Python 관련 인터뷰 정리
Python 의 데이터 모델은 어떻게 되는가
python 은 object-oriented programming(OOP) language 이다. 즉, 모든 데이터는 객체나 객체 간의 관계로 표현된다.
모든 객체는 identity, type, value 를 가진다. 여기서 identity 는 한번 만들어 진 후에 변경되지 않고, 이를 객체의 주소로 생각할 수 있다.
id()함수를 사용하면 객체의 identity 를 정수로 표현한 값을 확인할 수 있다.
객체는 절대로 명시적으로 (explicitly) 없애지 못한다. 대신, 그 객체가 사용되지 않을 것이라 판단되면 (unreachable), garbage collector 에 의해 수집된다.
B) Python 의 변수는 다른 언어와 무엇이 다른가?
python 은 변수라는 메모리 공간에 값을 직접 저장하지 않는다.
객체들은 모두 다른 메모리 공간에 저장되어 있고, 변수는 값 객체를 가리키고만 있다.
그래서 숫자나 문자도 모두 객체인 python 에는 동일한 객체의 값의 경우에는 같은 주소값을 가진다.
a = 10
b = 10
c = 20
print(id(a)) # 140734913394752
print(id(b)) # 140734913394752
print(id(c)) # 140734913395072C) 객체 지향 프로그래밍 (OOP)
C.1) 장/ 단점
- 장점
- 코드 재사용이 용이: 남이 만든 클래스를 가져와서 이용할 수 있고 상속을 통해 확장해서 사용할 수 있음.
- 유지보수가 쉬움: 절차 지향 프로그래밍에서는 코드를 수정해야할 때 일일이 찾아 수정해야하는 반면 객체 지향 프로그래밍에서는 수정해야 할 부분이 클래스 내부에 멤버 변수혹은 메서드로 있기 때문에 해당 부분만 수정하면 됨.
- 대형 프로젝트에 적합: 클래스단위로 모듈화시켜서 개발할 수 있으므로 대형 프로젝트처럼 여러명, 여러회사에서 개발이 필요할 시 업무 분담하기 쉽다.
- 단점
- 처리속도가 상대적으로 느림
- 객체가 많으면 용량이 커질 수 있음
- 설계시 많은 시간과 노력이 필요
C.2) OOP 의 키워드 5 가지 (주로 (1) 을 제외하면 4 가지)
-
클래스와 객체
- 클래스: 문제해결을 위한 데이터의 속성(attribute) 과 행위(behavior) 를 변수와 메서드로 정의한 것
- 객체: 클래스를 통해 실제 메모리상에 할당된 데이터
-
추상화
- 객체의 공통된 속성과 행위를 추출하는 과정
- 예) 토끼, 강아지, 고양이는 동물이라는 공통된 정보로 추상화
-
캡슐화
- 객체의 상세한 내용은 객체 외부로부터 숨기고 제한된 데이터와 메소드만을 노출시켜 객체와 상호작용 할 수 있도록 하는 것
- 키워드: 정보 은닉, 접근 제한자 (public, private)
- 객체의 상세한 내용은 객체 외부로부터 숨기고 제한된 데이터와 메소드만을 노출시켜 객체와 상호작용 할 수 있도록 하는 것
-
다형성
- 하나의 변수명, 함수명 등이 상황에 따라 다른 의미로 해석될 수 있는 것
- 즉, 오버라이딩 (Overriding), 오버로딩 (Overloading) 이 가능하다는 얘기
- Overriding: 상위 클래스의 함수를 하위 클래스에서 똑같은 이름으로 재정의 하는것
- 함수의 return type 와 parameter type, 개수는 동일해야 한다.
- Overloading: 함수의 이름은 같으나 함수의 매개변수 숫자, 타입등을 달리해서 다르게 사용하는것을 의미
- Overriding: 상위 클래스의 함수를 하위 클래스에서 똑같은 이름으로 재정의 하는것
-
상속
- 클래스를 재사용 하는것
- 상위 클래스를 하위 클래스에서 상속 받게 되면 상위 클래스의 멤버변수나 메소드를 그대로 물려 받을 수 있다.
