Exponentially Weighted (moving) Averages
SGD 보다 좋은 최적화 알고리즘은 Exponentially Weighted Averages (지수 가중치 평균) 개념을 이용한다 (또는 통계에서는 지수이동평균이라 부른다).
가중 이동 평균은 데이터의 이동 평균을 구할 때, 오래된 데이터가 미치는 영향을 지수적으로 감쇠 (exponential decay) 하도록 만드는 평균 계산법이다.
해당 방법을 알아보기 위해 다음과 같은 예시를 살펴보자. 아래 그림은 날짜에 따른 온도 값을 파란색 점으로 나타낸 그래프이다.
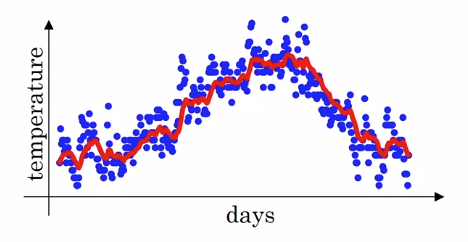
만약, 이 온도들의 경향 값을 확인하고 싶다면, 지수이동평균을 적용할 수 있는데, 어떤 day 에 대한 지수 이동 평균 값 는 다음과 같이 구할 수 있다.
- 여기서 는 의 온도를 의미한다.
- 그리고 는 지수이동평균의 계수다. 이 값에 따라서 평균값을 구하려는 경향의 정도가 달라진다.
위 그림의 빨간색 선은 일 때 계산한 지수이동평균 값이다.
- 일반적으로, 지수이동평균값은 가 인 범위의 평균을 구한것과 비슷하다.
- 즉, 일 경우, 일의 온도 변화 추정치를 계산한 것과 같다.
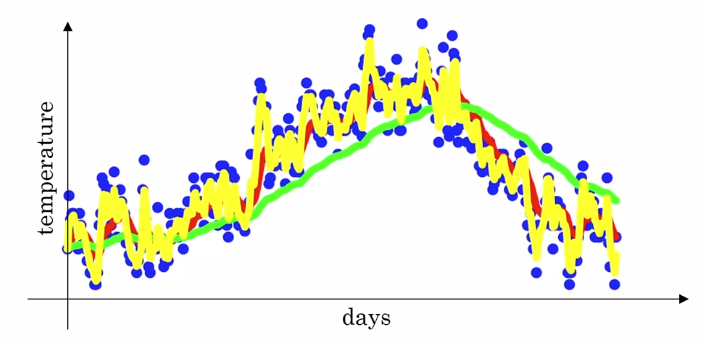
- 일 때 () 는 아래 그림의 초록색 그래프, 일 때 () 는 아래 그림의 노란색 그래프로 지수이동평균을 표현할 수 있다.
A.1) 지수이동평균을 사용하는 이유
평균을 구하는데, 메모리 효율면에서 우수하기 때문이다.
범위 간 평균값을 알기위해서는 단순히 범위내에 존재하는 값들을 포함한 리스트의 평균 값을 계산하면 된다.
- 하지만 이러한 접근법은 많은 메모리가 소요된다.
지수이동평균은 다음과 같이 계산된다.
이러한 계산을 코드로는 쉽게 계산할 수 있다.
v = 0
Repeat {
Get next theta
v = beta * v + (1 - beta) * theta
}
B) Bias Correction
C) Gradient Descent with Momentum
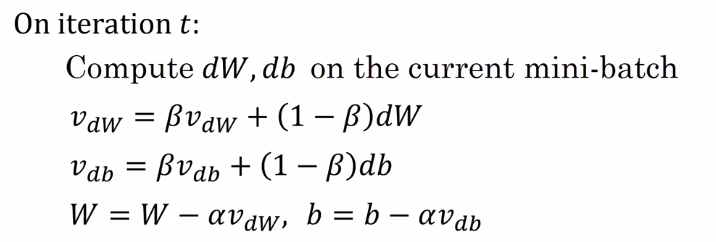
- 는 learning rate
- 는 지수이동평균 계수, 일반적으로 0.9 값을 가짐
- 즉, 최근 10 개의 iteration 의 gradients 평균을 계산하는 것과 비슷하다.
