Kafka
대용량 실시간 메시지 처리를 위한 프레임워크
B) Producer & Consumer
Kafka 는 Producer 와 Consumer 가 데이터를 주고 받기 위한 중간 다리 역할을 한다.
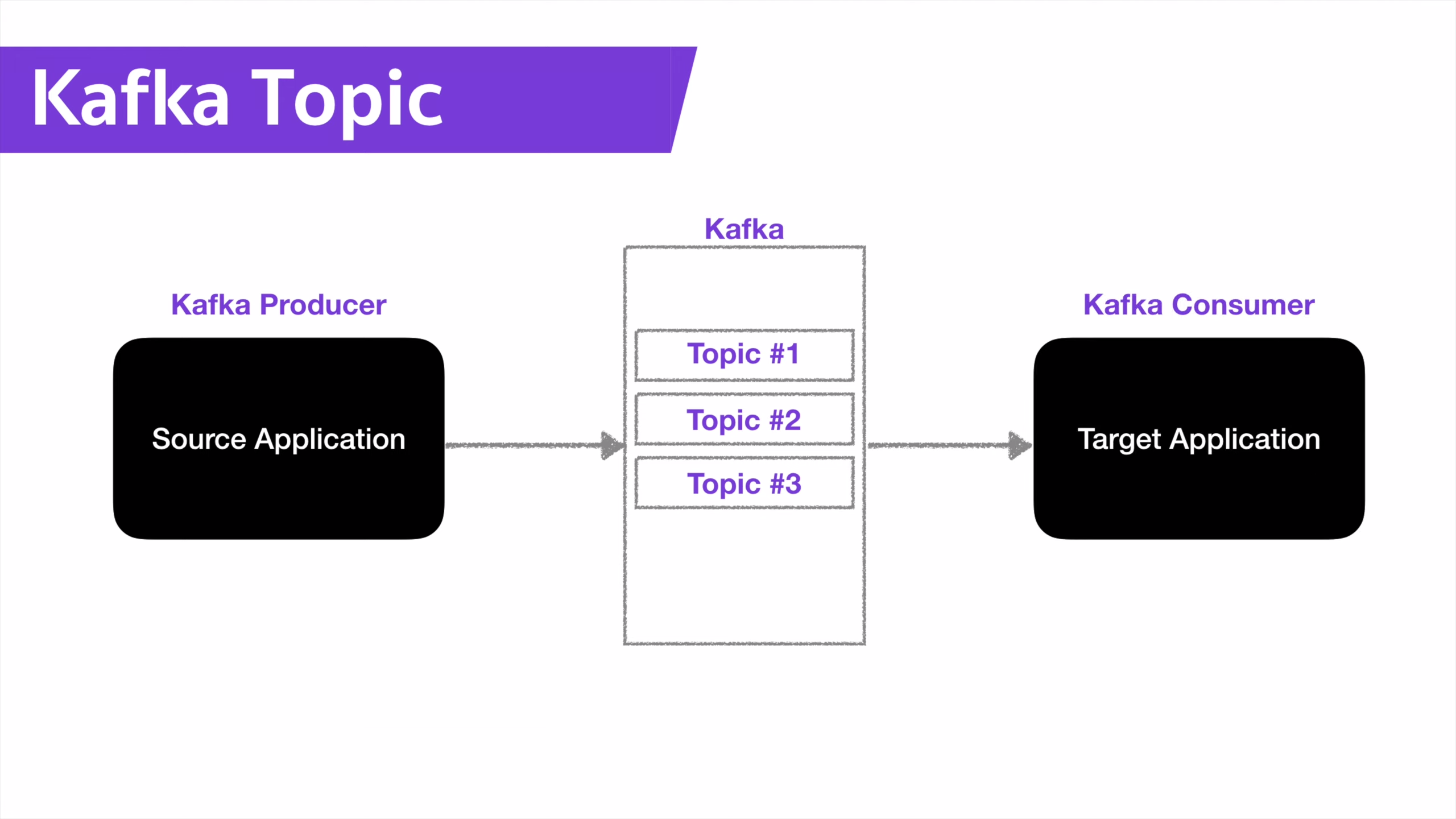
- Producer: 데이터를 전송하는 역할
- 전송하는 데이터의 종류는 제한이 없으며, 다양한 데이터 타입이 가능하다.