- 상속이 있기 때문에 코드를 재활용할 수 있고 그렇기 때문에 생산성이 높고 유지보수 하기가 좋다.
D) Python 은 Interpreted Language 이다. 그 의미는?
interpreted language 는 컴파일러를 거쳐서 기계어로 변환되지 않고 바로 실행되는 프로그래밍 언어를 의미한다.
python 코드를 실행할 때, python code(.py) 는 bytecode(.pyc or .pyo) 로 변환되고 가상 머신 (virtual machine) 에 전송된 후 실행된다.
- Bytecode 는 interpreter(인터프리터) 에 의해 실행될 수 있는 low-level 의 명령어 집합을 의미한다.
- 코드가 compile 되는 행위는 C++ 과 같다. 다만, CPU 에서 직접적으로 실행되는 기계어로 변환되지 않고 bytecode 로 바뀐다.
- 만약, 반복적으로 python 코드를 실행하게 된다면, interpreter 는 코드가 수정되지 않는 한 기존의 bytecode 를 재사용한다.
- time stamp 를 체크하여 코드가 수정되지 않았다는 것을 확인한다.
Interpreted language 는 플랫폼에 구애받지 않는다는 것이 장점이다.
- Interpreter 와 bytecode 의 버전만 동일하다면, 어떤 플랫폼 (윈도우, 맥 등) 에서든 실행시킬 수 있다.
E) Garbage Collection 이란 무엇인가?
Garbage collector 에 의해 수행되는 동작으로, 더 이상 사용하거나 참조되지 않는 프로그램 내의 객체들을 메모리에서 제거하는 작업을 의미한다.
Garbage collection 의 동작은 reference counting 으로 단순히 설명할 수 있다.
- Garbage collector 는 객체들에 대한 참조 횟수 (reference count) 를 추적하여, 그 횟수가 0 에 도달할 경우 해당 객체를 삭제한다.
sys.getrefcount(변수 이름)으로 참조 횟수를 확인 가능
- 참고로, reference counting 은 python 에서 비활성화 할 수 없는 동작이다.
F) Python 은 Dynamically Typed Language 이다. 그 의미는?
python 이 동적 바인딩 (dynamic binding) 을 수행한다는 의미다.
- 동적 바인딩: 바인딩 (binding) 이 런타임중에 발생하고, 프로그램 실행 도중 변경 가능
- 바인딩: 프로그램의 어떤 기본 단위가 가질 수 있는 구성요소의 구체적인 값, 성격을 확정하는 것
- C 언어
int num = 123의 경우,num은 변수의 이름,int는 자료형,123는 값을 각각 할당하는 과정을 바인딩이라고 함
- C 언어
코드가 실행되기 전까지 변수의 type(타입) 을 확인할 수 없다. 그래서 python 에서 선언 (declaration) 은 어떤 의미도 없다.
F.1) 변수와 메모리
변수가 선언되면, 변수의 값은 메모리에 저장되고, 그 값은 변수의 이름과 묶인다 (bind). 그리고 실행 후에 변수의 이름을 통하여 값을 확인한 후, 그 변수의 type 을 확인할 수 있다.
F.2) 함수와 메모리
함수의 동적 바인딩은 실행파일을 만들 때 호출할 함수의 메모리 주소가 확정되지 않고 보류상태로 둔다. 이후 실제 실행 시간에 호출할 함수의 주소가 결정되기 때문에, 이 주소를 저장할 공간을 미리 확보해둔다 (4byte).
실행될지 확정되지 않은 함수를 위해 저장공간을 빼둬야 하는 점 때문에 메모리 관리에 있어 비효율적일 수 있다.
G) lambda 가 무엇인지? 왜 쓰는 것인지?
lambda 는 람다 표현식이라고 불리며, 이름이 없는 익명 함수다. 인라인 (in-line) 으로 정의된다.
