paper link: https://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
Abstract
LDA 는 이산 데이터 콜렉션을 위한 generative probabilistic model 이다.
3 단계 계층적 베이지안 모델이며, 콜렉션의 각 아이템들이 토픽 집합들의 유한한 mixture 로 모델링 된다. the topic probabilities provide an explicit representation of a document.
B) Prevent overfitting
DA는 디리클레 사전 분포(Dirichlet Prior) 를 모델에 추가하여 과적합을 방지합니다. 이 사전 분포를 조절하는 하이퍼파라미터가 바로 알파(α) 와 베타(β) 입니다. 이 파라미터들이 일종의 정규화(Regularization) 역할을 수행합니다.
B.1.1) pLSI가 과적합되는 이유
pLSI는 훈련 데이터셋(Training Corpus)에만 최적화되는 경향이 있습니다. 그 이유는 다음과 같습니다.
-
사전 지식의 부재: pLSI는 오직 주어진 문서-단어 행렬(DTM)의 확률 분포만을 학습합니다. 토픽 분포나 단어 분포가 어떠한 형태를 가질 것이라는 사전 가정이 없습니다.
-
문서별 파라미터: pLSI는 훈련 데이터에 있는 각각의 문서마다 해당하는 토픽 분포 파라미터를 학습합니다. 이는 훈련 문서가 늘어날수록 모델의 파라미터 수가 계속 증가한다는 의미이며, 과적합에 매우 취약한 구조입니다. 훈련 데이터에 등장한 특정 문서의 토픽 조합만 기억하게 될 가능성이 높습니다.
B.1.2) LDA가 디리클레 분포로 과적합을 방지하는 방법
LDA는 pLSI의 확률 모델에 베이즈 통계학 개념을 더한 것입니다. 즉, 관찰된 데이터(문서)를 설명하기 이전에, 파라미터(토픽 분포, 단어 분포) 자체가 특정 확률 분포를 따를 것이라는 사전 가정을 추가합니다. 이 사전 가정에 사용되는 것이 디리클레 분포이며, 이 분포의 형태를 조절하는 것이 하이퍼파라미터 알파(α) 와 베타(β) 입니다.
B.1.2.1) 알파(α): 문서-토픽 분포 조절 파라미터
-
역할: 문서가 생성될 때, 문서가 가질 토픽 분포(예: 이 문서는 토픽1 70%, 토픽2 20%, 토픽3 10%)가 디리클레 분포를 따른다고 가정합니다. 알파는 이 분포의 형태를 결정합니다.
-
α값이 높을 경우 (High Alpha):
- 문서의 토픽 분포가 여러 토픽에 걸쳐 고르게 나타납니다 (Dense).
- 문서들은 다양한 주제를 조금씩 포함하는 경향이 생깁니다.
- 정규화 효과가 커져, 모델이 특정 소수의 토픽에만 의존하는 것을 방지합니다.
-
α값이 낮을 경우 (Low Alpha):
- 문서의 토픽 분포가 소수의 특정 토픽에만 집중됩니다 (Sparse).
- 문서는 몇 개의 핵심 주제로만 구성되는 경향이 생깁니다.
과적합 방지 원리: 알파는 “한 문서가 극단적으로 하나의 토픽으로만 구성되지는 않았을 거야”라는 부드러운 제약(smoothing)을 가합니다. pLSI처럼 훈련 데이터에 맞춰 특정 문서의 토픽 분포를 극단적으로 학습하는 것을 막아 일반화 성능을 높입니다.
B.1.2.2) 베타(β): 토픽-단어 분포 조절 파라미터
-
역할: 각 토픽이 생성될 때, 해당 토픽이 가질 단어 분포(예: 토픽1은 ‘축구’ 50%, ‘선수’ 30%…) 역시 디리클레 분포를 따른다고 가정합니다. 베타는 이 분포의 형태를 결정합니다.
-
β값이 높을 경우 (High Beta):
- 토픽의 단어 분포가 여러 단어에 걸쳐 고르게 나타납니다.
- 토픽들이 서로 비슷한 단어들을 공유하게 되어, 토픽 간의 경계가 모호해질 수 있습니다.
-
β값이 낮을 경우 (Low Beta):
-
토픽의 단어 분포가 소수의 핵심 단어에만 집중됩니다.
-
토픽별로 사용되는 단어가 명확히 구분되어, 해석하기 쉬운 토픽이 만들어집니다.