- Kafka consumer:: 데이터를 받아서 처리하는 역할
- Topic & Partition

- Topic
- Producer 는 데이터를 Topic(kafka) 이라는 곳에 데이터를 전송한다.
- 각 토픽은 고유한 이름을 가지는데, 어떤 데이터를 처리하는지 쉽게 파악할 수 있도록 이름을 설정하는 것이 중요하다.
- Partition
- 하나의 Topic(kafka) 은 여러개의 파티션으로 구성될 수 있으며, 각 파티션은 인덱스처럼 0 부터 시작한다.
- 여러개의 파티션으로 나누는 이유는 데이터를 분산처리 하기 위해서 이다.
- 파티션을 늘리는 것은 분산처리에 효율적이나, 다시 그 수를 줄일 수 없기에 매우 조심해야 한다.
- 파티션에는 제한 시간과 용량이 존재하는데, 일정 시간이 지난 데이터나 파티션 내 용량을 초과하면 데이터를 삭제하여 파티션의 밸런스를 조절한다.
- 예시
- Interaction between Partition and (Producer or Consumer)
- 파티션이 Producer 와 Consumer 랑 어떻게 파티션과 상호작용 하는지 알아보자.
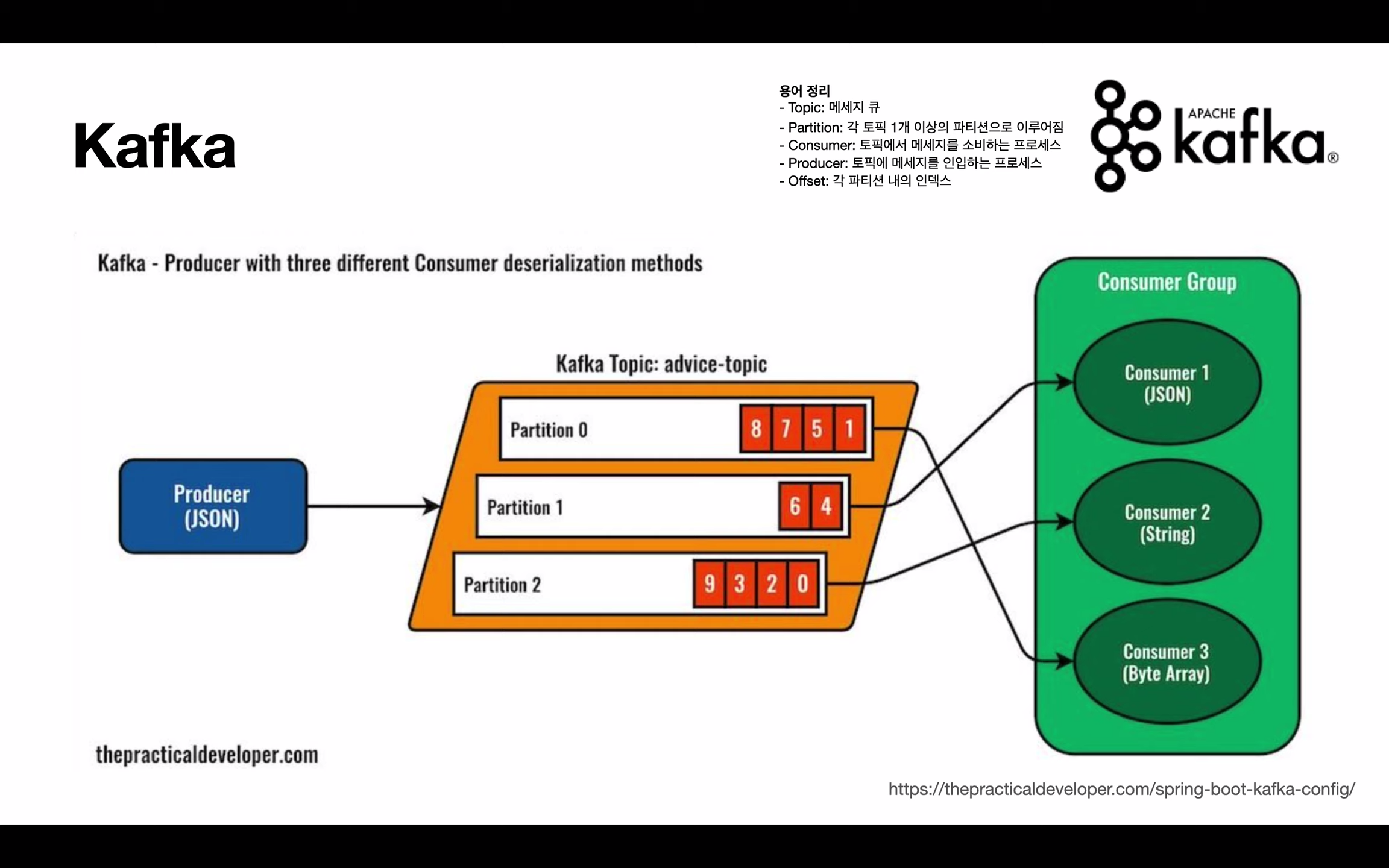
- 파티션이 Producer 와 Consumer 랑 어떻게 파티션과 상호작용 하는지 알아보자.
B.1) Producer
- Producer 가 데이터를 전송하면 파티션은 Queue 와 비슷한 역할을 수행하여, 데이터가 끝에서부터 쌓이게 된다.
- 이렇게 쌓인 데이터도 파티션 내부에서 순서를 정하게 되는데, 그 순서를 offset 이라고 한다.
- 이 offset 은 데이터가 전송된 순서에 따라 파티션과 비슷하게 0 부터 시작한다.
- 예시