함수를 간편하게 작성할 수 있어서, 다른 함수의 인수로 함수가 필요로 할 때 주로 사용한다.
-
사용 예시
mul = lambda a, b : a * b print(mul(2, 5)) # output => 10lambda는 익명 함수이기 때문에, 이름 (변수) 를 할당해주지 않으면 사용할 수 없다.
H) Namespace 는 무엇인지? 왜 사용하는 것인지?
네임스페이스라고 불리며, 객체와 이름 간 매핑 정보를 포함하는 공간을 의미한다.
프로그램 내에서 객체 (object) 들의 이름을 충돌없이 사용하기 위해서 namespace 를 사용한다.
- 같은 이름을 여러 객체들이 공통으로 사용할 수 있도록, namespace 는 dictionary 를 활용하여, 이름 (key)- 객체 (value) 의 형식으로 저장한다.
namespace 에는 세가지 계층적 종류가 존재한다. 가장 낮은 단계부터 1) local, 2) global, 3) built-in namespace 가 존재한다.
- local namespace: 함수 내에서 정의되는 이름들을 포함하는 namespace. 이 namespace 는 함수가 호출될 때 임시로 생성되었다가 함수가 끝나면 (return) 초기화된다.
- global namespace: 프로젝트에서 import 되는 여러 패키지, 모듈들에서 사용하는 이름들을 포함하는 namespace. 이 namespace 는 스크립트에서 모듈 또는 패키지가 import 될 때 생성되고, 스크립트 실행이 종료되면 사라진다.
- built-in namespace: python 의 핵심 built-in 함수 또는 여러 types 들의 이름들을 포함하는 namespace.
- 주로 낮은 단계의 namespace 를 안에 있다 (inner) 고 하며, 높은 단계의 namespace 를 밖에 있다 (outer) 고 한다.
- outer namespace 에서 inner namespace 에 접근할 수 없다.
I) global 명령어와 nonlocal 명령어는 무엇인가?
I.1) global 명령어
global 은 지역변수가 동일한 이름의 전역변수를 가리키게 만드는 명령어다.
x = 20
def global_test():
global x
x = 30
global_test()
print(x) # 30 출력- 만약
global x가 없었다면,x는 20 이 되었을 것이다.
I.1.1) 중첩되는 global
x = 15
def f():
x = 30
def g():
global x
x = 60
def h():
x = 120
h()
g()
f()
print(x) # 60 출력I.2) nonlocal 명령어
nonlocal 이 사용된 함수 바로 한단계 바깥쪽에 위치한 동일한 이름의 변수를 가리키게 한다.
x = 20 # 전역변수 (global variable)
def f():
x = 40
def g():
nonlocal x
x = 80
g() # 함수 g를 실행하여 nonlocal이 적용되도록 한다.
print(x) # 함수 f에서의 x값이 출력된다.(함수 g에서 nonlocal 의 영향을 받아 변수가 80으로 변경되었다.)
f()
print(x) # 모든 함수 실행이 끝나고, 전역 변수 x를 출력한다.(출력값은 처음값인 20이다)80
20I.2.1) nonlocal 주의 사항
nonlocal 은 전역변수에 영향을 줄 수는 없다. 오직 계층적 지역변수에만 영향을 줄 수 있다.
x = 70 # 전역변수 (global variable)
def f():
nonlocal x
x= 140
f()
print(x) # SyntaxError: no binding for nonlocal 'x' foundJ) 객체의 복사는 어떻게 하는가?
Python 은 pass by assignment 를 수행한다. 이는 총 세가지 형태로 존재한다. 1) = 를 이용한 단순 복사, 2) Shallow Copy (얕은 복사), 3) Deep Copy (깊은 복사)
J.1) 단순 복사
복사하려는 객체의 종류에 따라 복사 방식이 바뀐다.