- 일 경우, 일반적인 gradient descent 와 같다 (no momentum).
C.1) 왜 Momentum 이 먹히는 걸까?
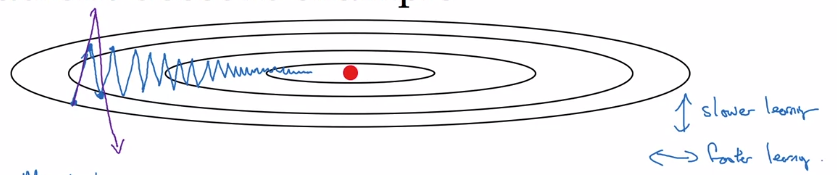
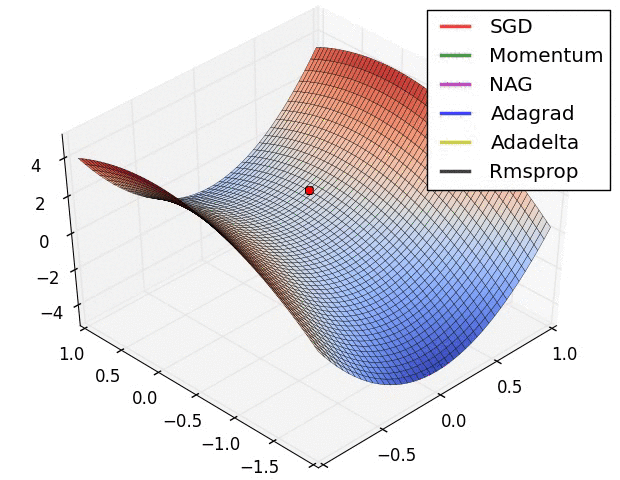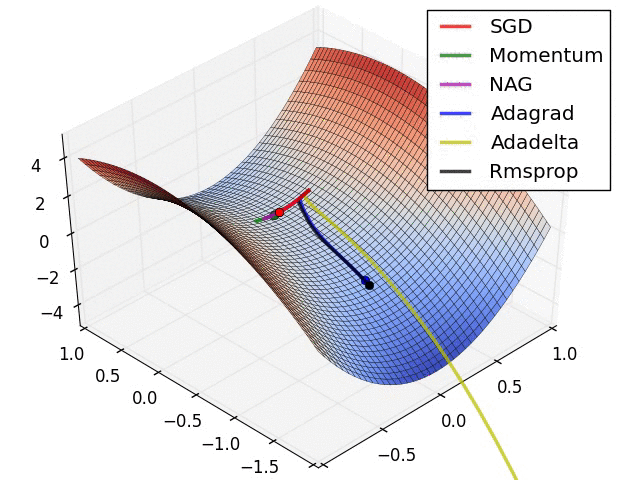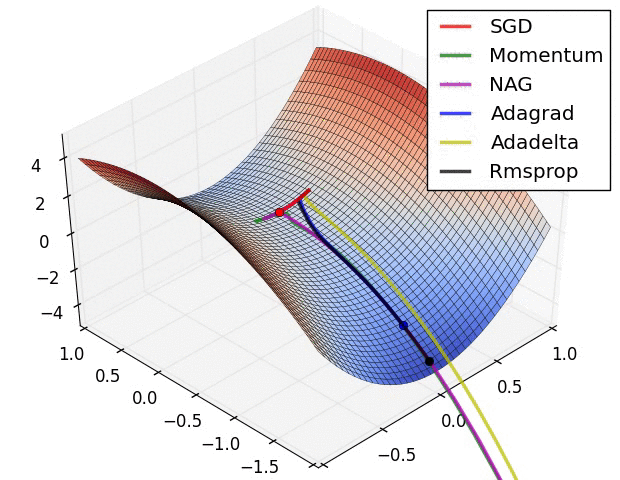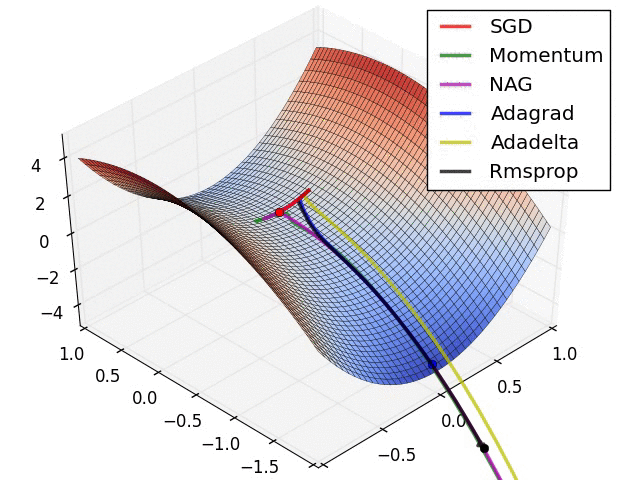
위와같은 cost function 의 contour 가 있다고 가정하자. red point 까지 가기 위해서는 세로는 짧게, 가로는 길게 움직이고 싶을 것이다.