-
과적합 방지 원리: 베타는 “한 토픽이 극단적으로 특정 단어 몇 개로만 이루어지지는 않았을 거야”라는 제약을 가합니다. 이를 통해 훈련 데이터에 특정 단어가 특정 토픽으로만 등장했더라도, 다른 토픽에 등장할 확률을 완전히 0으로 만들지 않습니다. 이는 새로운 문서나 단어 조합에 대한 대응력을 높여줍니다.
B.1.3) pLSI 대비 LDA는 어떤 파라미터로 과적합을 방지하나요?
네, LDA는 **디리클레 사전 분포(Dirichlet Prior)**를 모델에 도입하여 과적합을 방지합니다. 이 사전 분포를 조절하는 하이퍼파라미터인 **알파(α)와 베타(β)**가 정규화(Regularization) 역할을 수행합니다.
- **알파(α)**는 문서별 토픽 분포에 대한 사전 가정입니다. 이 값을 통해 문서가 얼마나 다양한 토픽을 포함할지를 조절하여, 훈련 데이터의 특정 문서에만 과도하게 최적화되는 것을 막습니다.
- **베타(β)**는 토픽별 단어 분포에 대한 사전 가정입니다. 이 값을 통해 토픽이 얼마나 다양한 단어를 포함할지를 조절하여, 토픽이 소수의 단어에만 집착하는 것을 막고 일반화 성능을 높입니다.
이처럼 LDA는 pLSI와 달리 파라미터 자체에 확률적인 제약을 가함으로써, 훈련 데이터에만 존재하는 분포가 아닌 더 일반적인 분포를 학습하도록 유도하여 과적합을 효과적으로 방지합니다.
B.2) LDA 모델 Architecture
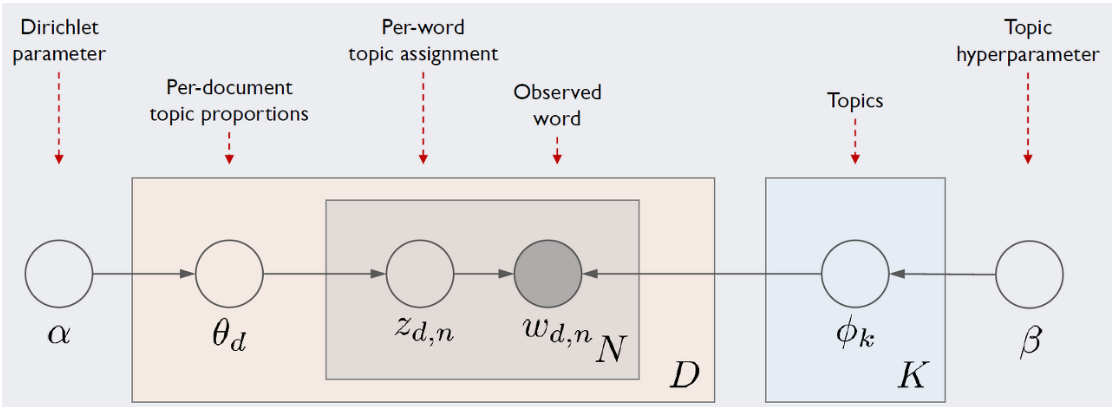
- 번째 문서에 등장한 번째 단어
- 는 topic 에 대한 Dirichlet distribution 의 prior
- Alpha parameter represents document-topic density—with a higher alpha, documents are assumed to be made up of more topics and result in more specific topic distribution per document.
- Beta parameter represents topic-word density— with high beta, topics are assumed to made of up most of the words and result in a more specific word distribution per topic.
- 는 번째 문서가 가진 topic 비중 (weight) 을 나타내는 벡터
equation
- Probabilistic latent Semantic Indexing 과 차이점
- 차이점
- pLSI: 모든 문서 주제의 분포 () 가 정해져 있고, 이를 찾아야 함
- LDA: 문서의 주제 분포 () 를 결정해주는 parameter 가 있고, sampling 을 통해 주제 분포를 얻음
- LDA 가 pLSI 보다는 새로운 documents 에 대해서 쉽게 generalize 할 수 있어서 강점이 있다.
- 차이점
- Dirichlet distribution 의 모수 () 를 학습
- PLSI 에 비해 모수 개수가 줄어들기 때문에 overfitting 발생 확률이 감소한다.
- Bayesian inference 을 활용해서 잠재 모수의 분포를 구해야하는데, 이때 posterior distribution 이 계산하기 불가능에 가깝다.
- 그래서 variational inference 이나 Sampling method 를 통해 이러한 문제를 해결한다.
C) Related
LDA, , [[topic modeling, Aurochs LDA, JMLR 03, #TF-IDF