변경 가능 (mutable) 한 객체일 경우, 변수에 그 객체의 주소 값을 복사한다. (e.g. list)
변경 불가능 (immutable) 한 객체일 경우, 변수에 그 객체와 값이 동일한 새로운 객체를 할당한다. (e.g. int)
-
Shallow Copy (얕은 복사)
- Shallow Copy 는 mutable 한 객체도 값이 동일한 새로운 객체를 할당해준다 (편의를 위해 이를 완벽히 복사한다고 칭하자).
-
다만, mutable 한 객체가 또 다른 mutable 객체를 포함할 경우 (복합 객체의 경우), 가장 바깥의 객체만 완벽히 복사한다.
a = [1, [1, 2, 3]] b = copy.copy(a) # shallow copy 발생 print(b) # [1, [1, 2, 3]] 출력 b[0] = 100 print(b) # [100, [1, 2, 3]] 출력, print(a) # [1, [1, 2, 3]] 출력 c = copy.copy(a) c[1].append(4) # 리스트의 두번째 item(내부리스트)에 4를 추가 print(c) # [1, [1, 2, 3, 4]] 출력 print(a) # [1, [1, 2, 3, 4]] 출력
-
- Shallow Copy 는 mutable 한 객체도 값이 동일한 새로운 객체를 할당해준다 (편의를 위해 이를 완벽히 복사한다고 칭하자).
-
Deep Copy
-
복합 객체의 경우라도 재귀적으로 객체 내의 모든 객체들을 완벽히 복사하여, 새로운 객체를 변수에 할당한다.
a = [1, [1, 2, 3]] b = copy.deepcopy(a) # deep copy 실행 print(b) # [1, [1, 2, 3]] 출력 b[0] = 100 b[1].append(4) print(b) # [100, [1, 2, 3, 4]] 출력 print(a) # [1, [1, 2, 3]] 출력
-
K) Docstring 이란 무엇인가?
모듈, 함수, 클래스 등에 적용되는 문서화를 위한 주석
""" """ 를 이용하여 아래와 같이 작성한다.
class CustomClass:
"""
클래스의 문서화 내용을 입력합니다.
"""
def custom_function(param):
'''
함수의 문서화 내용을 입력합니다.
'''
... 코드 ...
help 함수와 __doc__ 속성을 이용하면 각 객체의 docstring 을 확인할 수 있다.
cc = CustomClass()
help(cc)
print(cc.__doc__)Help on CustomClass in module __main__ object:
class CustomClass(builtins.object)
| 클래스의 문서화 내용을 입력합니다.
|
| Methods defined here:
|
| custom_function(param)
| 함수의 문서화 내용을 입력합니다.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
클래스의 문서화 내용을 입력합니다. L) 사용자 정의 Exception 은 어떻게 만드는가?
Exception 클래스를 상속받아서 원하는 예외를 만든다.
class 예외이름(Exception):
def __init__(self):
super().__init__('에러메시지')L.1) 사용 예시
class NotThreeMultipleError(Exception): # Exception을 상속받아서 새로운 예외를 만듦
def __init__(self):
super().__init__('3의 배수가 아닙니다.')
def three_multiple():
try:
x = int(input('3의 배수를 입력하세요: '))
if x % 3 != 0: # x가 3의 배수가 아니면
raise NotThreeMultipleError # NotThreeMultipleError 예외를 발생시킴
print(x)
except Exception as e: # as 뒤에 변수를 지정하면 에러를 받아옴
print('예외가 발생했습니다.', e) # e에 저장된 에러 메시지 출력
three_multiple()M) PEP8 이란 무엇인가?
N) 모듈이란?
모듈 (Module) 은 하나의 파일 .py 을 가리킴
- 모듈은 파이썬 코드를 논리적으로 묶어서 관리하고 사용할 수 있도록 돕는 것
파이썬 모듈 .py 파일은 import 하여 사용할 수 있을 뿐만 아니라,
해당 모듈 파일 안에 있는 스크립트 전체를 바로 실행할 수도 있다.
