Probabilistic Latent Semantic Indexing
단어와 문서 사이를 잇는, 우리 눈에 보이지 않는 잠재구조가 있다는 가정 하에, 단어와 문서 출현 확률을 모델링한 확률모형
pLSI(Probabilistic Latent Semantic Indexing)는 LSA를 확률 모델로 발전시킨 형태입니다.
핵심 아이디어: 문서가 여러 주제의 혼합으로 구성되어 있고, 각 단어는 특정 주제로부터 확률적으로 생성된다고 가정합니다.[1][3]
작동 방식
- 각 문서를 특정 주제(Topic) 분포로, 각 주제를 특정 단어(Word) 분포로 모델링합니다. 즉, P(문서|주제)와 P(단어|주제)의 확률 분포를 학습합니다.[1] 장점: LSA와 달리 확률 모델이기 때문에 결과를 해석하기가 더 직관적입니다.
단점:
- 학습 데이터에만 최적화되는 경향(Overfitting)이 있습니다.
- 새로운 문서에 대한 주제 분포를 생성하는 명확한 방법을 제공하지 못합니다
A.1) 예시 (및 그림)
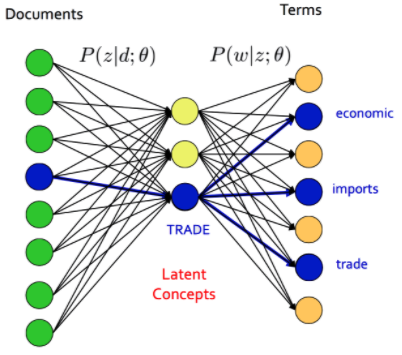
Notation
- 위 그림에서 는 Document 를, 는 topic(Latent Concepts) 을, 는 특정 단어를 의미한다.
- 는 문서에서 특정 topic 이 나타날 확률이고, 는 특정 topic 에서 특정 단어가 나타날 확률이다. Documents 에서 위에서 네번째 문서는 TRADE 라는 특정 토픽으로 나타낼 수 있고 economic, imports, trade 라는 Terms 들을 도출하게 된다.
B) pLSA 의 학습
B.1) 간략한 과정

- pLSA 는 위 그림의 (b) 의 방향으로 학습한다.
- (a): 우선 문서 () 를 뽑습니다. 그 다음 이 문서의 주제 () 를 뽑습니다. 마지막으로 해당 주제별로 단어 () 를 뽑습니다.
- 사람이 글 쓸 때도 글을 쓰기로 마음을 먹고 나서 주제, 단어를 차례대로 결정하기 때문에 직관적으로 이해가 가능합니다.
- (b): 주제 () 를 뽑은 뒤 이 주제에 해당하는 문서 () 와 단어 () 를 뽑는 방식입니다.
- (a): 우선 문서 () 를 뽑습니다. 그 다음 이 문서의 주제 () 를 뽑습니다. 마지막으로 해당 주제별로 단어 () 를 뽑습니다.
- pLSA 의 loss function: non-convex optimization problem
- pLSA 는 개 단어, 개 문서, 개 주제 (토픽) 에 대해, 다음 likelihood function 을 최대화하는 걸 목표로 함
- 위 식에서 는 번째 문서에 번째 단어가 등장한 횟수를 나타냄
- 는 개 주제 (토픽) 에 대해 summation 형태로 되어 있는데, 이것은 같은 단어라 하더라도 여러 토픽에 쓰일 수 있기 때문임
- 예컨대 정부 (government) 같은 흔한 단어는 정치, 경제, 외교/국방 등 다양한 주제에 등장할 수 있습니다.
- log-likelihood 로 수식을 좀 더 간단히 만들 수 있음
C) 방식
EM 알고리즘으로 학습한다.
- E-step: Posterior probability of latent variables (concepts)
-
- : 문서 에서 term 의 출현이 topic(concept) 으로 설명될 수 있는 확률
-
- M-step: Parameter estimation based on “completed” statistics
-
- : concept 가 term 에 얼마나 많이 연관되어 있는지?
- : 문서 에서 term 의 발생 횟수
-
- : concept 가 document 에 얼마나 많이 연관되어 있는지?
-
- : concept 가 얼마나 prevalent 한지?
-
C.1) E-step: 잠재 변수 (개념) 의 사후 확률 계산
: 문서 에서 단어 의 등장이 토픽 (개념) 에 의해 설명될 확률을 의미합니다.
C.2) M-step: “완성된” 통계에 기반한 파라미터 추정
-
- : 개념 가 단어 와 얼마나 많이 연관되어 있는지를 나타냅니다.
- : 문서 에서 단어 가 등장한 횟수입니다.
-
- : 개념 가 문서 와 얼마나 많이 연관되어 있는지를 나타냅니다.
