HNSW
Hierarchical Navigable Small World (HNSW) graphs are among the top-performing indexes for vector similarity search (Approximate Nearest Neighbor).
HNSW는 현재 가장 널리 쓰이는 ANN 알고리즘 중 하나로, 그래프 기반 알고리즘입니다.
-
동작 원리 (고속도로와 국도 비유):
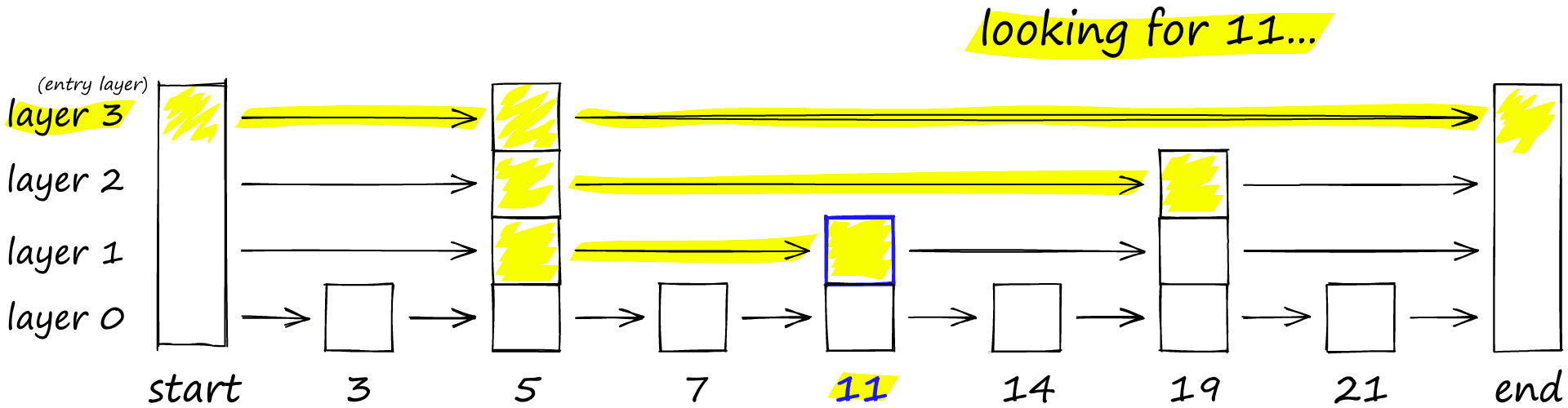
- 계층적 그래프 생성: 데이터를 여러 개의 층(Layer)으로 구성된 그래프로 만듭니다. 맨 위층(Layer)은 가장 성긴(sparse) 그래프(고속도로), 아래로 갈수록 촘촘한(dense) 그래프(국도, 골목길)가 됩니다.
- 탐색 과정:
- 항상 최상위 계층의 **진입점(Entry Point)**에서 탐색을 시작합니다.
- 현재 층에서 타겟과 가장 가까운 노드를 탐욕적으로(greedily) 찾아갑니다. (고속도로로 목적지 근처 IC까지 이동)
- 더 이상 가까워질 수 없으면, 한 단계 아래 층으로 내려가 다시 탐색을 시작합니다. (IC에서 나와 국도를 탐색)
- 이 과정을 가장 아래층(Layer 0)까지 반복하여 최종 결과를 찾습니다.
-
장점:
- 성능: 검색 속도가 매우 빠르면서도 재현율(Recall, 실제 정답을 얼마나 잘 맞추는가)이 높아 현재 가장 성능이 좋은 알고리즘 중 하나로 꼽힙니다.
- 튜닝 용이성:
M(이웃 수),efConstruction(그래프 생성 시 탐색 범위),efSearch(검색 시 탐색 범위) 등의 파라미터로 속도와 정확도를 조절하기 쉽습니다.
-
단점:
- 메모리 사용량: 그래프 구조 전체를 메모리에 저장해야 하므로 다른 알고리즘에 비해 메모리 사용량이 있습니다.
- 인덱싱 시간: 데이터를 추가하거나 삭제할 때 그래프 구조를 변경해야 해서 상대적으로 시간이 더 걸릴 수 있습니다.
B) Probability Skip List
Skip list는 정렬된 배열처럼 빠른 검색이 가능하면서도, 링크드 리스트 구조를 사용하여 새로운 원소를 쉽고 빠르게 삽입할 수 있다는 장점이 있습니다.