-
# run.py import sys def openurl(url): #..본문생략.. print(url) if __name__ == '__main__': openurl(sys.argv[1])
파이썬에서 모듈을 import 해서 사용할 경우 그 모듈 안의 __name__ 은 해당 모듈의 이름이 되며, 모듈을 스크립트로 실행할 경우 그 모듈 안의 __name__ 은 "__main__" 이 된다.
O) 가변 인수 (*args 그리고 ** kwargs) 란 무엇인가?
정해지지 않는 개수의 인자를 함수의 입력으로 받을 때 사용한다.
함수에서 다음과 같이 가장 마지막 parameter에 *args 또는 **kawrgs 를 포함시킨다.
def func_param_with_var_args(name, age, *args):
print("name=",end=""), print(name)
print("age=",end=""), print(age)
print("args=",end=""), print(args)
func_param_with_var_args("정우성", "01012341234", "seoul", 20)name=정우성
age=01012341234
args=('seoul', 20)*args가tuple타입으로 함수에 입력되는 것을 확인할 수 있다.- 굳이 이름은
*args가 아니라*kiwis등 자신이 원하는 변수 명을 사용해도 상관없다.
**kwargs 는 keyword arguments 의 준말이다. 키워드를 이용한 여러 인자들을 받을 때 사용한다.
def func_param_with_kwargs(name, age,**kwargs):
print("name=",end=""), print(name)
print("age=",end=""), print(age)
print("kwargs=",end=""), print(kwargs)
func_param_with_kwargs("정우성", "20", mobile="01012341234", address="seoul")name=정우성
age=20
kwargs={'mobile': '01012341234', 'address': 'seoul'}**kwargs가dict타입으로 함수에 입력되는 것을 확인할 수 있다.*args와 마찬가지로, 굳이 이름은**kwargs가 아니라**kiwis등 자신이 원하는 변수 명을 사용해도 상관없다.
P) 함수의 인자 배치 순서는 어떻게 되는가?
일반 인자 -> default 일반 인자 -> 가변 인자 -> Keyword-Only 인자 -> 키워드 가변 인자 순으로 진행된다.
P.1) 예시
def mixed_params(age, name="아이유", *args, address, **kwargs):
