Abstract
CF 추천 정확도는 일반적으로 higher-order 상호작용을 고려했을 때 성능 향상이 있었다. deep nonlinear model 이 이론적으로 higher-order 상호작용을 학습할 수 있지만, 실전에서는 상당히 제한적이다. 더욱이 낮은 차원의 deep network embedding 은 표현력을 매우 떨어뜨린다.
이 paper 의 목적은 간단한 linear full-rank 모델의 확장을 더욱 탐구하여, higher-order 상호작용을 추가적인 explicit input-feature 로 표현하는 것
이러한 model-class 는 데이터가 많은 상황에서는 best ranking accuracies 가 최신 딥러닝 방식보다 더 높은 수준이고, 적은 데이터셋에서는 SOTA 딥러닝 모델에 충분히 비교 가능한 수준
그리고 이러한 접근은 HOSLIM 모델의 향상 버전으로 볼 수 있음
실험에서도 성능이 좋았는데, 그 이유는 HOSLIM 에서 사용하는 대용량 positive higher-order 상호작용들이 상대적으로 negative higher-order 상호작용보다 실험에 사용하는 데이터에서 빈도가 덜 하기 때문임
추가적으로 higher-order 상호작용이 중요한 향상을 보일 수 있을 환경을 특정하였음 (characterize)
B) Introduction
딥러닝 모델에서는 higher-order 상호작용이 일반적으로 latent embedding space 에 모델링된다. 너무 embedding space 차원이 낮으면 모델의 예측 정확도가 떨어짐 - Embarrassingly Shallow AutoEncoder (EASER) - This model learns pairwise relations, i.e., between each item i in the input, and each item j in the output of the autoencoder - For instance, given that a user interacted with two items i and k in the input, item j in the output is predicted using a tripletrelation in the proposed model.
C) Review: Pairwise Model (EASER 모델에 대한 짧은 리뷰)
- EASER 모델은 SLIM 모델의 단순화된 버전이다.
- L1-norm regularization 를 지우고, 학습 parameter 의 non-negativity 제한도 지움
- 실험에서 deep nonlinear 모델보다 outperformed 한 결과를 보임
- EASER 모델은 다음과 같은 least-squares 문제를 푸는 모델이다
- 는 상호작용 matrix, 는 학습 모델, 는 Frobenius norm
- 위 식은 Lagrange multiplier method 에 의해 다음과 같은 solution 으로 표현됨
* $\operatorname{diagMat}(\cdot)$ 는 [[diagonal matrix]] 를 의미하고, $\operatorname{diag}(\cdot)$ 는 matrix 의 대각선 원소, 그리고 $\oslash$ 는 elementwise division 을 의미
* 학습된 $\hat{B}$ 는 주어진 사용자 $u$ 의 모든 아이템 $i\inI$ 에 대한 개인화 score 를 $X_{u,\cdot}\cdot\hat{B}$ 로 계산할 수 있음
* $X_{u,\cdot}$ 는 사용자 $u$ 의 아이템들에 대한 과거 상호작용을 나타내는 (row-) vector
D) Higher-Order Model
D.1) Data Representation
-
EASER 모델에서 사용하는 pairwise matrix 의 는 pairwise 관계를 잡아낸다: 사용자가 상호작용한 item 와 score 예측하려는 item
- 만약 어떤 사용자가 두 아이템 을 사용했다면, 해당 모델의 score 예측은 (pairwise sum) 으로 계산된다.
- 이런 방식은 triplet-relation 를 잡아내기 힘들다.
- 좀 더 general 하게, 사용자가 play 한 아이템들의 집합이 라면, higher-order 관계 를 잡아내는 것이 목표다.
- 만약 어떤 사용자가 두 아이템 을 사용했다면, 해당 모델의 score 예측은 (pairwise sum) 으로 계산된다.
-
higher-order 관계를 높은 차원을 가진 tensor 로 표현하는 것이 직관적인 방법인데, 이 논문에서는 고차원 tensor 를 matrix 로 flatten 시킨다.