-
- : 개념 가 전체에서 얼마나 많이 출현하는지 (전반적인 빈도) 를 나타냅니다.
Probabilistic
D) Comparison to other Topic Modeling Methods
pLSA 는 LSA 와 다른 기법이다. 하지만 비슷한 점이 있다.
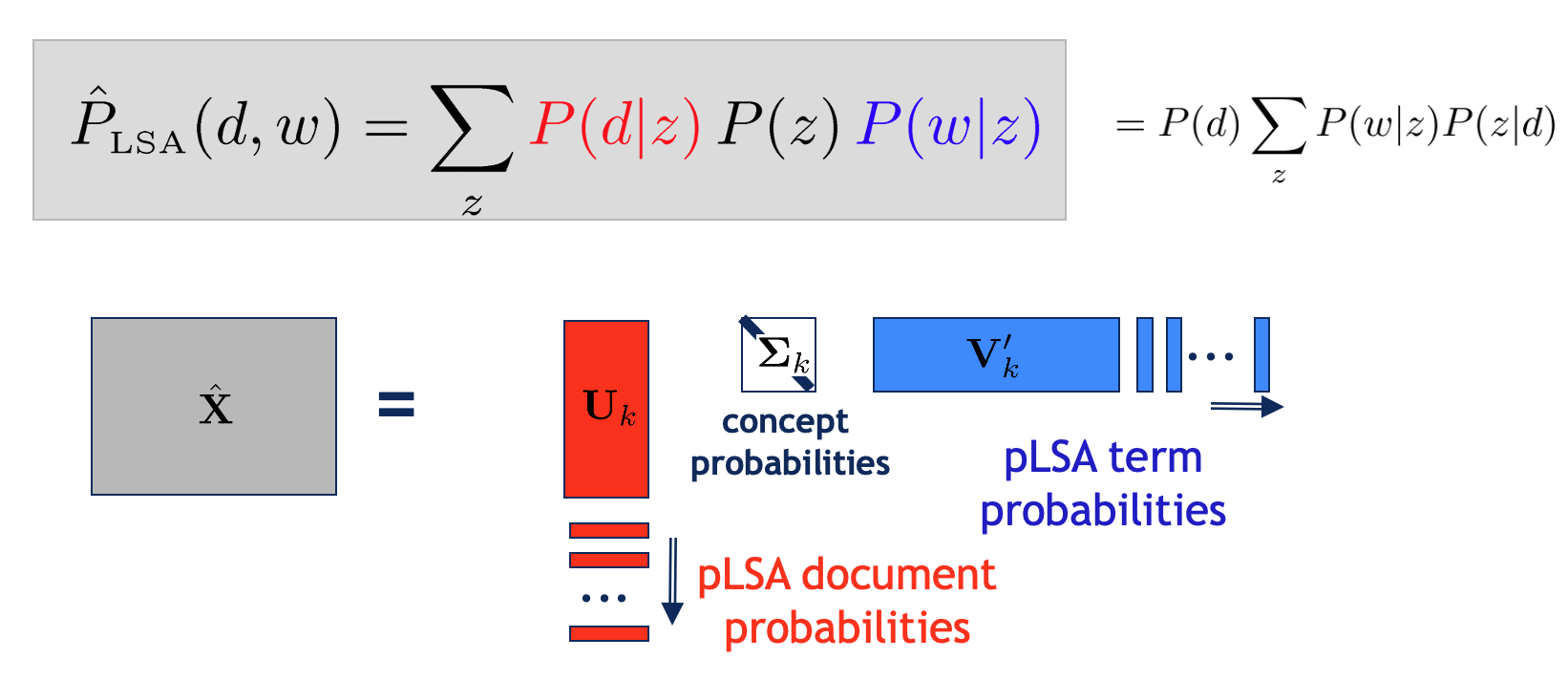
- 비슷한 점
- LSA 결과물인 행렬 의 열벡터는 각각 해당 토픽에 대한 문서들의 분포 정보를 나타냅니다. 이는 pLSA 의 에 대응합니다.
- 행렬 의 행벡터는 각각 해당 토픽에 대한 단어들의 분포 정보를 나타냅니다. 이는 pLSA 의 에 대응합니다.
- 의 대각성분은 토픽 각각이 전체 말뭉치 내에서 얼마나 중요한지 나타내는 가중치가 됩니다. 이는 pLSA 의 에 대응합니다.