pass
mixed_params(20, "정우성", "01012341234", "male", address="seoul", mobile="01012341234")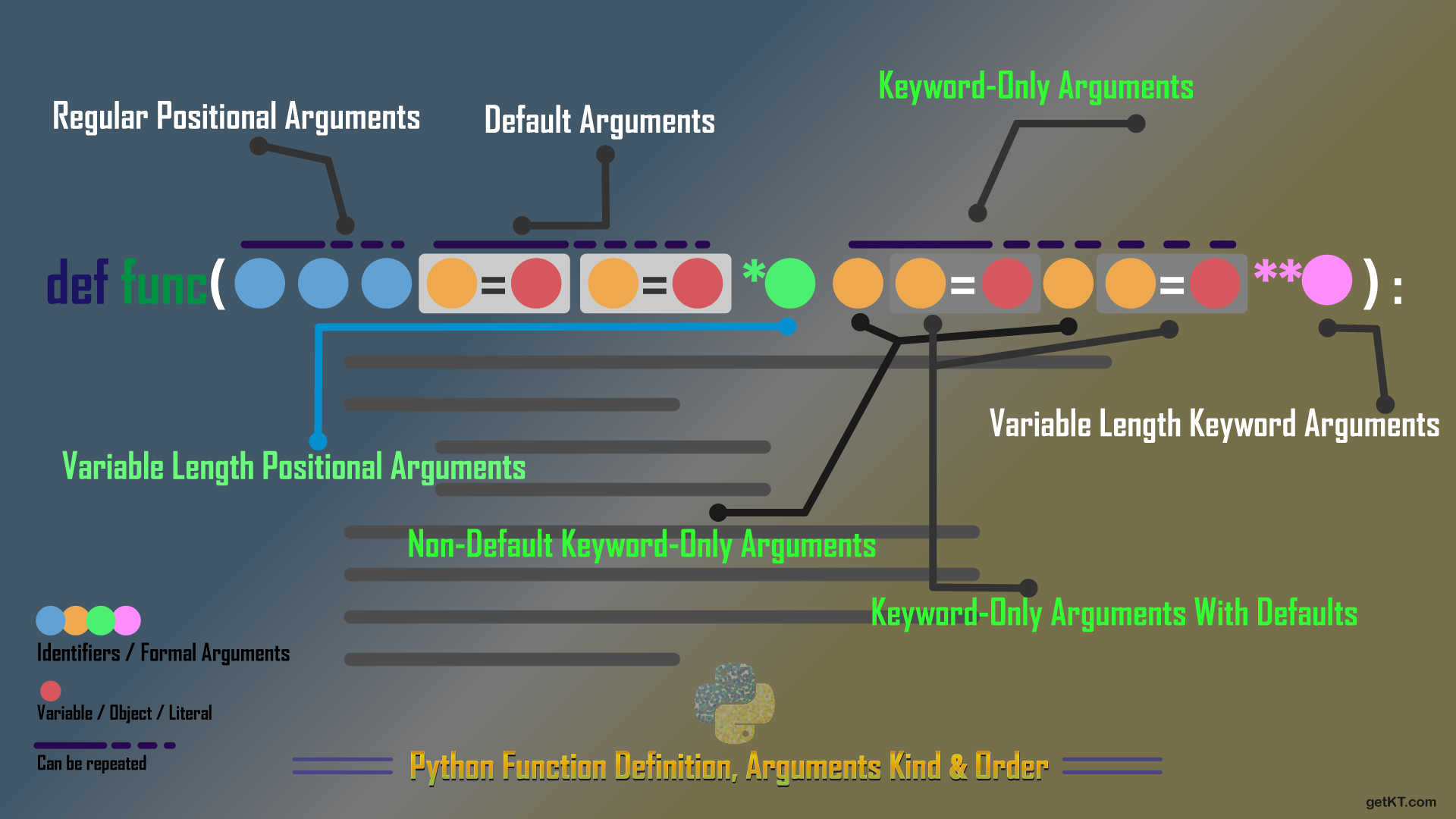
Q) GIL 이란 무엇인가?
Global Interpreter Lock 의 준말로, python interpreter 가 오직 하나의 thread 를 control 할 수 있게 하는 lock 방식이다.
- 이 의미는 오직 특정 시간에만 하나의 쓰레드가 수행가능한 상태로 놓여진다는 것을 의미한다.
single-threaded 코드에서는 GIL 에 의한 영향을 확인할 수 없지만, multi-threaded 코드에서는 performance bottleneck 이 발생할 수 있다.
- 실제로 많은 CPU 코어와 multi-threaded 구조를 지닌 상태더라도 GIL 은 오직 하나의 thread 만 실행하도록 허용한다.
Q.1) GIL 은 왜 필요한 것인가?
아래와 같은 예를 확인해보자.
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3어떤 객체의 reference count 가 0 에 도달하게 되면, garbage collector 는 해당 객체를 메모리에서 해제시킨다.
만약 쓰레드가 여러개고, lock 존재하지 않다면, 쓰레드에 의해 reference count 가 동시에 여러번 깎일 수 있다. 또는 여러번 증가할 수 있다. 전자의 경우 reference count 가 -1 에 도달할 수 있고, 영원히 메모리에서 객체가 해제되지 않는 ‘메모리 누수’ 현상이 발생할 것이다.
이러한 현상을 완화하기 위해서, 여러 쓰레드가 동시에 공유되는 데이터 구조를 건드리지 못하도록 lock 을 건다.
하지만, lock 을 획득하고 해제하는 과정에서의 performance 저하나, deadlock 현상이 발생할 수 있다.
- Deadlock: 한 개보다 많은 lock 을 풀 필요가 있는 상황
The GIL is a single lock on the interpreter itself which adds a rule that execution of any Python bytecode requires acquiring the interpreter lock. This prevents deadlocks (as there is only one lock) and doesn’t introduce much performance overhead. But it effectively makes any CPU-bound Python program single-threaded.
