문자열 압축
굳이 String 을 만들 필요 없이 개수만 계산하면 된다.
- 숫자 카드2 (백준)
lower_bound또는upper_bound구현- python 으로 시도했는데 TLE 로 실패함. bisect library 를 이용해서 풀음. 한윤정이 이탈리아에 가서 아이스크림을 사먹는데 (백준 https://www.acmicpc.net/problem/2422
핵심은 배열을 활용하는 것
- 금지 조합은 2 가지인데, 선택 조합은 3 가지
- 여기서는 선택 조합 보다는 금지 조합에 대한 배열을 만들고, 선택 조합을 금지 조합에 대입시켜보는 것이 맞다.
- 예) (1,2,3) -> (1,2), (2,3), (1,3) 확인
- python lib 의
itertools.combinations는 시간이 너무 오래걸림 - 다중 for 문으로 푸는것이 훨씬 빠름 (약 3 배정도)
- bfs 로 해결하는 것인데, 테스트 케이스가 부족하여서 조금 쉬운 문제가 되버림 (하지만 난 못풀었음)
- 핵심은 memoization도 적절히 섞어줘서 가지치기를 진행하는 것
- python에서의 상하좌우 이동은 tuple로 해결하는 것이 좋다는 것을 깨달음
- python에서의 queue는 list 보다는 collections의 deque를 사용하는 것이 좋다는 것을 깨달음
- 자와 각도기
- BFS 보다 DFS 를 사용하는게 빠른 문제 자는 쓰지 않음
- 각도의 개념을 이해하는게 중요했음
- 사탕 게임
- 구현은 어렵지 않았는데, 경우의 수가 핵심이었다.
- 사탕끼리 바꾼 행,열 만 고려해야되는게 아니라, 이미 바꾼 상태에서도 얻을 수 있는 최대값이 다른 어디엔가 존재한다.
- 구현은 어렵지 않았는데, 경우의 수가 핵심이었다.
- Maximum Sum Obtained of Any Permutation (leetcode)
- 주어진 여러개의 구간들 중 가장 많이 중첩된 순위를 한꺼번에 계산하는법
- 핵심 : 시작 구간에는 1 그리고 마지막 구간 + 1 에는 1 을 놓고 (더하고) 굴린다..!
- 주어진 여러개의 구간들 중 가장 많이 중첩된 순위를 한꺼번에 계산하는법
- Split a String Into the Max Number of Unique Substrings
- 풀긴 풀었는데 재귀로 풀었다가 TLE 나버린 case
- Backtracking 솔루션을 보니 훨씬 깔끔했다. 다만 이해하긴 좀 어려웠음.
- 풀긴 풀었는데 재귀로 풀었다가 TLE 나버린 case
- 징검다리 건너기
- 두가지 해결 방법이 있는 문제
- Sliding window Maximum 활용 (나는 이 방법을 썼다.. 이해하는데 오래걸렸다)
- 이진 탐색하면서 일일이 check
- 두가지 해결 방법이 있는 문제
- 토마토
- 문제는 잘 풀었는데, python 의 deque 와 array 의 loop 에 관련하여 할말이 있다.
- for i in range(len(deque)) 가 while len(deque) >= 1 보다 확실하게 현재 deque 에 포함된 모든 내용을 확인한다.
- while 의 경우, while 문 내에서 deque 값이 추가되면 그 값도 꺼내지게 된다.
- 2 차원 array 의 loop 의 경우, 특정 값 t 가 존재하는지 확인하고 싶다면 다음처럼 하면 좋다.for i in array: if t in i: print(‘exist!’)
- for i in range(len(deque)) 가 while len(deque) >= 1 보다 확실하게 현재 deque 에 포함된 모든 내용을 확인한다.
- 문제는 잘 풀었는데, python 의 deque 와 array 의 loop 에 관련하여 할말이 있다.
- Majority Element II
- 핵심: 크기가 n 인 배열 중 특정 원소의 개수가 ⌊n/2⌋ 보다 많은 원소는 반드시 한개만 존재한다.
