Abstract
사용자와 콘텐츠 정보를 활용한 개인화 웹 서비스 (광고, 뉴스 등) 를 제공하는 것은 다음과 같은 두 가지 이유로 어렵다.
- web service is featured with dynamically changing pools of content, rendering traditional collaborative filtering methods inapplicable.
- Furthermore, a significant number of visitors are likely to be entirely new with no historical consumption record whatsoever; this is known as a cold-start situation
- the scale of most web services of practical interest calls for solutions that are both fast in learning and computation. This paper models personalized recommendation of news articles as a contextual bandit problem. 총 사용자 클릭 횟수 증가를 위해, 사용자 클릭 피드백에 기반한 article-selection 전략을 적용
- we argue that any bandit algorithm can be reliably evaluated offline using previously recorded random traffic.
- It is generally difficult to model popularity and temporal changes based solely on content information.
- we need to distribute more traffic to new content to learn its value more quickly, and fewer users to track temporal changes of existing content.
- Often, both users and content are represented by sets of features.
- User features may include historical activities at an aggregated level as well as declared demographic information.
- This paper proposes a new algorithm, LinUCB
B) Multi-armed Bandit Formulation
- Formally,a contextual-bandit algorithm A proceeds in discrete trials
- In trial :
- The algorithm observes the current user and a set of arms or actions together with their feature vectors for .
- The vector summarizes information of __both __the user and arm , and will be referred to as the context.
- Based on observed payoffs in previous trials, A chooses an arm , and receives payoff whose expectation depends on both the user and the arm .
- The algorithm then improves its arm-selection strategy with the new observation, .
- It is important to emphasize here that no feedback (namely, the payoff ) is observed for unchosen arms .
- In the process above, the __total T-trial payoff __of A is defined as .
- Similarly, we define the optimal expected T-trial pay-off as
- where is the arm with maximum expected payoff at trial .
- Our goal is to design A so that the expected total payoff above is maximized.
- Equivalently, we may find an algorithm so that its __regret __with respect to the optimal arm-selection strategy is minimized.
- the -trial regret of algorithm A is defined formally by
- In the context of article recommendation, we may view articles in the pool as arms.
- When a presented article is clicked, a payoff of 1 is incurred; otherwise, the payoff is 0.
- With this definition of payoff, the expected payoff of an article is precisely its clickthrough rate (CTR), and choosing an article with maximum CTR is equivalent to maximizing the expected number of clicks from users, which in turn is the same as maximizing the total expected payoff in our bandit formulation.
- Existing Bandit Algorithms
- Exploration can increase __short-term __regret since some suboptimal arms may be chosen.
- However, obtaining information about the arms’ average payoffs (i.e., exploration) can refine A’s estimate of the arms’ payoffs and in turn reduce long-term regret.
- UCB (Upper Confidence Bound)
- Specifically, in trial , these algorithms estimate both the mean payoff of each arm a as well as a corresponding confidence interval , so that holds with high probability.
- They then select the arm that achieves a highest upper confidence bound (UCB for short):
C) Algorithm
This paper shows that a confidence interval can be computed __efficiently in closed form __when the payoff model is linear, and call this algorithm LinUCB.
C.1) LinUCB with Disjoint Linear Models
 we assume the expected payoff of an arm is linear in its -dimensional feature with some unknown coefficient vector ; namely, for all ,
Equation (2):
This model is called disjoint since the parameters are not shared among different arms.
we assume the expected payoff of an arm is linear in its -dimensional feature with some unknown coefficient vector ; namely, for all ,
Equation (2):
This model is called disjoint since the parameters are not shared among different arms.
- Let be a design matrix of dimension at trial
- whose rows correspond to training inputs (e.g., contexts that are observed previously for article )
- be the corresponding response vector (e.g., the corresponding click/no-click user feedback).
- Applying ridge regression to the training data gives an estimate of the coefficients:
- where is the identity matrix.
- When components in are independent conditioned on corresponding rows in , it can be shown [27] that, with probability at least ,
- for any and , where is a constant.
- In other words, the inequality above gives a reasonably tight UCB for the expected payoff of arm , from which a UCB-type arm-selection strategy can be derived: at each trial , choose
- where This algorithm has a few nice properties. First, its computational complexity is linear in the number of arms and at most cubic in the number of features.