Q.2) GIL 을 대체할 방법은 없는가?
Multi-threading 대신, multi-processing 을 수행한다. 각 python process 는 python interpreter 와 memory 공간을 개별적으로 가지게 될 것이고 GIL 이 lock 을 거는일은 없을 것이다.
그 대신 멀티프로세스를 사용하게 되면, 자원공유가 어려워지고 프로세스 spawn 과정에서 시간이 조금 더 지연될 수 있다.
R) Iterator 란 무엇인가?
이터레이터 (iterator) 는 반복 가능한 (iterable) 객체의 값을 차례대로 꺼낼 수 있는 객체 (object) 다.
- 객체가 반복 가능한 객체인지 알아보는 방법은 객체에
__iter__메서드가 들어있는지 확인해보면 된다.
Iterator 를 찾는 방법은 해당 객체의 __iter__ method 를 호출하면 된다.
>>> [1, 2, 3].__iter__()
<list_iterator object at 0x03616630>Iterator 는 __next__ method 를 통해 값을 차례대로 출력하고, 마지막 값 출력 이후에 StopIteration 예외를 발생시킨다.
>>> it = [1, 2, 3].__iter__()
>>> it.__next__()
1
>>> it.__next__()
2
>>> it.__next__()
3
>>> it.__next__()
Traceback (most recent call last):
File "<pyshell#48>", line 1, in <module>
it.__next__()
StopIteration__iter__,__next__를 가진 객체를 이터레이터 프로토콜 (iterator protocol) 을 지원한다고 말한다.
__iter__ 와 __next__ 대신 __getitem__ 만 구현해도 iterator 를 만들 수 있다.
class Counter:
def __init__(self, stop):
self.stop = stop # 반복을 끝낼 숫자
def __getitem__(self, index): # 인덱스를 받음
if index < self.stop: # 인덱스가 반복을 끝낼 숫자보다 작을 때
return index # 인덱스를 반환
else: # 인덱스가 반복을 끝낼 숫자보다 크거나 같을 때
raise IndexError # 예외 발생S) Generator 란 무엇인가?
generator 는 iterator 를 생성해주는 함수 (method) 다.
iterator 는 클래스에 __iter__, __next__ 또는 __getitem__ 메서드를 구현해야 하지만, generator 는 함수 안에서 yield 라는 키워드를 사용해서 값을 지정해준다. 그래서 제너레이터는 이터레이터보다 훨씬 간단하게 작성할 수 있음.
def number_generator(stop):
n = 0 # 숫자는 0부터 시작
while n < stop: # 현재 숫자가 반복을 끝낼 숫자보다 작을 때 반복
yield n # 현재 숫자를 바깥으로 전달
n += 1 # 현재 숫자를 증가시킴
for i in number_generator(3):
print(i)S.1) Generator 표현식
(식 for 변수 in 반복가능한객체)리스트 표현식을 사용할 때 [ ](대괄호) 를 사용했다. 같은 리스트 표현식을 ( )(괄호) 로 묶으면 제너레이터 표현식이 된다. 리스트 표현식은 처음부터 리스트의 요소를 만들어내지만 제너레이터 표현식은 필요할 때 요소를 만들어내므로 메모리를 절약할 수 있다.
>>> [i for i in range(50) if i % 2 == 0]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48]
>>> (i for i in range(50) if i % 2 == 0)
<generator object <genexpr> at 0x024F02A0>T) Class
T.1) 추상 클래스 (abstract class)
추상 클래스는 메서드의 목록만 가진 클래스이며 상속받는 클래스에서 메서드 구현을 강제하기 위해 사용
- 추상 클래스는 인스턴스로 만들 수가 없다. 오직 상속의 목적만 있다.