- 그럼 ⌊n/3⌋ 의 경우는 ?
- 핵심: 크기가 n 인 배열 중 특정 원소의 개수가 ⌊n/2⌋ 보다 많은 원소는 반드시 한개만 존재한다.
- Gas Station
- 움직이면서 자원을 충전 그리고 소모를 반복하는 문제
- 두 가지만 파악하면 되었다.
- 움직이는 사이에 문제가 없음을 확인 모든 자원 >= 소모 자원
- (1) 이 확인되었다면, 반드시 정답은 존재 -> 0~n 방향으로 자원 충전 및 소모 진행하면서 시작 위치 찾기
- 두 가지만 파악하면 되었다.
- 움직이면서 자원을 충전 그리고 소모를 반복하는 문제
- 부분수열의 합
- combination 을 구하는 방식이 잘못되었다.
- 부분 수열에서 combination 구하는 것은 sliding 방식으로 구해야 한다.(1,2,3) -> (1,2), (2,3), (1,2,3)
- combination 을 구하는 방식이 잘못되었다.
- 욕심쟁이 판다
- DFS (또는 bfs) + memoization 사용 문제
- memoization 업데이트 방식이 내가 경험한 것과 다르다.
- 주워 들음) dp 는 한번 정하면 일반적으로 절대 수정하면 안되는 것을 원칙으로 하자.
- 이 문제의 경우, memoization 의 이유 말고도, 이미 방문한 곳은 절대 방문하지 않는다.. 왜? 판다의 특성 때문에
- 다시 한번 살펴보는게 좋을 것 같다.
- DFS (또는 bfs) + memoization 사용 문제
- 골드바흐의 추측
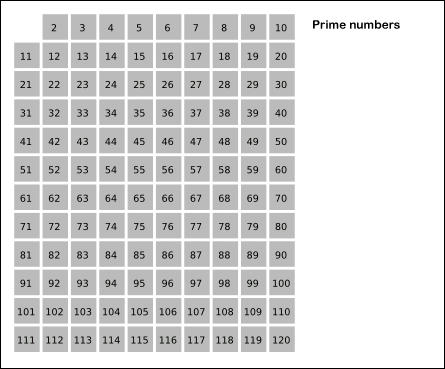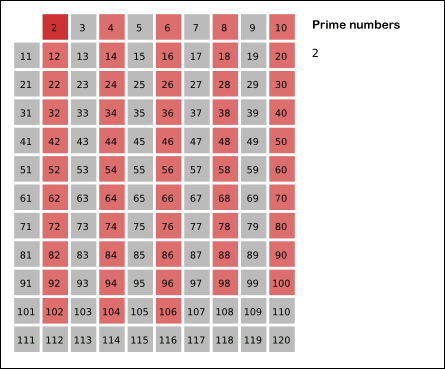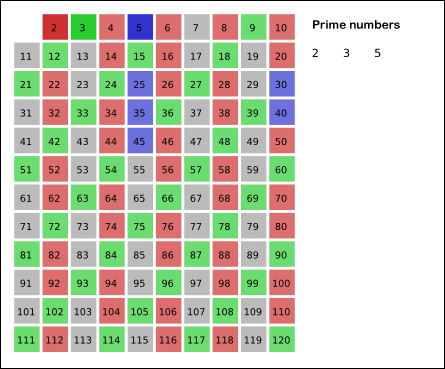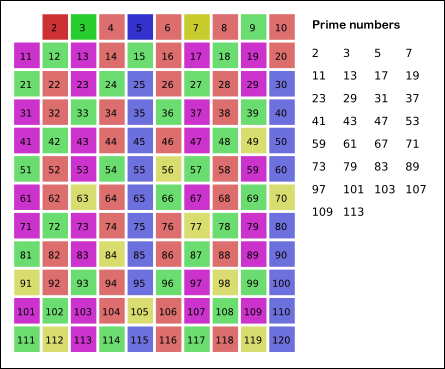
- 에라스토테네스의 채를 이용해 소수를 빠르게 구하는 방법을 터득하자.