- 이 과정에서 계산량 문제로 인해 가장 관련 있는 개의 higher-order relations 만 남긴다:
- 을 표현하기 위해, matrix 를 정의
- 해당 matrix 의 row 는 -hot encoding vector: if otherwise set to
- matrix 을 사용하면 가 주어졌을 때, higher-order 학습 데이터 를 생성할 수 있음
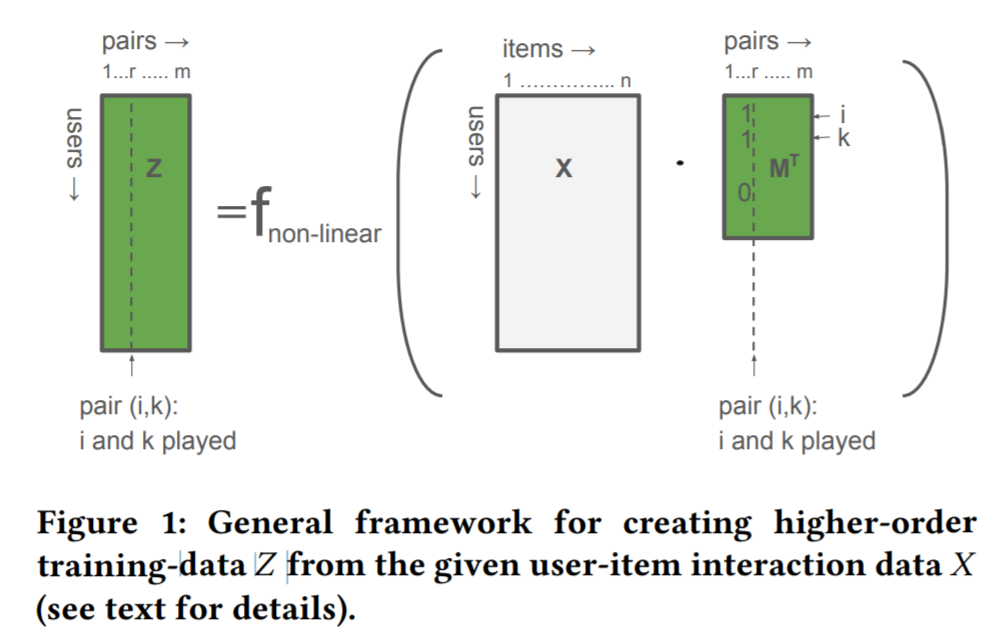
- 를 계산하고 nonlinear 함수를 적용
- 여기서 nonlinear 는 2 를 임계값으로 가지는 함수로, 2 이상이면 을 1 로 설정하고, 아니면 0 으로 설정한다.
- 그림에서는 아이템을 둘 다 play 한 사용자는 2 이므로, 이다.
- 여기서 nonlinear 는 2 를 임계값으로 가지는 함수로, 2 이상이면 을 1 로 설정하고, 아니면 0 으로 설정한다.
-
Training Objective
-
에 이어서, 추가적인 parameter matrix 를 사용하고, 추가로 EASER 모델의 도 사용
-
모델이 학습되었을 때, 유저 의 아이템 에 대한 점수 추정값은 다음과 같음 :
- 는 row 그리고 는 column 를 나타냄
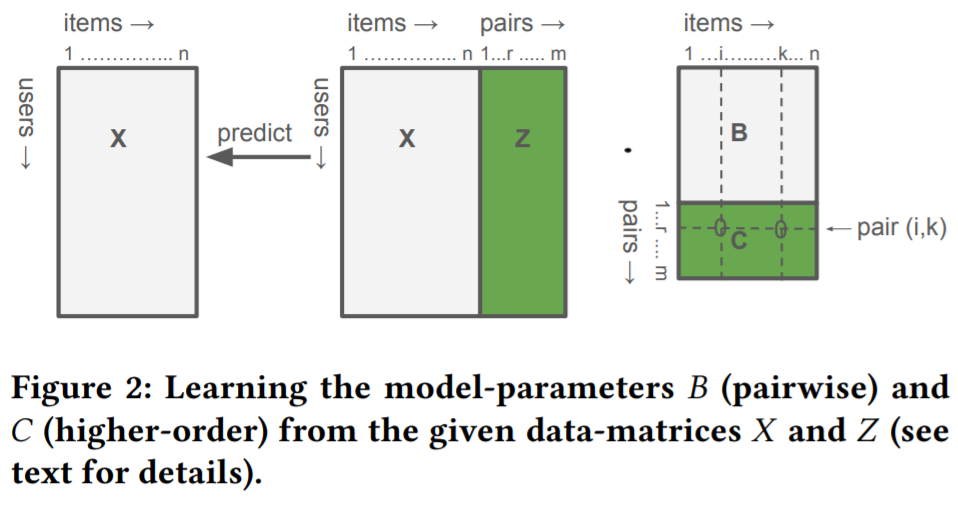
-
계산 효율을 위해 least-square 를 통한 그리고 를 학습한다 :
* $\lambda_C$ 가 매우 크면 parameters $C$ 가 0 으로 수렴하기 때문에 결과적으로 EASER 모델과 거의 비슷하게 되버림 * 두 constraints 는 [[overfitting]] 방지를 위해 꼭 필요함: $\text{diag}(B)=0$ 과 $C\odotM=0$ 는 서로 비슷한 목적을 위한것임 * 자기 자신에 대한 상호작용 결과가 score 추정에 쓰이지 않도록 설계 -
Update Equations for Training
- constrained 목적 함수 최적화를 위해서, [[Lagrange multiplier method]]를 사용할 수 있다. - 일반적으로 이를 Alternating Directions Method of Multipliers(ADMM) 이라고 부른다. - ADMM은 iterative updates를 통해 진행된다. - 업데이트 내용은 생략함 (논문 참조)-
HOSLIM 과 비교
-
E) Related
SLIM - Sparse Linear Methods for Top-N Recommender Systems