추상 클래스를 만들려면 import 로 abc 모듈을 가져와야 한다 ( abc 는 abstract base class 의 약자). 또한 클래스의 ( )(괄호) 안에 metaclass=ABCMeta 를 지정하고, 메서드를 만들 때 위에 @abstractmethod 를 붙여서 추상 메서드로 지정한다.
from abc import *
class 추상클래스이름(metaclass=ABCMeta):
@abstractmethod
def 메서드이름(self):
코드T.1.1) 추상 클래스 예제
from abc import *
class StudentBase(metaclass=ABCMeta):
@abstractmethod
def study(self):
pass
@abstractmethod
def go_to_school(self):
pass
class Student(StudentBase):
def study(self):
print('공부하기')
def go_to_school(self):
print('학교가기')
james = Student()
james.study()
# 공부하기
james.go_to_school()
# 학교가기T.2) super() 로 부모 클래스 초기화하기
super() 를 사용해서 부모 (기반) 클래스의 __init__ 메서드를 호출
- 만약 파생 클래스에서
__init__메서드를 생략한다면 기반 클래스의__init__이 자동으로 호출되므로super()는 사용하지 않아도 됩니다.
def __init__(self):
print('Person __init__')
self.hello = '안녕하세요.'
class Student(Person):
def __init__(self):
print('Student __init__')
super().__init__() # super()로 기반 클래스의 __init__ 메서드 호출
self.school = '파이썬 코딩 도장'
james = Student()
# Student __init__
# Person __init__
print(james.school)
# 파이썬 코딩 도장
print(james.hello)
# 안녕하세요.T.3) 비공개 (private) Class 속성 사용하기
__속성 으로 표기하면 된다.
class Knight:
__item_limit = 10 # 비공개 클래스 속성
def print_item_limit(self):
print(Knight.__item_limit) # 클래스 안에서만 접근할 수 있음
x = Knight()
x.print_item_limit() # 10
print(Knight.__item_limit) # 클래스 바깥에서는 접근할 수 없음
# AttributeError: type object 'Knight' has no attribute '__item_limit' T.4) Static Method 만들기
정적 메서드는 다음과 같이 메서드 위에 @staticmethod 를 붙임
정적 메서드는 인스턴스의 상태를 변화시키지 않는 메서드를 만들 때 사용한다.
class Calc:
@staticmethod
def add(a, b):
print(a + b)
@staticmethod
def mul(a, b):
print(a * b)
Calc.add(10, 20) # 클래스에서 바로 메서드 호출
Calc.mul(10, 20) # 클래스에서 바로 메서드 호출T.5) Class Method 만들기
클래스 메서드는 다음과 같이 메서드 위에 @classmethod 를 붙인다.
클래스 메서드는 정적 메서드처럼 인스턴스 없이 호출할 수 있다는 점은 같다. 하지만 클래스 메서드는 메서드 안에서 클래스 속성, 클래스 메서드에 접근해야 할 때 사용한다.
class Person:
count = 0 # 클래스 속성
def __init__(self):
Person.count += 1 # 인스턴스가 만들어질 때
# 클래스 속성 count에 1을 더함
@classmethod
def print_count(cls):
print('{0}명 생성되었습니다.'.format(cls.count)) # cls로 클래스 속성에 접근
james = Person()
maria = Person()
Person.print_count() # 2명 생성되었습니다.- 클래스 메서드는 첫 번째 매개변수가
cls인데 여기에는 현재 클래스가 들어온다. 따라서cls.count처럼cls로 클래스 속성count에 접근할 수 있다.
T.6) 클래스로 Decorator 를 만들기
클래스를 활용할 때는 인스턴스를 함수처럼 호출하게 해주는 __call__ 메서드를 구현해야 한다.
class Trace:
def __init__(self, func): # 호출할 함수를 인스턴스의 초깃값으로 받음
self.func = func # 호출할 함수를 속성 func에 저장
def __call__(self):
print(self.func.__name__, '함수 시작') # __name__으로 함수 이름 출력
self.func() # 속성 func에 저장된 함수를 호출
print(self.func.__name__, '함수 끝')
@Trace # @데코레이터
def hello():
print('hello')
hello() # 함수를 그대로 호출
# hello 함수 시작
# hello
# hello 함수 끝