- 참고 : math.sqrt(m) 대신에 m ** 0.5 를 사용하면 편리하다.
- ABCDE
- DFS 에서 굳이 2d 배열로 연결되있지 않은 vertices 까지 체크할 필요가 없다.
- set() 또는 list() 가 들어간 2d 배열을 만들어서 연결되있는 것만 집어넣어 주자.
- 그리고, dfs 에서 이미 방문한 것을 확인할 수 있는 방법은 set() 말고 bit manipulation 이 있다.
- 우선 방문한 노드가 i 라고 가정하면, z += (1 << i) 로 z 에 저장
- 이후 어떤 노드 k 가 이미 방문했는지 확인하고 싶다면, (1 << k) & z == 1 로 확인한다.
- DFS 에서 굳이 2d 배열로 연결되있지 않은 vertices 까지 체크할 필요가 없다.
- 숨바꼭질3
- 가중치 (cost) 가 다른 문제에서의 BFS 사용: 이 문제는 cost 가 다르다.
- (순간 이동 cost: 0, 움직임 cost: 1)
- 처리 시간이 길어지는 것을 막기 위해, 최대한 빠른걸 먼저 해결해야 한다.
- 이를 위해 그냥 queue 대신 priorityQueue 를 사용한다.
- 또한 문제 input 에 대한 여러 경우의 수를 생각해보는 것을 잊지 말자.
- 가중치 (cost) 가 다른 문제에서의 BFS 사용: 이 문제는 cost 가 다르다.
- 이분 그래프
- 이분 그래프의 정의
- 그래프의 정점의 집합을 둘로 분할하여, 각 집합에 속한 정점끼리는 서로 인접하지 않도록 분할할 수 있을 때, 그러한 그래프를 특별히 이분 그래프 (Bipartite Graph) 라 부른다.
- 인접한 정점끼리 서로 다른 색으로 칠해서 모든 정점을 두 가지 색으로만 칠할 수 있는 그래프
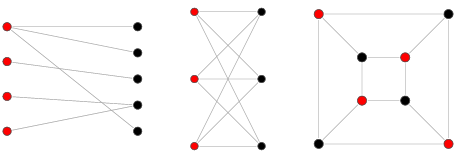
- 각 정점에 대해서 BFS 또는 DFS 사용
- BFS 또는 DFS 를 사용하면서 특정 정점에 인접한 정점들은 특정 정점과 반대의 색을 칠한다.
- 칠하는 도중, 만약 이미 칠해진 정점을 발견한 경우, 그 정점이 인접한 정점과 같은 색이라면 이분 그래프가 아니다.
- 이분 그래프의 정의
- Largest Number
- 서로 붙여보면서 정렬하는 것이 핵심. 답은 정말 간단한데 너무 창의적이라 생각을 못했다.
- Two Sum
- 주어진 배열의 두 숫자를 더해서 목적하는 값을 찾는 문제
- O(n^2) 은 너무 쉽고, O(n) 으로 풀려면 hashtable 을 사용해야 했다.
- hashtable 에 숫자를 넣으면서 동시에 체크하는 방법이 빠름
- 주어진 배열의 두 숫자를 더해서 목적하는 값을 찾는 문제
- Maximum Number of Achievable Transfer Requests
- 최대/최소를 구하는 문제의 constraints 가 작은 경우 (1<= n<= 20, 1<= request.length <=16), 모든 조합을 고려해볼 것
- itertools.combinations 사용
- 최대/최소를 구하는 문제의 constraints 가 작은 경우 (1<= n<= 20, 1<= request.length <=16), 모든 조합을 고려해볼 것
- Pokémon Army (easy version)
- Local minima & local maxima 를 구하는 문제
- 배열 a 의 local minima 란, i 번째 원소 a_i 가 a_(i-1) >= a_i && a_i <= a_(i+1) 를 만족하는 경우 (구덩이, valley)
- local maxima 는 그 반대, 즉, a_(i-1) <= a_i && a_i >= a_(i+1) (동산, peak)
- 배열에서 최대의 합을 구하는 문제가 있다면, 그 값들을 시각화 하는 것도 문제를 파악하는데 도움이 된다.