- To decrease computation further, we may update in every step (which takes time), but compute and cache (for all ) periodically instead of in real time.
- Second, the algorithm works well for a dynamic arm set, and remains efficient as long as the size of is not too large.
- Third, if the arm set is fixed and contains arms, then the confidence interval (i.e., ) decreases fast enough with more and more data.
- LinUCB with Hybrid Linear Models
- It is helpful to have features that have both shared and non-shared components.
- Formally, we adopt the following hybrid model by adding another linear term to the right-hand side of Equation (2): :
- is the feature of the current user/article combination, and is an unknown coefficient vector common to all arms.
- This model is hybrid in the sense that some of the coefficients are shared by all arms, while others are not.
D) Evaluation Methodology
- Our goal here is to measure the performance of a bandit algorithm , that is, a rule for selecting an arm at each time step based on the preceding interactions.
- Because payoffs are only observed for the arms chosen by the logging policy, which are likely to often differ from those chosen by the algorithm being evaluated, it is not at all clear how to evaluate based only on such logged data.
- This evaluation problem may be viewed as a special case of the so-called “off-policy evaluation problem” in reinforcement learning
- One solution is to build a simulator to model the bandit process from the logged data, and then evaluate with the simulator.
- However, the modeling step will introduce bias in the simulator and so make it hard to justify the reliability of this simulator-based evaluation approach.
- In contrast, we propose an approach that is simple to implement, grounded on logged data, and unbiased.
- This paper describes a provably reliable technique for carrying out such an evaluation, assuming that the individual events are i.i.d., and that the logging policy that was used to gather the logged data chose each arm at each time step uniformly at random.
- This latter assumption can be weakened considerably so that any randomized logging policy is allowed and our solution can be modified accordingly using rejection sampling, but at the cost of decreased efficiency in using data.
- More precisely, we suppose that there is some unknown distribution from which tuples are drawn i.i.d. of the form , each consisting of observed feature vectors and hidden payoffs for all arms.
- Each such event consists of the context vectors , a selected arm and the resulting observed payoff .
- Crucially, only the payoff is observed for the single arm that was chosen uniformly at random.
- For simplicity of presentation, we take this sequence of logged events to be an infinitely long stream
- however, we also give explicit bounds on the actual finite number of events required by our evaluation method.
D.1) Proposed Policy Evaluator

- The method takes as input a policy and a desired number of “good” events on which to base the evaluation.
- If, given the current history , it happens that the policy chooses the same arm as the one that was selected by the logging policy, then the event is retained, that is, added to the history, and the total payoff updated.
- Otherwise, if the policy selects a different arm from the one that was taken by the logging policy, then the event is entirely ignored, and the algorithm proceeds to the next event without any other change in its state.
- Note that, because the logging policy chooses each arm uniformly at random, each event is retained by this algorithm with probability exactly , independent of everything else.
- This means that the events which are retained have the same distribution as if they were selected by .
- As a result, we can prove that two processes are equivalent: the first is evaluating the policy against real-world events from , and the second is evaluating the policy using the policy evaluator on a stream of logged events.
THEOREM 1. For all distributions of contexts, all policies , all , and all sequences of events ,
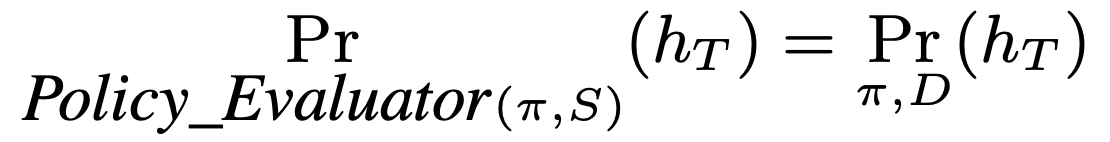 where is a stream of events drawn i.i.d. from a uniform random logging policy and .
Furthermore, the expected number of events obtained from the stream to gather a history of length is .
where is a stream of events drawn i.i.d. from a uniform random logging policy and .
Furthermore, the expected number of events obtained from the stream to gather a history of length is .