- 0, 1, 2, 3 이라는 데이터를 전송했다면, 파티션에는
[3, 2, 1, 0]의 형태로 끝에서부터 데이터가 쌓인다. - 즉, 0 에 대한 offset 은 0, 1 에 대한 offset 은 1 … 이런식으로 offset 이 설정된다.
- 0, 1, 2, 3 이라는 데이터를 전송했다면, 파티션에는
- 만약, 파티션이 여러개라면, 일반적으로 round-robin 형식으로 데이터를 보내게 된다.
- 그렇지 않고, 파티션을 명시했다면, 그 파티션에만 데이터가 전송되게 된다.
B.2) Consumer
- 특정 Topic 에 접근한 consumer 는 데이터를 가장 오래된 순서대로 가져가게 된다.
- 하지만 동일한 파티션 내에서만 그 순서가 보장된다.
- 모든 데이터를 다 읽었다면, producer 가 추가적으로 데이터를 전송할 때 까지 기다리게 된다.
- 일반적으로 제한 시간을 정해서, 그 시간을 초과하면 consumer 동작을 중지시킬 수 있다.
- 가장 중요한 점은 consumer 가 데이터를 읽어들여도, 다른 consumer 가 데이터를 읽을 수 있도록, 파티션에 존재하는 데이터는 사라지지 않는다는 점이다.
C) Kafka Terms
카프카에 관련된 다양한 용어들을 설명하기 위한 곳
Kafka Cluster
- TOROS 에서 Kafka
- TOROS 도 카프카를 사용한다.
- 그래서 추천시스템으로부터 카프카에 전송되는 데이터를 알 수 있는데, 그럴려면 일단 원하는 데이터가 들어있는 토픽을 알아야 한다.
- 메시지가 binary 데이터 형식을 띄므로, 추천시스템에서 전송되는 데이터 형식은 직접적인 데이터보다는 meta data 형식의 값을 넣는다. (그렇다면 실제 데이터는 어디에 ? → HBase 에 적재)