- 만약 + 로 시작해서 -, +, -, + 이런 순으로 원소들의 최대 합을 구하는 문제가 있다면, 반드시 정답은 홀수 번 합이다 (e.g. + - +).
- Local minima & local maxima 를 구하는 문제
- Subarray Product Less Than K
- Sliding Window를 활용 해서 해결하는 문제
- [1, 2, 3] 이 가질 수 있는 총 subarray 가 a 개인 경우,[1, 2, 3, 4] 의 총 subarray 는 a + end - start = a + 4 - 0 가 된다.
- 여기서 start 는 1 의 index, 그리고 end 는 4 의 index + 1
- 이러한 특징을 활용하여 array 에서 window 를 놓고 sliding 시키면서 product 값 그리고 subarray 개수를 계산하면 됨
- [1, 2, 3] 이 가질 수 있는 총 subarray 가 a 개인 경우,[1, 2, 3, 4] 의 총 subarray 는 a + end - start = a + 4 - 0 가 된다.
- Sliding Window를 활용 해서 해결하는 문제
- 스타트와 링크
- 문제 자체는 쉬웠는데, 짝수 n 명을 반/반 두 팀으로 나누는 조합에 대하여 할말이 있다.
- python 의 itertools.combinations() 에서 생성된 조합을 절반으로 나누면 위 조합이 만들어진다.
- 예를 들어 n=4 명의 조합은 (0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3) 인데, 이를 절반으로 나누면 정확히 반/반 조합이다.
- 즉, A = (0, 1), (0, 2), (0, 3) / B = (1, 2), (1, 3), (2, 3) 으로 나누고, A[i] 는 B[n-i-1] 와 정확히 매칭된다.
- python 의 itertools.combinations() 에서 생성된 조합을 절반으로 나누면 위 조합이 만들어진다.
- 문제 자체는 쉬웠는데, 짝수 n 명을 반/반 두 팀으로 나누는 조합에 대하여 할말이 있다.
- 퍼즐
- 조그만 2 차원 배열을 쉽게 다루는 방법
- 3x3 배열인 경우 (0,0) 부터 (2,2) 까지 각 원소들을 하나의 문자열로 표현한다. (e.g.123456780)
- 조그만 2 차원 배열을 쉽게 다루는 방법
- First Missing Positive
- 문제는 쉽지만, 더욱 효율적으로 풀 수 있는 방법이 존재한다.
- 길이가 n 인 배열 a 에 포함되지 않은 가장 작은 양수는 반드시 1~(n+1) 사이의 값이다.
- 그리고, a 의 원소의 크기가 1 이상 n 미만이라고 할 때, 해당 원소의 등장 횟수를 a 자체에서 셀 수 있다.
- a 의 원소를 인덱스로 여기고 길이를 더해준다 ->
a[a[i]%n] += n - 이후
a[i] // n == 0인 경우, 그 i 값은 a 에 원래 존재하지 않았던 원소라는 것을 체크할 수 있다 (출처).
- a 의 원소를 인덱스로 여기고 길이를 더해준다 ->
- 문제는 쉽지만, 더욱 효율적으로 풀 수 있는 방법이 존재한다.
- K-diff Pairs in an Array
- Counter 를 활용하는 문제: 리스트가 주어졌을 때, b-a == k, a <= b 를 만족하는 쌍 (a, b) 찾기
- 리스트의 모든 값들을 Counter 에 넣은 다음, Counter[b-k] 가 하나라도 count 되었다면, 그 쌍 (a, b) 는 리스트에 존재함
- Counter 를 활용하는 문제: 리스트가 주어졌을 때, b-a == k, a <= b 를 만족하는 쌍 (a, b) 찾기
- Rotate List
- Rotate 하는 list 를 만들기
- 우선 list 를 circular 하게 만들자 (꼬리가 머리를 가리키는 식으로).
