Kafka Cluster 는 여러 대의 카프카 서버가 모여 구성된 클러스터입니다.
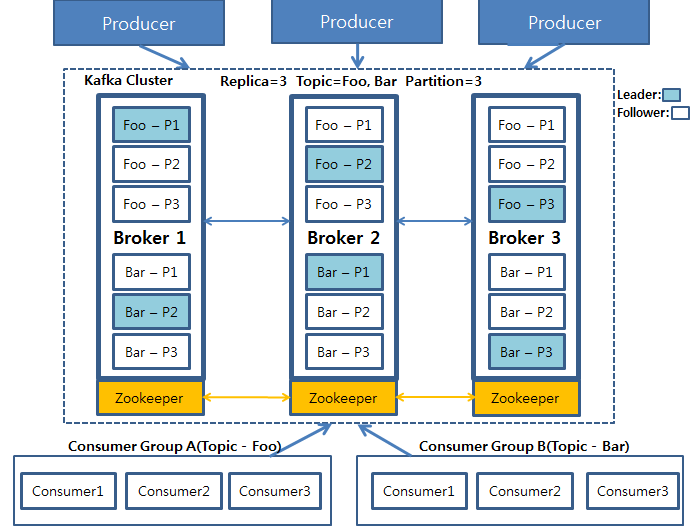 이 이미지는 카프카 전체 프로세스의 구조를 보여줍니다. Producer가 데이터를 Kafka Cluster에 적재하고, 저장된 데이터는 각각 consumer group A와 B가 자신이 처리해야 할 Topic Foo와 Bar에서 가져가는 과정을 나타냅니다.
이 이미지는 카프카 전체 프로세스의 구조를 보여줍니다. Producer가 데이터를 Kafka Cluster에 적재하고, 저장된 데이터는 각각 consumer group A와 B가 자신이 처리해야 할 Topic Foo와 Bar에서 가져가는 과정을 나타냅니다.
Kafka Cluster를 구성하는 주요 요소는 다음과 같습니다.
- 브로커(Broker): 카프카 서버를 의미합니다.
- 주키퍼(Zookeeper): 분산 환경에서 클러스터를 코디네이팅하는 시스템입니다.
- 주키퍼는 여러 개의 카프카 브로커를 하나의 클러스터로 관리하며, 리더(Leader)를 선출하는 역할도 담당합니다.
- 리더(Leader)와 팔로워(Follower): 데이터 복구를 위한 계층적 구조입니다.
- 각 파티션마다 여러 개의 복제본 중 하나가 리더로 선정되며, 나머지는 팔로워가 됩니다.
- 리더는 모든 읽기 및 쓰기 작업을 담당하고, 팔로워들은 리더의 데이터를 그대로 복제하는 역할을 합니다.