Momentum 은 최근 gradient 의 경향을 알고있다. 즉, 학습하면 할수록 지수이동평균값은 gradient 값의 가로로 증가하고 세로로 짧아지는 경향을 알고있다는 의미가 된다.
결과적으로, gradient 계산에 추가적인 평균 (경향) 값을 넣어줘서, SGD 보다 더 빠르게 red point 에 접근할 수 있게되어 빠른 optimization 을 가능하게 만든다.
간단히 생각하면, 업데이트 하려는 방향으로 관성 또는 가속도를 넣어주고 있는 것이라 생각하면 된다.
D) RMS(Root Mean Square)prop
- ,
momentum 은 gradient 를 통해 학습하려는 방향에 관성값을 추가해주는 역할을 하여 oscillating 을 줄이는 반면, RMSprop 는 oscillating 자체를 줄이려고 한다.

- 위 그림은 가로는 이고, 세로는 일 때의 cost function 이라 가정하자.
- red point 에 빠르게 접근하기 위해서는 가 업데이트 되는 값을 늘리고, 의 업데이트 값을 줄여야한다.
- 학습을 하다보면 oscillating 에 의해 는 적은 값을 가지고, 는 큰 값을 가지는데 (상하로 왔다갔다하므로), RMSprop 는 이러한 값의 역수를 취해서 적은 gradient 는 크게 update, 큰 gradient 는 작게 update 하게 만든다.
- 반대로, 올바르게 잘 학습하고 있다고 생각해보자 (초록색 화살표). 그래도 빠르게 수렴하진 않는다. Why? RMSprop 식에 의해서 gradient 가 조절되기 때문이다 (이제는 가로가 크게 update 하므로 이를 조절함).
간단히 생각하면, 브레이크를 계속 밟고 움직이고 있는거라고 생각하면 된다. 즉, 어떻게 학습하든 천천히 학습하게 만들어서, 큰 learning rate 를 이용해서 학습을 수행해도 조절해준다.
E) Adam
지금까지 배운 모든것을 적용하는 학습 알고리즘이다. 이 학습 알고리즘은 매우 효율적이다.
- 즉, Momentum + RMSprop + Bias correction 이 세개를 다 조합한 알고리즘이다.

- 여기서 는 momentum, 는 RMSprop 에 관련된 variable 이라는 것을 알 수 있다.
- 일반적으로 은 0.9, 그리고 는 0.999, 로 default 값을 가진다.
F) Learning Rate Decay
학습을 수행하면서 epoch 가 증가할수록, 학습률 값을 낮추는 방법이 존재한다.
일반적인 방법은 아래와 같다.
- 는 decay rate 이고, 은 epoch 의 개수, 그리고 는 초기 학습률을 의미한다.
- 학습을 반복할수록 값이 감소한다.
