Bias & Variance Trade-off
bias와 variance는 모두 낮을수록 좋은 성능을 기대할 수 있지만, 일반적으로 bias를 낮추면 variance가 높아지고, 반대로 variance를 낮추면 bias가 높아지는 경향이 있습니다.
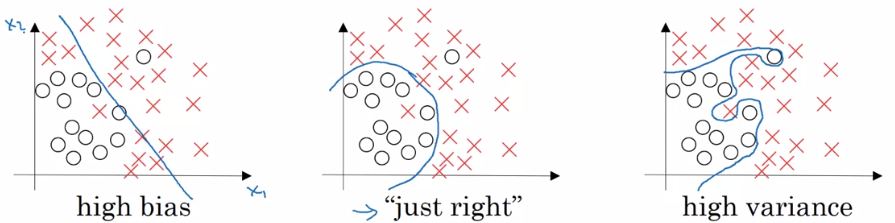
- 과거에는 Bias와 Variance가 반드시 trade-off 관계에 있다고 여겨졌습니다.
- 하지만 최근에는 대규모 신경망과 방대한 데이터의 활용이 용이해지면서, 두 가지 모두를 동시에 줄일 수 있는 가능성도 높아졌습니다.
- 모델의 Expected Validation Error(기대 검증 오차)는 다음과 같이 표현됩니다.
즉, validation error를 최소화하려면 variance와 bias 모두 낮게 학습하는 것이 중요합니다.
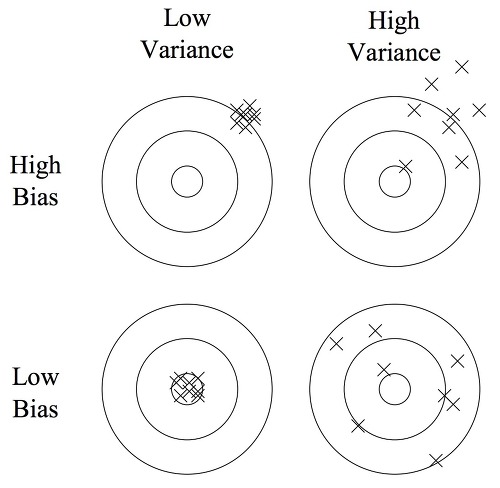
A.1) 고차원 데이터에서의 bias와 variance 판정 방법
예를 들어 고양이 사진을 분류하는 문제에서, 사람이 쉽게 구분할 수 있으므로 base error(기본 오류율)는 거의 0%라고 가정하겠습니다. 이때 train set error(TE)와 dev set error(DE)를 활용해 bias와 variance의 상태를 다음과 같이 판단할 수 있습니다.
-
TE: 1%, DE: 11%인 경우—High Variance
- 학습 데이터에서는 base error에 가까운 매우 낮은 오차를 보이지만, 검증 데이터에서는 오차가 크게 증가하여 편차가 심합니다.
-
TE: 15%, DE: 16%인 경우—High bias
- 학습 데이터에서조차 base error보다 훨씬 높은 오차율을 기록하였으나, 검증 세트와의 편차는 크지 않습니다. 즉, high variance 상황은 아닙니다.
-
TE: 15%, DE: 30%인 경우—High Bias & High Variance
- 학습 데이터에서 높은 오차율(High Bias)을 보이고, 동시에 검증 세트에서도 더 높은 오차로 편차 역시 큽니다(High Variance).
-
TE: 1%, DE: 2%인 경우—Low Bias & Low Variance
- 학습 및 검증 모두에서 base error에 매우 근접한 낮은 오류율을 기록하며, 편차도 거의 없습니다.
만약 사람이 쉽게 구분하지 못하는 문제(예: 매우 흐릿한 고양이 사진)가 주어진다면 base error 자체가 높아질 것이고, 이에 따라 모델 평가 기준도 달라집니다.