Reciprocal Rank Fusion
여러 개의 검색 결과(랭킹 리스트)를 점수(score)가 아닌 순위(rank) 에 기반해 결합하는 알고리즘. Learning-To-Rank(LTR)의 unsupervised method로 분류된다.
A.1) 왜 필요한가?
BM25의 점수(예: 030)와 벡터 서치의 코사인 유사도 점수(예: 01)는 스케일이 완전히 다르다. 단순히 더하거나 가중합을 할 경우, 한 쪽의 점수가 다른 쪽을 압도하는 문제가 발생한다.
RRF는 이 문제를 “점수는 무시하고, 순위만 보자!” 라는 방식으로 해결한다.
A.2) 수식
- : 순위를 매길 문서
- : 번째 검색 결과 리스트에서 문서 의 순위 (1, 2, 3…)
- : 순위가 점수에 미치는 영향을 조절하는 상수 (기본값 60)
A.3) 직관적 이해
- 어떤 문서가 A 랭킹에서 1등, B 랭킹에서 100등이라면, 두 리스트 모두에서 점수를 얻음
- 형태이므로, 순위가 높을수록(숫자가 작을수록) 더 많은 점수. 여기서 은 해당 리스트에서의 순위다.
- 상수 덕분에 낮은 순위의 문서들도 소량의 점수를 받아, 여러 리스트에 반복 등장하는 문서에 유리
A.4) 장점
- 점수 정규화 불필요: 서로 다른 스케일의 검색 결과도 손쉽게 결합
- 매우 간단한 구현: 복잡한 연산이나 추가 작업 없이 적용 가능
- 우수한 기본 성능: 복잡한 Learning-to-Rank 모델 적용 전 베이스라인으로 활용
B) k 파라미터
상수 는 상위 순위 아이템의 영향력을 조절한다.
| k 범위 | 효과 |
|---|---|
| 20-40 | 상위 결과에 더 큰 영향력 부여 |
| 60 (기본값) | 일반적으로 잘 작동 |
| 80-100 | 순위 간 점수 차이가 더 완만 |
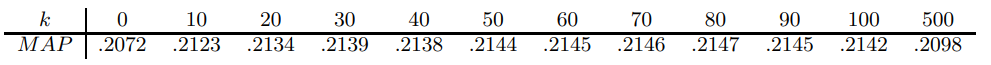
Table 1: Effect of on MAP for RRF of 30 model system results on TREC topics 351-400.
실험적으로 k를 1~100 사이에서 sweep하면 NDCG@1000, Recall@K 등의 메트릭이 수 포인트 변동할 수 있다. 도메인에 맞게 튜닝 권장.
C) Weighted RRF
기본 RRF는 모든 랭킹 소스를 동등하게 취급하지만, Weighted RRF 는 각 소스에 다른 가중치를 부여할 수 있다.
C.1) 수식
- : 번째 검색 소스의 가중치
- 나머지는 기본 RRF와 동일
C.2) 언제 사용하는가?
각 retriever의 신뢰도나 중요도가 다를 때 유용하다:
| 쿼리 유형 | 예시 | 가중치 설정 |
|---|---|---|
| 개념적 쿼리 | ”아늑한 분위기의 레스토랑” | Semantic: 0.8, BM25: 0.2 |
| 정확한 키워드 | ”마르게리타 피자” | BM25: 0.8, Semantic: 0.2 |
| 위치 기반 | ”근처 이탈리안” | Location: 0.7, Menu: 0.3 |
C.3) 구현 예시
C.3.1) Elasticsearch
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": { "query": { "match": { "text": "pizza" } } },
"weight": 1.0
},
{
"knn": { "field": "vector", "query_vector": [...] },
"weight": 0.7
}
],
"rank_constant": 60
}
}
}C.3.2) Python 직접 구현
def weighted_rrf(rankings: list[list[str]], weights: list[float], k: int = 60) -> dict[str, float]:
"""
rankings: 각 retriever의 정렬된 문서 ID 리스트
weights: 각 retriever의 가중치
"""
scores = {}
for ranking, weight in zip(rankings, weights):
for rank, doc_id in enumerate(ranking, start=1):
scores[doc_id] = scores.get(doc_id, 0) + weight / (k + rank)
return dict(sorted(scores.items(), key=lambda x: -x[1]))C.4) 주요 벡터 DB 지원 현황
| 시스템 | Weighted RRF 지원 |
|---|---|
| Elasticsearch | ✅ 8.x부터 지원 |
| Milvus | ✅ RRFRanker에서 지원 |
| Azure AI Search | ✅ vector weighting 지원 |
| OpenSearch | ⏳ 로드맵에 포함 |
| Weaviate | ✅ alpha 파라미터로 조절 |
D) 추천 시스템 적용
추천 시스템에서 RRF는 ensemble 방식에 활용된다:
- 각 모델로부터 순위가 매겨진 추천 결과를 받아옴
- 해당 추천 결과들을 활용하여 아이템 별 RRF score 계산
- 최종 순위 결정
RRF 식에서:
- 각 모델의 추천 결과 → Document
- 추천 결과 내 아이템의 순위 →