- 차이점
- pLSA 의 결과물은 확률이기 때문에 각 요소값이 모두 0 이상, 전체 합이 1 이 되지만, LSA 는 이런 조건을 만족하지 않음
- Latent Dirichlet Allocation 와 비교
E) 장점 및 단점
- 장점: 확률 기반이므로 latent feature 에 의미 부여가 가능함
- 단점
- Document 가 많아질수록 overfitting 됨
- overfitting: training 시 사용하지 않은 문서의 단어를 통해 likelihood 를 계산 시 낮게 나옴
- 새로운 document 에 대해서 topic modeling 정확도가 낮음
- Document 가 많아질수록 overfitting 됨
F) Related
- Latent Semantic Analysis
- Latent Dirichlet Allocation (overfitting 해결 목적)
- soft-clustering
- topic modeling
- Tutorial on Probablistic Latent Semantic Analysis
G) References
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/05/25/plsa/
- https://en.wikipedia.org/wiki/Probabilistic_latent_semantic_analysis
- https://arxiv.org/pdf/1212.3900.pdf (Probabilistic Latent Semantic Analysis)
H) Vs. ALS
pLSI는 사용자와 아이템의 상호작용(interaction)을 확률 모델로 해석하는 접근법이 됩니다. 즉, ‘사용자-아이템’ 쌍이 나타날 확률 P(user, item)을 여러 ‘잠재 요인(z)‘을 통해 분해하는 것입니다.
이러한 접근은 사용자의 취향과 아이템의 특성을 확률 분포로 모델링하여 추천을 생성할 수 있다는 점에서 매우 흥미롭습니다.
H.1) 하지만 왜 ALS가 더 표준적일까요? (핵심적인 차이점)
이론적으로는 가능하지만, 실제 추천 시스템에서는 ALS와 같은 행렬 분해 기법이 훨씬 널리 쓰이는 데에는 몇 가지 중요한 이유가 있습니다.
1. 모델링 대상의 차이: ‘확률’ vs ‘평점 값’
- pLSI: 단어의 등장 **빈도(count)**를 기반으로 ‘단어가 문서에 등장할 확률’을 모델링합니다. User-Item 행렬에 적용하면, 사용자가 아이템을 클릭하거나 구매한 **횟수(implicit feedback)**를 기반으로 ‘상호작용이 일어날 확률’을 예측하게 됩니다.
- ALS 기반 MF: 사용자가 아이템에 매긴 평점(explicit feedback) 자체를 예측하는 것을 주 목표로 합니다. 즉, 확률이 아닌 **예측 평점 값(e.g., 4.5점)**을 직접 모델링합니다. 이는 “이 사용자가 아직 보지 않은 이 영화에 몇 점을 줄까?”라는 질문에 더 직접적인 답을 줍니다.
2. 데이터 처리 방식의 차이: ‘0’의 의미
- pLSI: 문서-단어 행렬(DTM)에서 값이 0이라는 것은 ‘그 문서에 그 단어가 한 번도 등장하지 않았다’는 명확한 사실입니다.
- 추천 시스템: User-Item 행렬에서 값이 비어있다는 것은 ‘사용자가 아이템을 싫어해서(1점) 안 본 것’이 아니라, ‘아직 접하지 못했을(unknown)’ 가능성이 훨씬 큽니다. ALS와 같은 알고리즘은 이 ‘비어있는 값(missing value)‘을 예측하는 데 특화되어 있지만, pLSI는 이 값을 단순히 ‘상호작용 횟수가 0’으로 처리하기 때문에 사용자의 선호를 왜곡할 수 있습니다.
3. 목적 함수의 차이
- pLSI: 로그 우도(Log-Likelihood)를 최적화하여 관측된 데이터가 모델로부터 생성될 확률을 최대로 만듭니다. (확률 모델의 관점)
- ALS: 실제 평점과 예측 평점 간의 오차(e.g., RMSE - Root Mean Square Error)를 최소화하는 것을 목표로 합니다. (오차 최소화의 관점)
H.2) 면접 답변 Tip
면접관이 이렇게 심화 질문을 한다면 다음과 같이 답변하면 좋습니다.
“네, 예리한 지적이십니다. pLSI의 행렬 분해 방식은 개념적으로 User-Item 행렬에도 적용할 수 있습니다. 문서를 사용자로, 단어를 아이템으로 치환하여 사용자의 취향과 아이템의 특성을 확률적으로 모델링하는 접근이 가능합니다.
하지만 근본적인 차이점이 있습니다. pLSI는 주로 상호작용의 확률을 모델링하는 반면, ALS와 같은 전통적인 협업 필터링은 평점 값 자체를 예측하는 데 더 중점을 둡니다. 또한, 추천 시스템의 User-Item 행렬에서 ‘비어 있는 값’은 ‘아직 모르는 값’을 의미하는데, pLSI는 이를 ‘상호작용이 없는 것’으로 해석할 수 있어 정보의 왜곡이 발생할 수 있습니다.
이러한 이유로, 평점 예측과 같은 추천 시스템의 고유한 문제를 해결하기 위해 오차를 직접 최소화하고 비어있는 값을 처리하는 데 특화된 ALS와 같은 행렬 분해 기법이 더 표준적으로 사용됩니다.”