Skip list는 여러 층의 링크드 리스트를 쌓아서 구성됩니다. 최상위 레이어에서는 많은 노드(또는 정점)를 한 번에 ‘건너뛰기(skip)’ 할 수 있는 링크들이 존재합니다. 아래쪽 레이어로 내려갈수록, 각 링크가 건너뛸 수 있는 노드의 수()가 점차 줄어듭니다.
검색 과정에서는, 가장 위 레이어에서 시작하여 오른쪽(아래 그림 참고)으로 이동하며 원하는 키 값을 탐색합니다. 만약 현재 노드의 키 값이 우리가 찾고자 하는 키보다 크면(), 목표값을 초과한 것이므로 한 단계 아래 레벨로 이동하여 이전 노드에서 다시 탐색을 이어갑니다.
C) N2: mmap 기능
mmap은 **메모리 맵 파일(Memory-Mapped File)**의 약자입니다. 디스크에 있는 파일의 내용을 메모리에 전부 로딩하는 것이 아니라, 파일의 특정 영역을 프로세스의 가상 메모리 주소 공간에 직접 매핑(mapping)하는 운영체제(OS) 기능 입니다.
핵심 이점:
-
RAM 용량을 초과하는 인덱스 사용 가능:
- 문제점: ANN 인덱스는 데이터가 많아질수록 크기가 GB 단위를 넘어 수백 GB에 달할 수 있습니다. 이 전체를 물리적인 RAM에 올리는 것은 비용이 매우 비싸거나 불가능합니다.
- mmap 해결책: mmap을 사용하면 인덱스 파일이 디스크(주로 SSD)에 저장된 상태에서, 마치 메모리에 있는 것처럼 접근할 수 있습니다. 실제로는 OS가 필요한 부분(페이지 단위)만 RAM으로 올려주고, 필요 없는 부분은 내리는 방식으로 동작합니다. 덕분에 16GB RAM을 가진 서버에서도 100GB짜리 인덱스를 사용할 수 있게 됩니다.
-
빠른 초기 로딩 속도:
- 일반적인 방식: mmap 없이 인덱스를 사용하려면, 애플리케이션 시작 시 파일 전체를 읽어 RAM에 복사하는 과정이 필요합니다. 수십 GB 파일이라면 이 로딩에만 수 분이 소요될 수 있습니다.
- mmap 방식: mmap은 파일을 메모리에 매핑만 할 뿐, 실제로 데이터를 읽어오지는 않습니다. 매핑 자체는 거의 즉시 완료됩니다. 데이터는 실제 접근이 일어나는 순간(예: 첫 검색 요청)에 OS에 의해 디스크에서 RAM으로 로드(페이지 폴트 발생)됩니다. 따라서 서비스 시작 속도가 매우 빠릅니다.
-
메모리 절약 (프로세스 간 공유):
- 핵심 원리: 이것이 질문의 핵심인 ‘메모리 절약’과 직결됩니다. OS는 하나의 파일을 여러 프로세스가 mmap으로 열었을 때, 해당 파일의 동일한 부분을 물리 RAM의 ‘단 한 곳’에만 올려놓고 모든 프로세스가 공유하게 합니다.
- 사용 예시: 예를 들어, 하나의 거대한 추천 모델 인덱스를 사용하는 10개의 검색 서버 프로세스가 있다면, mmap 없이는 각 프로세스가 개별적으로 5GB씩, 총 50GB의 RAM을 사용해야 합니다. 하지만 mmap을 사용하면 10개의 프로세스가 물리 RAM에 올라온 5GB를 공유하므로, 실제로는 5GB(+α)의 RAM만 사용하게 됩니다. 이는 엄청난 메모리 효율성 증대를 가져옵니다.
C.1.1.1) 전통적인 방식과의 차이점
mmap을 사용하지 않는다면, 수십 GB 크기의 N2 인덱스 파일을 사용하기 위해 다음과 같은 과정을 거쳐야 합니다.
- 프로그램 시작 시, 인덱스 파일 크기만큼의 거대한 메모리 공간을 RAM에 할당합니다.
- 디스크에서 인덱스 파일을 전부 읽어(read) 할당된 RAM 공간에 복사합니다.
이 방식은 초기 로딩 시간이 매우 길고, 파일 크기만큼의 RAM을 반드시 확보해야 한다는 큰 단점이 있습니다.
C.1.1.2) N2에서 Mmap의 동작 원리 (메모리 절약의 핵심)
N2에서 mmap을 사용하면 위와 같은 비효율이 사라집니다.