F.1) Exponential Decay
수동적인 방법이다. 거의 사용하지 않는듯하다.
일반적으로 learning rate decay 는 거의 마지막에 고려되는 방법이라고 한다.
G) Local Optima in Neural Networks
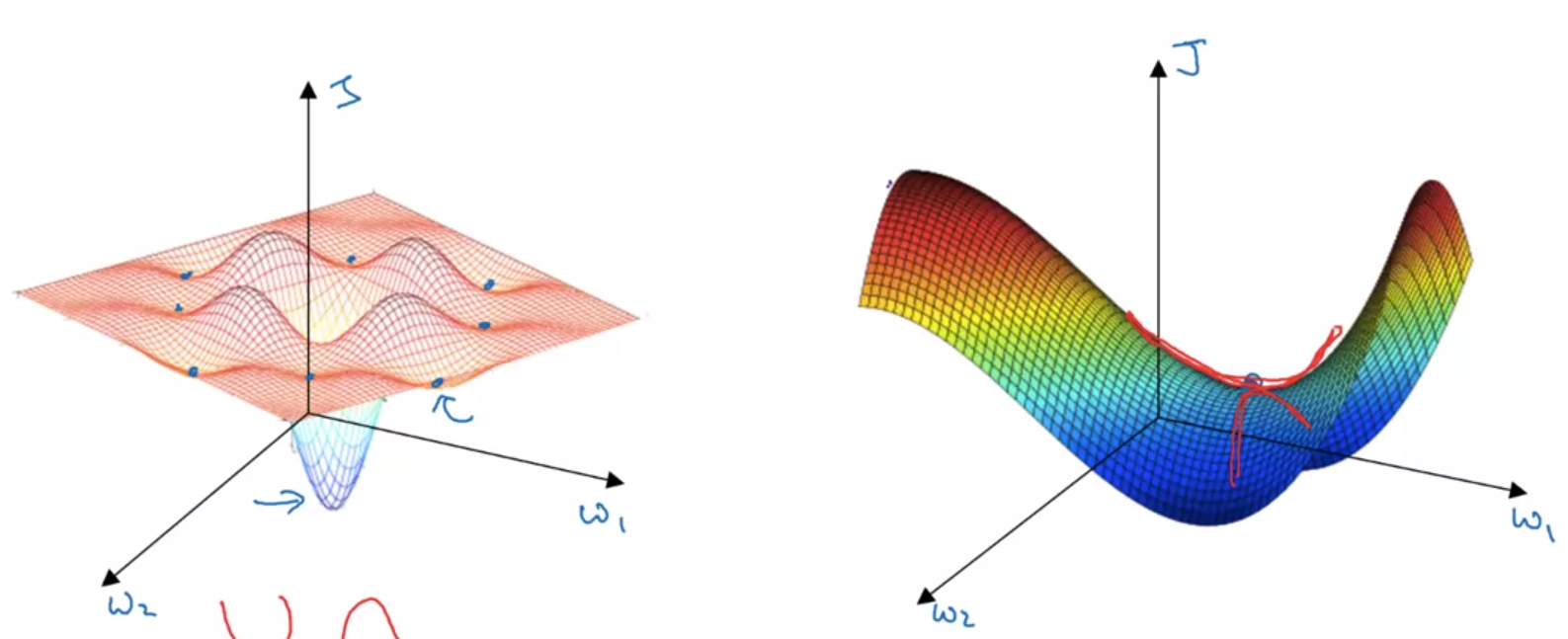
일반적으로 local optima 라면 왼쪽 위 그림의 움푹 파인곳을 생각한다.
그런데 고차원으로 갈 수록, 저런 형태는 많지않다. 오히려 오른쪽 그림과 같은 saddle points(안장점) 가 많다고 한다.
특히, 이 안장점의 문제는 plateaus 형태의 안장점이 문제가 된다.
- plateaus 란, 고지대 느낌으로, gradient 값이 넓은 공간에서 0 인 범위를 의미한다. 이런 곳에 위치한 cost function 은 쉽게 빠져나올 수 없다.