- 그리고, 그 꼬리에서 다시 len(list) - (k % len(list)) 만큼 이동한 후 (k 는 list 이동 횟수), 도착한 list 의 노드가 꼬리가 된다.
- 그 노드 (A) 를 꼬리로 만드는 방법: head = A->next 그리고, A->next = None
- Rotate 하는 list 를 만들기
- Count Subtrees With Max Distance Between Cities
- Tree 에서 가능한 모든 Subtree 를 찾는 방법: 가능한 모든 vertices 의 조합을 찾아내서, 그것이 tree 인지 확인
- 가능한 모든 vertices 조합을 찾는 방법: combinations 또는 bitmasking 사용
- Tree 인지 확인하는 방법: BFS 또는 DFS 로 조합에 존재하는 정점 간 거리를 구하고, 만약 구할 수 없다면 tree 가 아님
- BFS 방법 (다익스트라 응용): 초기 거리를 무한으로 설정 (시작 노드만 0), queue 를 이용해서 정점을 넣고 빼고, 이웃 정점 거리 = 이전 정점 거리 + 1
- BFS 로 풀어보는 것을 권장
- Tree 에서 가능한 모든 Subtree 를 찾는 방법: 가능한 모든 vertices 의 조합을 찾아내서, 그것이 tree 인지 확인
- 불!
- 예외 케이스를 기억하자: 1) 불은 한개가 아닐 수 있다, 2) 미로의 크기가 최소인 경우 (1 by 1)
- 팰린드롬 만들기
- AAABB 로 팬린드롬 만들 때 -> ABABA 가 BAAAB 보다 사전 순 먼저임
- 위의 경우, 홀수나 짝수 상관없이 알파벳 순으로 절반씩 붙여주고, 가운데 하나만 홀수 알파벳을 붙인다 (AB + A + BA)
- AAABB 로 팬린드롬 만들 때 -> ABABA 가 BAAAB 보다 사전 순 먼저임
- Sort List
- Merge Sort 를 활용하여 linked list 정렬하기
- Top Down 방식과 Bottom Up 방식이 존재함
- Top Down: O(nlog(n)) 의 Time complexity 그리고 O(log(n)) 의 Space complexity
- O(log(n)) 은 recursive call stack 의 추가 공간 요구 때문에 발생 (트리의 높이라고 생각하면 됨)
- Linked list 의 중간 node 찾는 법: head 에서부터 하나는 1 node, 다른 하나는 2 node 씩 움직이는 pointer 를 활용
- Merge 방법: dummy head 를 만들고, 합치려는 두 list 의 node 중, 작은 값부터 순서대로 dummy 에 엮어줌
- Bottom Up: O(nlog(n)) 의 Time complexity 그리고 O(1) 의 Space complexity
- 아직 자세히 확인하지 못함
- Top Down: O(nlog(n)) 의 Time complexity 그리고 O(log(n)) 의 Space complexity
- Rotate Array
- Given an array, rotate the array to the right by k step
- O(n) 의 Time complexity 그리고 O(1) 의 Space complexity 로 rorate 하기
- 예시로 이해하는 것이 빠르다. 배열 A: [1,2,3,4,5] -> [4,5,1,2,3] (When k=2)
- 일단 A 를 뒤집어보면: [5,4,3,2,1].. 패턴이 보이는가? [/5,4/3,2,1/]: /로 나눠진 부분을 뒤집어 주면된다.
- 132 Pattern (Keyword: Stack)
- n 개의 원소를 가진 nums 배열이 i < j < k and nums[i] < nums[k] < nums[j] 를 만족하는지 확인하는 문제
- 핵심은 i < j 면서 nums[i] < nums[j] 를 만족하는 j 를 먼저 찾고, 그 다음 j 를 중심으로 조건을 만족하는 k 를 찾는다.