-
애플리케이션이 시작되면, N2는 인덱스 파일을 메모리에 매핑만 해둡니다. 이 과정은 파일을 실제로 읽는 것이 아니므로 거의 즉시 완료됩니다. 이때 실제 물리 메모리(RAM) 사용량은 거의 0에 가깝습니다.
-
사용자로부터 검색 요청(query)이 들어와 N2가 벡터 탐색을 시작합니다. 탐색은 그래프의 특정 노드에서 시작하여 이웃 노드로 이동하는 과정의 연속입니다.
-
이때, N2가 그래프의 특정 노드 정보에 접근하려고 합니다. 이 노드 정보는 아직 RAM에 없고 디스크 파일에만 존재합니다.
-
프로세스가 매핑된 메모리 주소에 접근하는 순간, **페이지 폴트(Page Fault)**라는 이벤트가 발생합니다.
-
운영체제는 이 페이지 폴트를 감지하고, 해당 주소에 매핑된 파일의 데이터 조각(이를 ‘페이지’라고 합니다)을 디스크에서 읽어 실제 물리 메모리(RAM)로 가져옵니다.
-
이후 N2는 RAM에 올라온 데이터를 이용하여 탐색을 계속 진행합니다.
결론적으로, 탐색에 필요한 데이터만 ‘필요할 때(on-demand)’ 디스크에서 RAM으로 로드됩니다. 이것이 mmap이 메모리를 획기적으로 절약하는 핵심 원리입니다.
C.1.1.3) 실제 경험과 장점
제가 mmap을 사용하며 체감한 장점은 크게 세 가지입니다.
-
RAM보다 큰 인덱스 사용 가능: 가장 큰 장점입니다. 예를 들어, 서버의 가용 RAM은 32GB인데, N2로 생성한 인덱스 파일 크기는 100GB인 상황에서도 서비스를 운영할 수 있었습니다. 모든 데이터를 메모리에 올릴 필요가 없기 때문입니다.
-
애플리케이션의 빠른 시작: mmap을 사용하면 수십 GB의 인덱스를 로딩하느라 애플리케이션 시작이 몇 분씩 지연되는 현상이 사라집니다. 거의 즉시 서비스가 준비 상태가 되어 배포와 운영이 매우 편리해집니다.
-
프로세스 간 메모리 공유: 웹 서버처럼 여러 워커(worker) 프로세스를 띄우는 환경에서 특히 유용했습니다. mmap으로 매핑된 메모리 영역은 읽기 전용(read-only)으로 사용할 경우, 모든 프로세스가 이 메모리 영역을 공유합니다. 만약 mmap을 쓰지 않았다면, 8개의 워커 프로세스는 각각 100GB의 인덱스를 메모리에 올려 총 800GB의 RAM이 필요했을 것입니다. 하지만 mmap을 통해 단 하나의 인덱스 메모리만 공유하여 RAM 사용량을 크게 줄일 수 있었습니다.
D) Build Process
HNSW 인덱스는 빈 그래프에서 시작해 데이터 포인트를 하나씩 추가하면서 만들어진다. 이 과정에서 Approximate Nearest Neighbor 검색에 필요한 graph quality가 결정되므로, build-time 파라미터인 M과 ef_construction을 먼저 이해하는 것이 중요하다.
- Layer 할당: 새 노드에 무작위 레벨
L을 부여한다. 대부분의 노드는 Layer 0에만 있고, 소수의 노드만 높은 layer에 올라가 고속도로 역할을 한다. - Entry point 탐색: 최상위 layer의 entry point에서 시작해 새 노드와 가까운 노드를 greedy하게 찾아 내려간다.
- 이웃 후보 탐색: 새 노드가 속한 layer부터 Layer 0까지,
ef_construction크기의 후보 리스트를 유지하며 가까운 이웃을 넓게 탐색한다. - 연결과 pruning: 후보 중 가까운
M개를 이웃으로 연결하고, 기존 노드의 연결 수가 너무 커지면 먼 edge를 제거한다. - 하위 layer 반복: 한 layer에서 찾은 가까운 노드를 다음 layer의 entry point로 삼아 Layer 0까지 반복한다.
즉 M은 각 노드가 가질 수 있는 최대 연결 수이고, ef_construction은 새 노드를 넣을 때 얼마나 넓게 후보 이웃을 살펴볼지 결정한다. ef_search는 build 이후 query-time에 조절하는 값이라, 이미 만들어진 그래프 위에서 recall과 latency의 균형을 잡는 역할을 한다.
