Abstract
S-MDP 문제를 다룬 paper 이다. S-MDP 란 매 step 마다 item 들의 부분 집합을 선택하는 MDP 문제
action 과 state space 가 large 하면, S-MDP 문제는 풀기 어려움 (interactable): 특히 items 개수가 매우 클 경우
이를 해결하기 위해 다음과 같은 방식을 채용한 deep RL 알고리즘을 제안
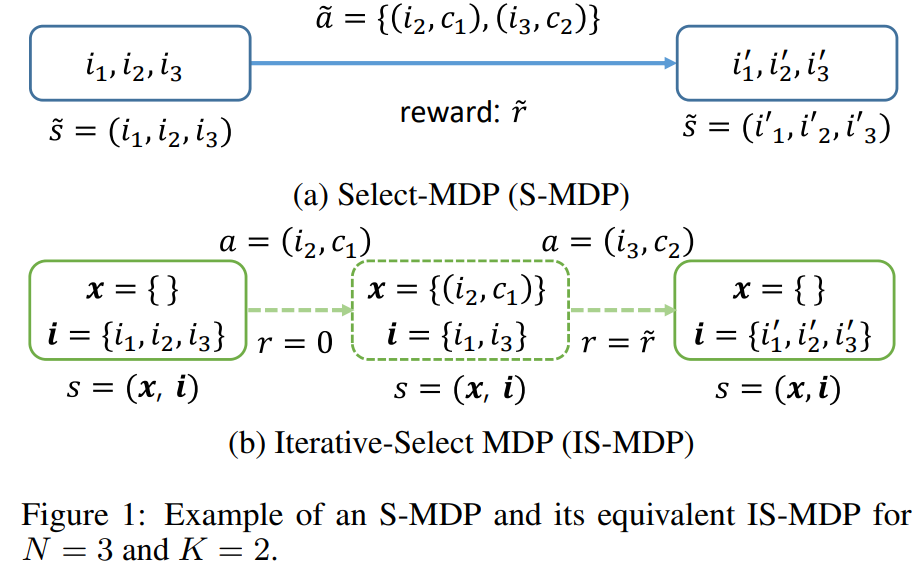
- 첫째로, 기존의 S-MDP 문제를 Iterative Select-MDP (IS-MDP) 문제로 치환
- 이는 최적의 actions 을 취하는 경우 S-MDP 문제와 동일함
- IS-MDP 문제는 동시에 아이템들을 선택하는 joint action 방식을 개의 반복적 선택 방식으로 decompose 시켜서 actions 의 수를 줄임 (states 개수를 늘리는 것으로 trade off)
- 둘째로, 첫번째 방식에서 발생하는 state 공간의 증대를 IS-MDP 의 대칭적 구조와 가중치를 공유하는 Q-networks 를 활용하여 해결
- 실험에서는 item space 가 large 하는 경우에 잘 동작했고, training phase 와 다른 item spaces 환경에서도 잘 동작함을 보였음
- 학습 때 이고, 환경에서 잘 동작
B) Introduction
- 풋볼 리그: 리그 내 이기는 matches 횟수 최대화
- 각 match 마다 개의 선수 중 개의 선수들 (라인업) 을 선택: action
- 그리고 포지션 중 하나에 할당 (중복 가능): command
- 각 후보 선수 (item ) 들에 대한 현재 상태 (information ) 의 집합 (state: )
- 경기 도중에는 결과 (reward: ) 를 확인하고 명의 선수들의 다음 state 가 결정될 때까지 감독을 진행할 수 없음
- 해당 state 는 확률적으로 전이 확률 함수 에 의해 결정됨
- 위와 같은 종류의 문제를 MDP 형태로 모델링하고 이를 Select-MDP (S-MDP) 라고 부른다
- S-MDP::
- Recommendation System 에서도 S-MDP 문제가 formulated 될 수 있는 application 들이 많음
- 그러나 S-MDP 문제는 에 따라서 state 와 action space 가 지수적으로 증가하므로 적절한 policy 를 학습하는 것은 challenging 함
- 기존 vanilla DQN 방식은 이고, 인 간단한 case 에서도 Q-function 을 학습하는데 실패
C) Related Work
-
Combinatorial optimization via RL
-
Parameter Sharing on Neural Network and Analysis
- parameter 를 공유하는 신경망은 여러 데이터 구조 도메인에서 연구되어 왔음 (e.g. graphs, sets)
- 해당 신경망 방식은 메모리와 계산 비용을 크게 줄일 뿐만 아니라 일반적으로 parameter 를 공유하지 않는 신경망보다 좋은 성능을 보임
- permutation equi-invariant networks
-
Preliminary
IS-MDP
- [[Deep Q-Network]]
- DQN의 핵심 아이디어인 target network 그리고 replay buffer를 해당 논문에서도 활용
- RL의 목적은 e expected discounted return을 최대화하는 optimal policy $\pi^{\star}(a\mid s):\mathcal{S}\times\mathcal{A}\mapsto[0,1]$를 학습하는 것
-