- j 를 0~len(nums)-1 까지 움직이면서 i_nums[j] 을 update
- i_nums[j] 이란, nums 의 j 번째까지의 원소 중 가장 작은 원소를 의미: 이것이 i 가 됨
- 만약, i_nums[j] < nums[j] 라면, 반드시 i < j 와 nums[i] < nums[j] 를 만족하는 j 가 있다는 뜻임
- 그리고 j + 1 이후부터 조건을 만족하는 k 를 찾으면 된다.
- j 를 0~len(nums)-1 까지 움직이면서 i_nums[j] 을 update
- 위 방법은 O(n^2) 방법이다. 하지만, binary search 를 이용하는 O(nlog(n)) 그리고 stack 을 이용하는 O(n) 방법이 존재함
- 더 좋은 방법은 이후에…
- Trapping Rain Water
- 일련의 양의 정수 높이가 존재하는 n 개의 블럭들이 주어지고, 블럭에 물을 부었을 때 얼마나 많은 물이 블럭에 잠기는지 세는 문제
- 핵심: i 번째 블럭이 보유할 수 있는 물의 높이 H 를 다음과 같이 구할 수 있다.
- 0
i 번째 블럭 중 가장 높은 높이 A, in-1 번째 블럭 중 가장 높은 높이 B - H = min(A,B) - h (h 는 i 번째 블럭의 높이)
- 물론, min(A,B) > h 의 경우만 위 식이 성립, 아니면 H = 0 임
- 시간 복잡도를 줄이기 위해 배열 left 와 right 를 사용 (left[i] 는 A 그리고 right[i] 는 B 를 저장하는 배열)
- 0
- Maximize Distance to Closest Person
- 풀이 방법이 비슷한 문제 (left, right 배열 활용)
- 배열들을 사용하지 않고 공간 복잡도를 줄이는 방법: 어떤 좌석 i 에서 가장 가까운 사람과의 거리는 min(i - prev, future - i) 임
- prev 는 i 에서부터 가장 가까운 왼쪽 사람이 앉은 자리, future 는 i 에서부터 가장 가까운 오른쪽 사람이 앉은 자리
- future 를 위해 python 에서 generator 를 활용할 수 있음
- 가운데를 말해요
- min heap & max heap 두 개를 동시에 사용하는 문제
- 전체 배열 A 중에서 min heap 은 내림차순 담당, max heap 은 오름차순 담당
- A = [1,2,3,4,5] 의 경우 min heap: [5,4], max heap:[1,2,3]
- 정렬된 배열의 중간값 (median) 을 출력해야 하므로, 두개의 heap 길이를 비슷하게 유지한다.
- max heap 에 우선적으로 값을 넣고, 1 개 이상 길이가 차이날 경우 min heap 에 넣는다.
- max heap 의 root 값이 배열의 median 값이라고 정하자.
- 이 경우, 매번 두 heap 중 하나에 값을 넣을때마다, max heap 의 root 값이 min heap 의 root 값보다 크면 교환한다.
- Why?
- 각 heap 의 오름차순과 내림차순을 유지해야하므로
- 배열의 길이가 짝수일 경우, median 은 중간에 있는 두 수 중에서 작은 수이므로
- min heap & max heap 두 개를 동시에 사용하는 문제
- Champagne-tower
- 샴페인을 부워서 특정 잔에 얼마나 많은 물이 남아있는지 알아내는 문제
- 잔에 물을 한컵씩 붓는다고 생각하지 말고, 한번에 다 따라버렸을 때 어떻게 흘러가는지 파악하는게 핵심이다.
- 트리의 지름
- 트리의 지름이란, 트리에서 임의의 두 점 사이의 거리 중 가장 긴 것을 말한다.