E) Tuning
m: 그래프 엣지 개수ef_construction: 그래프 빌드 시 선택하는 이웃 노드 개수ef_search: 그래프 검색 시 선택하는 이웃 노드 개수
E.1.1) ef_construction의 중요성: 인덱스 품질의 기반
ef_construction은 HNSW 인덱스를 구축(construction)하는 단계에서 사용되는 가장 중요한 파라미터 중 하나입니다. 그 역할은 다음과 같습니다.
-
그래프의 품질 결정: HNSW는 계층적인 그래프 구조를 만듭니다. 새로운 데이터 포인트를 그래프에 추가할 때, 얼마나 많은 이웃 노드를 탐색하여 최적의 연결을 만들지 결정하는 것이 바로 ef_construction입니다.
-
높은 값의 효과: ef_construction 값을 높게 설정하면, 더 많은 후보 노드들을 꼼꼼하게 살펴보고 더 정확한 이웃을 찾아 연결합니다. 그 결과, 더 튼튼하고 정교한 그래프가 만들어집니다. 이는 최종적으로 **더 높은 검색 정확도(Recall)**로 이어집니다.
-
트레이드오프(Trade-off): 하지만 ef_construction 값을 높이면 그래프를 만드는 데 더 많은 시간과 컴퓨팅 자원이 소요됩니다. 즉, 인덱스 빌드 시간 vs 검색 품질 사이의 트레이드오프 관계에 있습니다.
“ef_construction은 HNSW 인덱스를 생성할 때 그래프의 품질을 결정하는 핵심 파라미터입니다. 이 값을 높이면 인덱싱 시간은 오래 걸리지만, 더 정교한 그래프가 만들어져 향후 검색 시의 정확도(recall)의 상한선을 높여주는 역할을 합니다.” 라고 답변할 수 있습니다.
E.1.2) 함께 고려해야 할 다른 핵심 파라미터들
ef_construction만 단독으로 튜닝하는 경우는 거의 없습니다. HNSW의 성능은 여러 파라미터들이 상호작용하며 결정되기 때문입니다. 면접에서는 아래 파라미터들을 함께 언급하며 전체적인 이해도를 보여주는 것이 좋습니다.
| 파라미터 | 역할 | 트레이드오프 |
| M | 그래프의 밀도 결정: 각 노드가 가질 수 있는 최대 이웃의 수를 정의합니다. | 높이면: 정확도 향상 가능성 ↑, 메모리 사용량 및 인덱스 크기 ↑ |
| ef (또는 ef_search) | 검색 시 탐색 범위 결정: 인덱스 구축 후, 실제 검색(search) 시에 쿼리 지점으로부터 얼마나 넓게 탐색할지를 결정합니다. | 높이면: 검색 정확도 ↑, 검색 속도(latency) ↓ (느려짐) |
E.1.3) 파라미터 간의 관계 및 튜닝 전략
이 세 가지 파라미터의 관계를 이해하는 것이 중요합니다.
-
M과 ef_construction은 ‘건축가’: 이 두 파라미터는 인덱스를 만들 때 한 번 결정되며, 검색 품질의 잠재력을 결정합니다. 좋은 자재(M)로 꼼꼼하게(ef_construction) 지은 건물은 나중에 더 튼튼하고 길 찾기 쉬운 것과 같습니다.
-
ef는 ‘안내원’: ef 파라미터는 이미 만들어진 인덱스 위에서 검색할 때 조절할 수 있습니다. 사용자가 길을 물어볼 때(쿼리), 얼마나 넓은 범위를 안내해 줄지(탐색 범위) 결정하는 역할입니다. ef 값은 보통 M 값보다 크거나 같게 설정합니다.
Q: “HNSW 튜닝 시 ef_construction은 왜 중요한가요?”
A: “ef_construction은 인덱스 빌드 시 그래프의 품질을 결정하는 핵심 요소이기 때문입니다. 이 값을 높여 정교한 그래프를 만들면, 잠재적인 검색 정확도의 최대치를 높일 수 있습니다. 하지만 빌드 시간이 길어지는 트레이드오프가 있습니다.”
(추가점수) A+: “물론 ef_construction만 고려하는 것은 아닙니다. 노드의 최대 이웃 수를 정하는 M 파라미터로 인덱스의 밀도와 메모리 사용량을 조절하고, 실제 검색 시에는 ef_search 값을 튜닝하여 정확도와 검색 속도 사이의 실시간 균형을 맞추는 것이 일반적입니다. 즉, M과 ef_construction으로 인덱스의 기본 뼈대를 잘 구축한 뒤, ef_search를 통해 서비스 요구사항에 맞는 성능을 조절하는 방식으로 접근합니다.”