 안정된 값을 보여준다. 아마 그 이유는 차이를 제곱 (square) 하기 때문이 아닐까 생각해본다.
4. Cost Vs Loss Function?
- Loss function 은 단일 training example 에 대한 prediction 과 ground truth 값의 차이를 의미한다.
- Cost function 은 모든 training examples 들에 대한 loss function 의 평균 값을 의미한다.