- 구하는 방법: 임의의 노드 A 에서 가장 거리가 먼 노드 B 를 찾는다. 다시, B 에서 거리가 가장 먼 노드 C 를 찾으면, B 와 C 의 거리가 트리의 지름이 된다.
- Minimum Height Trees
- tree-like graph 에서 가장 짧은 높이를 가진 tree 의 root node 를 찾는 문제
- 트리의 지름에 가장 가운데 존재하는 노드 (들) 을 찾으면 된다.
- 이러한 노드들을 centroids 라는 별명으로 부르는데, tree-like graph 에서 centroids 는 반드시 2 개 이하임이 증명되어있다.
- 푸는 방법은 두 가지: 1) 트리의 지름을 구하면서 지름을 이루는 노드 경로 찾기 2) Topology sort
- Topology sort 의 경우, BFS 로 해결한다. 즉, Graph 의 leaf node 들을 모두 큐에 넣고, 안으로 조금씩 들어가면서 최종적으로 두 노드만 남을 때까지 방문한 노드들을 Graph 에서 제외시킨다. 그리고 남은 두 노드가 centroids 가 된다.
- 불량 사용자
- ‘abcd’와 ‘ab*d’가 일치하는지 확인하는 법
- ‘*’ 을 제외한 나머지 문자 (‘ab’ 그리고 ‘d’) 가 동일할 경우
- ‘’ 을 제외한 나머지 문자 길이 + ‘’에 해당하는 길이가 같다면, 두 문자열이 동일하다고 판단한다.
- ‘abcd’와 ‘ab*d’가 일치하는지 확인하는 법
- Check Array Formation Through Concatenation
- list 간 + 로 합칠 수 있다
- [1,2] + [3,4] = [1,2,3,4]
- dict 의 get 함수가 유용하다
- mp= {1: [5]} a = mp.get(1, []) # a = [5] b = mp.get(2, []) # b = []
- list 간 + 로 합칠 수 있다
- Convert Binary Number in a Linked List to Integer
- linked list 에 포함된 값을 정수로 바꾸는 문제
- << 와 |를 활용하면 공간 복잡도 O(1) 로 해결할 수 있다.
- 기둥과 보 설치
- 적은 수에 대한 조합을 고를 땐, 객기 부리지 말고 O(n^2) 으로 단순히 생각하자.
- Decode String
- 대괄호 내 알파벳을 배수로 만드는 문제 (e.x. “3[a]2[bc]” -> aaabcbc)
- DFS 랑 stack 을 사용하는 방법이 존재하는데, stack을 사용하는 방법 도 괜찮은 것 같다.
- House Robber III
- binary Tree 로 이루어진 집 구조; 부모 노드의 값을 가지면, 자식 노드의 값을 못가지는 규칙에서, 최대 가질 수 있는 값 찾기
- DFS 에서 시간초과 발생 시, memoization 으로 해결할 수 있는지 확인
- Hashmap(dict) 에서 class instance 도 hashing 이 가능하다 (=key 로 활용할 수 있음).
- Memoization 을 굳이 하나의 자료구조로 수행할 필요는 없음. 두 개 이상으로 사용해도 됨.
- DFS 로 안될 것 같으면, DP 도 고려할 수 있음.
- 솔루션 이 꽤 잘되어 있음
- 계산기 문제
- stack 을 활용한다 (우선순위 연산자 (
'*','/') 가 나오면 stack 에서 pop, 아니면 (‘+’,‘-’) push)). - 항상 ‘+’ 가 있다고 생각하고 계산한다. (e.g. 1+2+3 -> +1+2+3), 시작 연산자가 ‘+’.
