PEGASUS
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive summarization
In prior work (BERT, GPT-2, etc.), the self-supervised objectives used in pre-training have been somewhat agnostic to the down-stream application in favor of generality; we wondered whether better performance could be achieved if the self-supervised objective more closely mirrored the final task.
We designed a pre-training self-supervised objective (called gap-sentence generation) for Transformer encoder-decoder models to improve fine-tuning performance on abstractive summarization, achieving state-of-the-art results on 12 diverse summarization datasets.
2. A Self-Supervised Objective for Summarization
Our hypothesis is that the closer the pre-training self-supervised objective is to the final down-stream task, the better the fine-tuning performance.
In PEGASUS pre-training, several whole sentences are removed from documents and the model is tasked with recovering them. An example input for pre-training is a document with missing sentences, while the output consists of the missing sentences concatenated together.
The advantage of this self-supervision is that you can create as many examples as there are documents, without any human annotation, which is often the bottleneck in purely supervised systems.
A self-supervised example for PEGASUS during pre-training: The model is trained to output all the masked sentences.
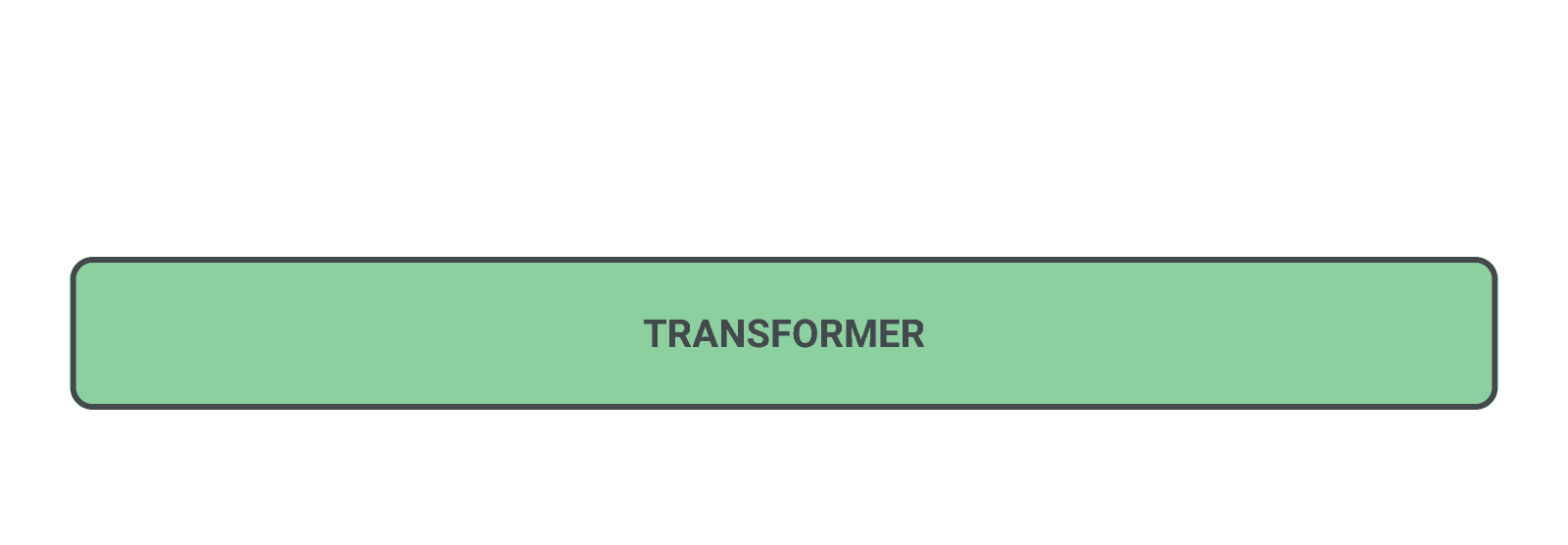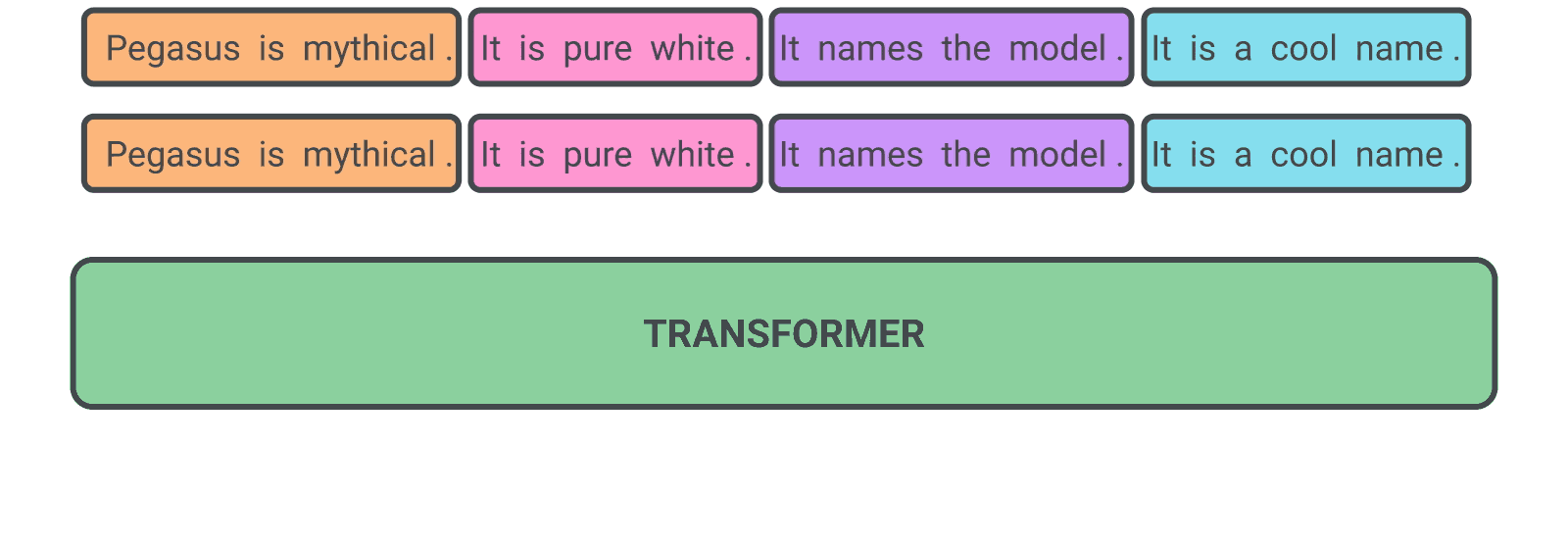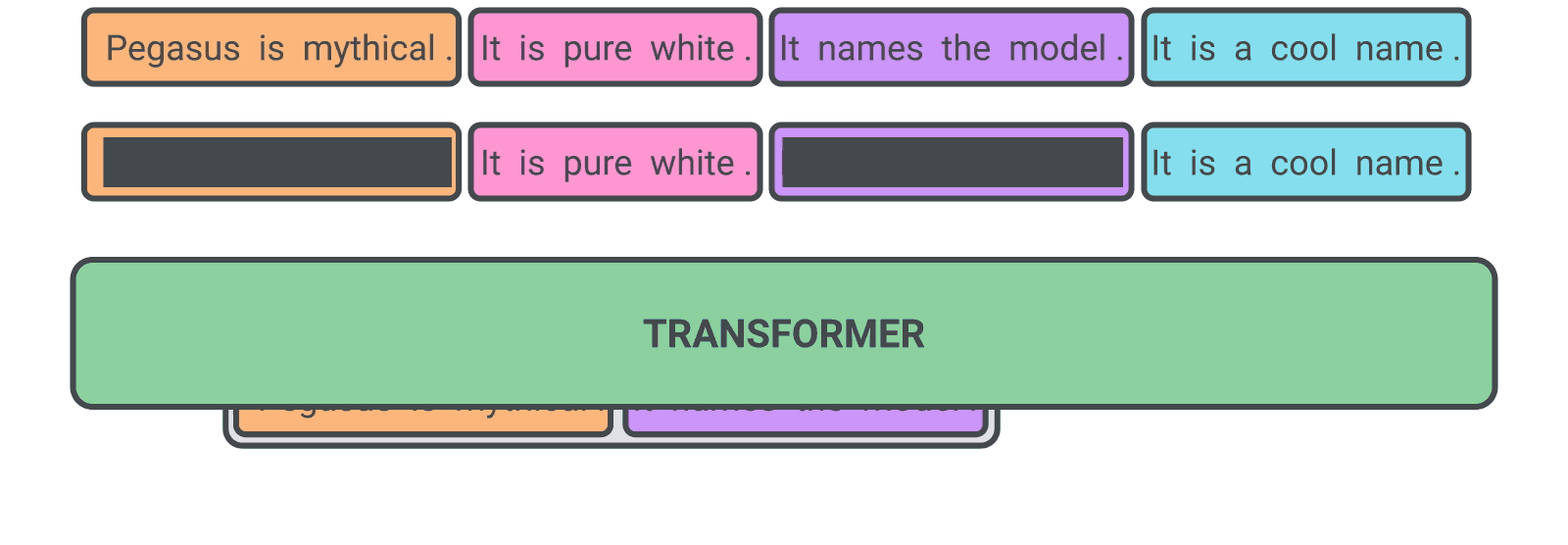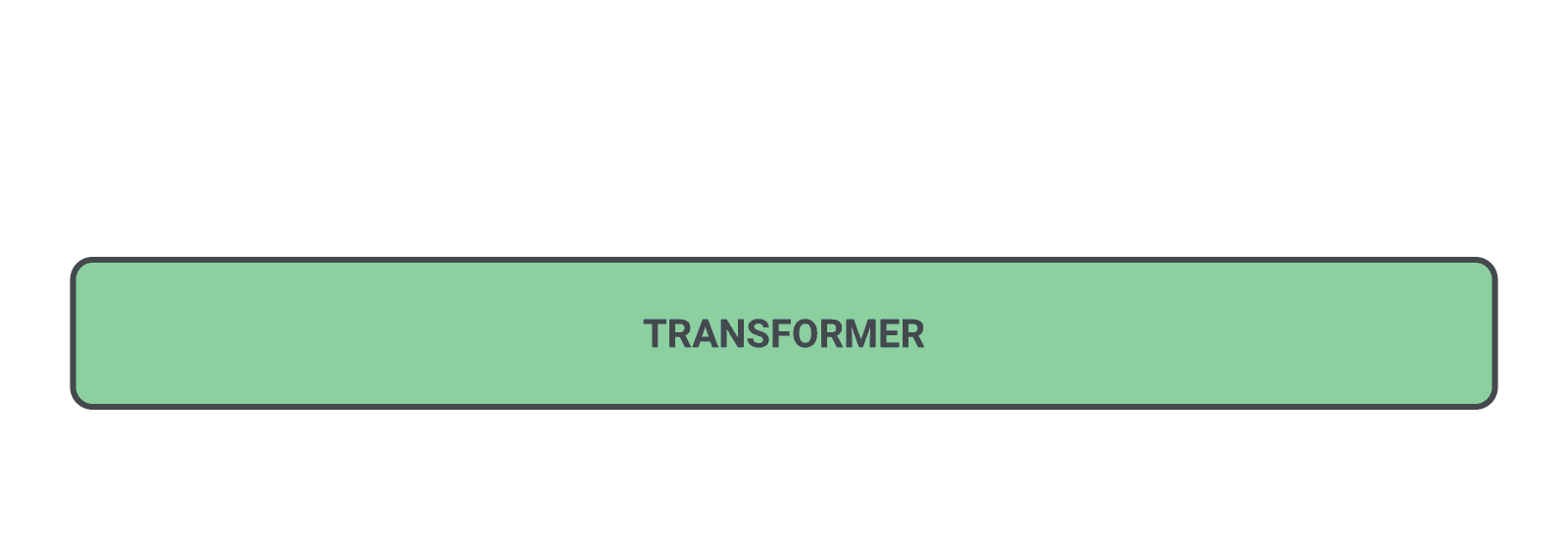
We found that choosing “important” sentences to mask worked best, making the output of self-supervised examples even more similar to a summary. We automatically identified these sentences by finding those that were most similar to the rest of the document according to a metric called ROUGE.
We pre-trained our model on a very large corpus of web-crawled documents, then we fine-tuned the model on 12 public down-stream abstractive summarization datasets, while using only 5% of the number of parameters of T5.
3. Fine-Tuning with Small Numbers of Examples
We were surprised to learn that the model didn’t require numerous examples for fine-tuning to get near state-of-the-art performance.
With only 1000 fine-tuning examples, we were able to perform better in most tasks than a strong baseline (Transformer encoder-decoder) that used the full supervised data, which in some cases had many orders of magnitude more examples. In particular, with the much studied XSum and CNN/Dailymail datasets, the model achieves human-like performance using only 1000 examples.
This suggests large datasets of supervised examples are no longer necessary for summarization, opening up many low-cost use-cases.