- stack 을 활용한다 (우선순위 연산자 (
- Longest Substring with At Least K Repeating Characters
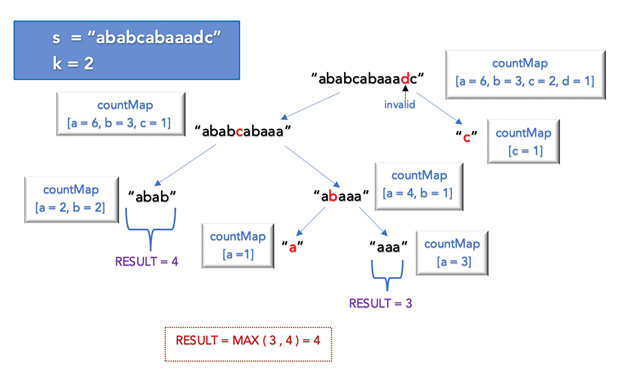
- Divide Conquer 또는 Sliding Window 를 사용하여 해결하는 문제
- Divide Conquer
- 전체 문자열의 알파벳 중 k 이상 존재하지 않는 알파벳을 발견한 경우, 해당 알파벳의 index 기준으로 문자열을 반으로 나눠서 반복
- 만약, 문자열의 모든 알파벳이 k 이상 존재한다면, 그 길이들 중 최대값이 정답
- Sliding Window: 분할 정복보다 좀 더 복잡한 솔루션 (아직 이걸로 풀어보지 못함)
- Window 를 움직이는 기준은 문자열 s 의 unique 문자 개수 0 < curr_unqiue < len(set(s))
- 현재 Window 에 포함된 unique 문자열 개수가 curr_unqiue 보다 낮을 경우 Window 를 오른쪽으로 확장, 그 반대의 경우 왼쪽으로 축소
- 윈도우를 옮기면서, 윈도우에 포함된 문자열의 모든 알파벳이 k 이상 존재하면, 그 길이들 중 최대값이 정답
- Can Place Flowers
- 배열에 존재하는 양 원소들이 서로 1 이 아닐 경우 count 하는 문제
- 예시) a = [1,0,0,0,1] 의 경우 a[2] 만 count 된다.
- 체크 방법
- if a[i] 0 and (i 0 or a[i - 1] 0) and (i len(a) - 1 or a[i + 1] == 0):
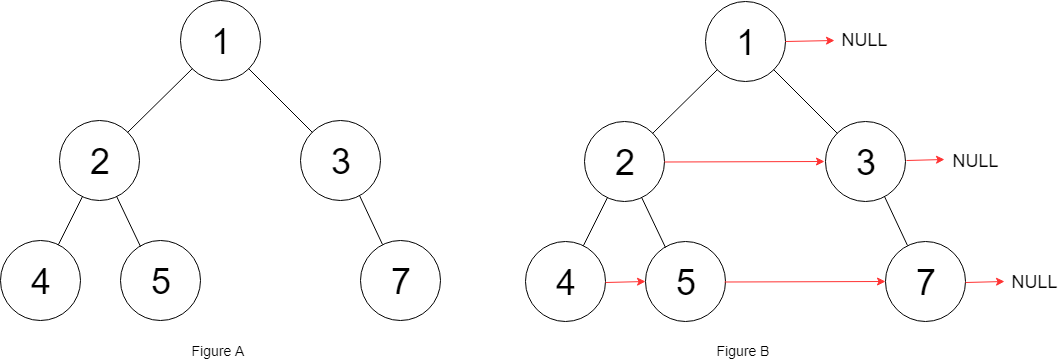
- Populating Next Right Pointers in Each Node II
- 이진 트리의 노드 중
- Generate Random Point in a Circle
- 원의 x, y 좌표 그리고 반지름 r 이 주어졌을 때, 원 안에 랜덤한 점을 균등하게 샘플링하는 문제
- 중요한 점은 균등하게 샘플링을 해야한다는 점이다: 원의 둘레는 반지름이 비례하므로, uniform sampling 을 위해서는 중심에서 넓어질수록 더 많은 점들이 sampling 되어야 한다.
- Inverse transform sampling 을 활용한다
- First we create a cumulative distribution function (CDF for short)
- Get inverse of CDF ()
- The resulting function can be applied to a random value between 0 and 1